You might also like
- A Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"From EverandA Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"Rating: 2.5 out of 5 stars2.5/5 (2)
- MATLAB Fundamentals for Computer-Aided ManufacturingDocument47 pagesMATLAB Fundamentals for Computer-Aided ManufacturingAyub PadaniaNo ratings yet
- LAB 1: Intro To Matlab: 1.1. Work Space ManagementDocument4 pagesLAB 1: Intro To Matlab: 1.1. Work Space ManagementChampion LodhiNo ratings yet
- LAB 03: MATLAB Graphics: Graph2d Graph3d Specgraph GraphicsDocument16 pagesLAB 03: MATLAB Graphics: Graph2d Graph3d Specgraph GraphicsMuhammad Massab KhanNo ratings yet
- 04 Scipy and ScikitDocument24 pages04 Scipy and Scikitgiordano manciniNo ratings yet
- Matlab IntroDocument19 pagesMatlab IntroSunilkumar ReddyNo ratings yet
- Curve Interpolation Newton's Divided Differences Lagrange PolynomialsDocument4 pagesCurve Interpolation Newton's Divided Differences Lagrange PolynomialsAhmet GelisliNo ratings yet
- Sturm-Liouville Eigenvalue ProblemsDocument7 pagesSturm-Liouville Eigenvalue Problemshammoudeh13No ratings yet
- Functions in MATLAB: X 2.75 y X 2 + 5 X + 7 y 2.8313e+001Document21 pagesFunctions in MATLAB: X 2.75 y X 2 + 5 X + 7 y 2.8313e+001Rafflesia KhanNo ratings yet
- Apm2613 203 0 2022Document9 pagesApm2613 203 0 2022Darrel van OnselenNo ratings yet
- Matlab Intro11.12.08 SinaDocument26 pagesMatlab Intro11.12.08 SinaBernard KendaNo ratings yet
- Course: DD2427 - Exercise Class 1: Exercise 1 Motivation For The Linear NeuronDocument5 pagesCourse: DD2427 - Exercise Class 1: Exercise 1 Motivation For The Linear Neuronscribdtvu5No ratings yet
- Getting Help: Example: Look For A Function To Take The Inverse of A Matrix. Try Commands "HelpDocument24 pagesGetting Help: Example: Look For A Function To Take The Inverse of A Matrix. Try Commands "Helpsherry mughalNo ratings yet
- Lecture Notes Interpolation and Data FittingDocument16 pagesLecture Notes Interpolation and Data FittingAmbreen KhanNo ratings yet
- Matlab Notes for Differential EquationsDocument14 pagesMatlab Notes for Differential EquationsShelly ChandlerNo ratings yet
- BME1901 - Introductory Computer Sciences Laboratory Handout - 1 ObjectivesDocument6 pagesBME1901 - Introductory Computer Sciences Laboratory Handout - 1 ObjectivesfalxaNo ratings yet
- LE3 Review Questions Math 21: Elementary Analysis 1Document5 pagesLE3 Review Questions Math 21: Elementary Analysis 1tqlittonNo ratings yet
- Line Integral and Work Done Using MATLABDocument4 pagesLine Integral and Work Done Using MATLABdNo ratings yet
- Mate Matic ADocument154 pagesMate Matic ADarnel Izekial HVNo ratings yet
- Lab 00 IntroMATLAB2 PDFDocument11 pagesLab 00 IntroMATLAB2 PDF'Jph Flores BmxNo ratings yet
- Matlab Notes For Calculus 2: Lia VasDocument12 pagesMatlab Notes For Calculus 2: Lia VasjojonNo ratings yet
- 5116 NotesDocument7 pages5116 NotesKoh JZNo ratings yet
- Augmented Matrix & Modeling ProblemsDocument14 pagesAugmented Matrix & Modeling ProblemsAwexomeNo ratings yet
- To Graph A Relation, We Need To Plot Each Given Ordered PairDocument11 pagesTo Graph A Relation, We Need To Plot Each Given Ordered PairSungmin KimNo ratings yet
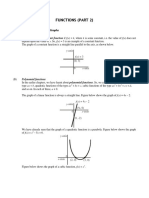
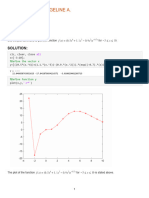
- Functions (Part 2)Document10 pagesFunctions (Part 2)Ankur GoelNo ratings yet
- L08 InterpolationDocument13 pagesL08 InterpolationAceNo ratings yet
- MATH 272 Reference SheetDocument2 pagesMATH 272 Reference Sheet140557No ratings yet
- Lecture 11 Graphs of FunctionsDocument8 pagesLecture 11 Graphs of Functionsargie gutierrezNo ratings yet
- Control Systems Lab No. 01 (Matlab Basics)Document12 pagesControl Systems Lab No. 01 (Matlab Basics)Ashno KhanNo ratings yet
- Calculus 2 Noter - DaDocument17 pagesCalculus 2 Noter - DalukaspjNo ratings yet
- Lec 18 Unidirectional Search PDFDocument32 pagesLec 18 Unidirectional Search PDFMuhammad Bilal JunaidNo ratings yet
- Cal211-CC05-GROUP 8Document11 pagesCal211-CC05-GROUP 8danh.tran214No ratings yet
- Vietnam National UniversityDocument14 pagesVietnam National UniversityQuang VõNo ratings yet
- Solving ODE Symbolically in MATLABDocument5 pagesSolving ODE Symbolically in MATLABjojonNo ratings yet
- Matlab Code 3Document29 pagesMatlab Code 3kthshlxyzNo ratings yet
- Mathematics SciLabDocument36 pagesMathematics SciLabMihir DesaiNo ratings yet
- MAT371 Graphics with MatlabDocument4 pagesMAT371 Graphics with MatlabseventhhemanthNo ratings yet
- Langrange and Serendipity FamilyDocument9 pagesLangrange and Serendipity Familynihal100% (2)
- Sin (1/x), Fplot Command - y Sin (X), Area (X, Sin (X) ) - y Exp (-X. X), Barh (X, Exp (-X. X) )Document26 pagesSin (1/x), Fplot Command - y Sin (X), Area (X, Sin (X) ) - y Exp (-X. X), Barh (X, Exp (-X. X) )ayman hammadNo ratings yet
- Course 8 Chapter 5 - Approximation of Functions - InterpolationDocument3 pagesCourse 8 Chapter 5 - Approximation of Functions - InterpolationIustin CristianNo ratings yet
- Linear Control System LabDocument18 pagesLinear Control System LabMuhammad Saad Abdullah100% (1)
- Mathematical Lab PDFDocument29 pagesMathematical Lab PDFvamsi krishnaNo ratings yet
- Integracion Doble - EjemploDocument32 pagesIntegracion Doble - EjemplocmfariaNo ratings yet
- Lab Assignment 2 Differential EquationsDocument2 pagesLab Assignment 2 Differential EquationsatisundarNo ratings yet
- Analytical and Numerical Solutions of ODEs Using Euler, Heun, and RK MethodsDocument12 pagesAnalytical and Numerical Solutions of ODEs Using Euler, Heun, and RK MethodsVaticanCamNo ratings yet
- Lecture 2.1: Vector Calculus CSC 84020 - Machine Learning: Andrew RosenbergDocument46 pagesLecture 2.1: Vector Calculus CSC 84020 - Machine Learning: Andrew RosenbergAli BhuttaNo ratings yet
- State-Space SystemDocument23 pagesState-Space SystemOmar ElsayedNo ratings yet
- Assignment 1Document2 pagesAssignment 1Prasanna ⎝⏠⏝⏠⎠No ratings yet
- Tre Ci Kolokvij Iz Matematike II 2009./2010.: R Diferencijabilna Funkcija Dviju Varijabli., yDocument8 pagesTre Ci Kolokvij Iz Matematike II 2009./2010.: R Diferencijabilna Funkcija Dviju Varijabli., yTARELIC1802No ratings yet
- Matlab ProgramsDocument20 pagesMatlab Programsapi-3806686100% (1)
- DIGITAL ASSIGNMENT-4: Solving Differential Equations with Laplace Transforms and Power Series in MATLABDocument4 pagesDIGITAL ASSIGNMENT-4: Solving Differential Equations with Laplace Transforms and Power Series in MATLABHAVILA REDDY D 19BCT0211No ratings yet
- GE 127 Week 3 LectureDocument8 pagesGE 127 Week 3 LecturemanishnarayanNo ratings yet
- A Tutorial On The Aitken Convergence AcceleratorDocument13 pagesA Tutorial On The Aitken Convergence AcceleratorPablo RodriguezNo ratings yet
- Lab Maple8 TutorialDocument10 pagesLab Maple8 TutorialPop RobertNo ratings yet
- تطبيقات الحاسوب Computer Application 6Document12 pagesتطبيقات الحاسوب Computer Application 6yousifNo ratings yet
- Taylor Polynomials: Ucsc Supplementary Notes Ams/econ 11aDocument7 pagesTaylor Polynomials: Ucsc Supplementary Notes Ams/econ 11acacaNo ratings yet
- Euler: Restart F: (X, Y) - yDocument3 pagesEuler: Restart F: (X, Y) - yMiguel GarzónNo ratings yet
- Midterm 2008s SolutionDocument12 pagesMidterm 2008s SolutionAlexSpiridonNo ratings yet
- Ten-Decimal Tables of the Logarithms of Complex Numbers and for the Transformation from Cartesian to Polar Coordinates: Volume 33 in Mathematical Tables SeriesFrom EverandTen-Decimal Tables of the Logarithms of Complex Numbers and for the Transformation from Cartesian to Polar Coordinates: Volume 33 in Mathematical Tables SeriesNo ratings yet
- BCD CaseDocument1 pageBCD CaseOSBALDO1205No ratings yet
- Progracion VexDocument3 pagesProgracion VexOSBALDO1205No ratings yet
- Autodesk Inventor Practice Part DrawingsDocument25 pagesAutodesk Inventor Practice Part DrawingsCiprian Fratila100% (1)
- Manual CosimirDocument94 pagesManual CosimirMiguel MoralesNo ratings yet
- 2 N 2646,2647Document0 pages2 N 2646,2647Mark RaboyNo ratings yet
- Inteligencia Artificial Java (English)Document222 pagesInteligencia Artificial Java (English)donvidela100% (4)
- Game Design Document TemplateDocument2 pagesGame Design Document TemplateAdityaNo ratings yet
- gddDocument12 pagesgddAnshar AncayNo ratings yet
- Formal LetterDocument3 pagesFormal LetterOSBALDO1205No ratings yet
- NTE2396 MOSFET N-Ch, Enhancement Mode High Speed Switch TO220Document4 pagesNTE2396 MOSFET N-Ch, Enhancement Mode High Speed Switch TO220OSBALDO1205No ratings yet
- NTE2396 MOSFET N-Ch, Enhancement Mode High Speed Switch TO220Document4 pagesNTE2396 MOSFET N-Ch, Enhancement Mode High Speed Switch TO220OSBALDO1205No ratings yet
- Barner Sensores PDFDocument8 pagesBarner Sensores PDFOSBALDO1205No ratings yet
- NTE2396 MOSFET N-Ch, Enhancement Mode High Speed Switch TO220Document4 pagesNTE2396 MOSFET N-Ch, Enhancement Mode High Speed Switch TO220OSBALDO1205No ratings yet
- CJK-OSM 6 (Kyoto) Full-PaperDocument8 pagesCJK-OSM 6 (Kyoto) Full-PaperMasaaki MikiNo ratings yet
- Grades 7 and 8 (First Quarter) : Weeks Grade 7 Act/Material Feedback Grade 8 Act/Material FeedbackDocument14 pagesGrades 7 and 8 (First Quarter) : Weeks Grade 7 Act/Material Feedback Grade 8 Act/Material FeedbackAlbec Sagrado BallacarNo ratings yet
- Point Slope4Document11 pagesPoint Slope4LolluNo ratings yet
- Chemistry IADocument17 pagesChemistry IAAlysha SubendranNo ratings yet
- Mining EngineeringDocument2 pagesMining EngineeringKiran Kirk100% (1)
- TextDocument60 pagesTextapi-274031459No ratings yet
- Math PDFDocument309 pagesMath PDFPCFC elite III100% (2)
- ALGEBRAIC EXPRESSIONS AND EQUATIONSDocument38 pagesALGEBRAIC EXPRESSIONS AND EQUATIONSAliNo ratings yet
- IMSL Fortran Library User Guide 1 PDFDocument947 pagesIMSL Fortran Library User Guide 1 PDFAshoka VanjareNo ratings yet
- (Walter G. Kelley, Allan C. Peterson) Difference eDocument404 pages(Walter G. Kelley, Allan C. Peterson) Difference eAbdulRehmanKhilji90% (10)
- 478 PDFDocument166 pages478 PDFdkrirayNo ratings yet
- Linear Dynamical Systems - Course ReaderDocument414 pagesLinear Dynamical Systems - Course ReaderTraderCat SolarisNo ratings yet
- Ttl1 Activity 9 (Loberiano) PDFDocument8 pagesTtl1 Activity 9 (Loberiano) PDFLoberiano GeraldNo ratings yet
- CHM 201 Lab - Determination of An Equilibrium ConstantDocument3 pagesCHM 201 Lab - Determination of An Equilibrium ConstantEllah GutierrezNo ratings yet
- Grade 8 Math Deped CurriculumDocument12 pagesGrade 8 Math Deped CurriculumReiza May100% (1)
- Solving ODEs Using Taylor Series ..Document25 pagesSolving ODEs Using Taylor Series ..asfimalikNo ratings yet
- MATH 8 - Q1 - Mod13 PDFDocument13 pagesMATH 8 - Q1 - Mod13 PDFALLYSSA MAE PELONIANo ratings yet
- Introductory Mathematics. Applications and MethodsDocument232 pagesIntroductory Mathematics. Applications and MethodsDietethiqueNo ratings yet
- Curve FittingDocument28 pagesCurve FittingCillalois Marie FameroNo ratings yet
- P6, P7 Linear Systems of Differential EquationsDocument10 pagesP6, P7 Linear Systems of Differential EquationsYosua Petra HattuNo ratings yet
- Solve Linear Systems EliminationDocument12 pagesSolve Linear Systems EliminationMatthew JohnNo ratings yet
- Business Mathematics - I (QTM-110)Document5 pagesBusiness Mathematics - I (QTM-110)ShariqShafiqNo ratings yet
- Chapter 2 Linear Graphs and Simultaneous Linear Equations Exercise 2C 1Document55 pagesChapter 2 Linear Graphs and Simultaneous Linear Equations Exercise 2C 1Calvin OngNo ratings yet
- Math22 Lecture1 f19Document28 pagesMath22 Lecture1 f19Lilia XaNo ratings yet
- Lesson 6-Rectangular Coordinate System and Linear Equation in Two VariablesDocument35 pagesLesson 6-Rectangular Coordinate System and Linear Equation in Two VariablesEliza CalixtoNo ratings yet
- Quarter 1 Week 8Document43 pagesQuarter 1 Week 8Eliza Antolin CortadoNo ratings yet
- Unit 1 - Expressions Equations InequalitiesDocument2 pagesUnit 1 - Expressions Equations Inequalitiesapi-238098925No ratings yet
- Matematika I Statistika Za IMQFDocument208 pagesMatematika I Statistika Za IMQFGo WolowitzNo ratings yet
- Maths Class 9 PDFDocument295 pagesMaths Class 9 PDFHemanthNo ratings yet
- Higher checklist for geometry, algebra, statistics and probabilityDocument3 pagesHigher checklist for geometry, algebra, statistics and probabilityStevenstrange001 CattyNo ratings yet