You might also like
- Why The Euro Will Rival The Dollar PDFDocument25 pagesWhy The Euro Will Rival The Dollar PDFDaniel Lee Eisenberg JacobsNo ratings yet
- Beta Anomaly Tail Risk ApproachDocument104 pagesBeta Anomaly Tail Risk ApproachDaniel Lee Eisenberg JacobsNo ratings yet
- Claudia Jones Nuclear TestingDocument25 pagesClaudia Jones Nuclear TestingDaniel Lee Eisenberg JacobsNo ratings yet
- Conference Group For Central European History of The American Historical AssociationDocument9 pagesConference Group For Central European History of The American Historical AssociationDaniel Lee Eisenberg JacobsNo ratings yet
- Cambridge University Press, International Labor and Working-Class, Inc. International Labor and Working-Class HistoryDocument13 pagesCambridge University Press, International Labor and Working-Class, Inc. International Labor and Working-Class HistoryDaniel Lee Eisenberg Jacobs100% (1)
- Browder - The American SpiritDocument2 pagesBrowder - The American SpiritDaniel Lee Eisenberg JacobsNo ratings yet
- Capital vs Labor: A History of Working Class StruggleDocument9 pagesCapital vs Labor: A History of Working Class StruggleDaniel Lee Eisenberg Jacobs100% (1)
- Necessary and Sufficient Conditions For Dynamic OptimizationDocument18 pagesNecessary and Sufficient Conditions For Dynamic OptimizationDaniel Lee Eisenberg JacobsNo ratings yet
- Marx's Critique of Political EconomyDocument5 pagesMarx's Critique of Political EconomyDaniel Lee Eisenberg JacobsNo ratings yet
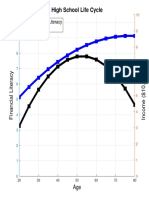
- High School Life Cycle: Financial Literacy IncomeDocument1 pageHigh School Life Cycle: Financial Literacy IncomeDaniel Lee Eisenberg JacobsNo ratings yet
- Continuity Change State of Process of Task ofDocument1 pageContinuity Change State of Process of Task ofDaniel Lee Eisenberg JacobsNo ratings yet
- Karl Kautsky Republic and Social Democra PDFDocument4 pagesKarl Kautsky Republic and Social Democra PDFDaniel Lee Eisenberg JacobsNo ratings yet
- 1996 ElectionDocument84 pages1996 ElectionDaniel Lee Eisenberg JacobsNo ratings yet
- Kant Conflict of FacultiesDocument11 pagesKant Conflict of FacultiesDaniel Lee Eisenberg JacobsNo ratings yet
- Statics and Dynamics in Socialist Economics PDFDocument19 pagesStatics and Dynamics in Socialist Economics PDFDaniel Lee Eisenberg JacobsNo ratings yet
- Measures and Integration on Measurable SpacesDocument181 pagesMeasures and Integration on Measurable SpacesDaniel Lee Eisenberg Jacobs100% (1)
- Morningstar GammaDocument4 pagesMorningstar GammaDaniel Lee Eisenberg JacobsNo ratings yet
- FERC Economist Position Application by Daniel JacobsDocument1 pageFERC Economist Position Application by Daniel JacobsDaniel Lee Eisenberg JacobsNo ratings yet
- University of Oxford Draft-COVID-19-Model - 2020Document7 pagesUniversity of Oxford Draft-COVID-19-Model - 2020Eric L. VanDussenNo ratings yet
- LTC Insurance Puzzle ExplainedDocument17 pagesLTC Insurance Puzzle ExplainedDaniel Lee Eisenberg JacobsNo ratings yet
- Gpebook PDFDocument332 pagesGpebook PDFDaniel Lee Eisenberg JacobsNo ratings yet
- Incentive Contracts in Delegated Portfolio ManagementDocument41 pagesIncentive Contracts in Delegated Portfolio ManagementDaniel Lee Eisenberg JacobsNo ratings yet
- Time Is Money - Rational Life Cycle InertiaDocument39 pagesTime Is Money - Rational Life Cycle InertiaDaniel Lee Eisenberg JacobsNo ratings yet
- Notes On Forbidden RegressionsDocument5 pagesNotes On Forbidden RegressionsZundaNo ratings yet
- Individualization of Robo-AdviceDocument8 pagesIndividualization of Robo-AdviceDaniel Lee Eisenberg JacobsNo ratings yet
- Vanguard How Investors Select Advisors PDFDocument49 pagesVanguard How Investors Select Advisors PDFDaniel Lee Eisenberg JacobsNo ratings yet
- 09 MihatovDocument14 pages09 MihatovRaphael T. SprengerNo ratings yet
- Genetic Algorithm in Economics and Agent Based ModelsDocument23 pagesGenetic Algorithm in Economics and Agent Based ModelsDaniel Lee Eisenberg JacobsNo ratings yet
- Vanguard How Investors Select Advisors PDFDocument49 pagesVanguard How Investors Select Advisors PDFDaniel Lee Eisenberg JacobsNo ratings yet
- A Multiobjective Model For Passive Portfolio ManagementDocument32 pagesA Multiobjective Model For Passive Portfolio ManagementDaniel Lee Eisenberg JacobsNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5784)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (72)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- 2.2 Concavity PDFDocument12 pages2.2 Concavity PDFpatrick alvesNo ratings yet
- MTH202 - Discrete Mathematics - Solved - Final Term Paper - 01 PDFDocument10 pagesMTH202 - Discrete Mathematics - Solved - Final Term Paper - 01 PDFbc190204121 IRFA HAYATNo ratings yet
- Chapter 13-Differentiation 2 MDISDocument10 pagesChapter 13-Differentiation 2 MDISterrygoh6972No ratings yet
- ALGORITHMS MCQS WITH ANSWERSDocument10 pagesALGORITHMS MCQS WITH ANSWERSKande Archana K60% (5)
- Further Results On Product Cordial LabelingDocument8 pagesFurther Results On Product Cordial LabelingDon HassNo ratings yet
- Nonlinear Control Stability AnalysisDocument7 pagesNonlinear Control Stability AnalysisFatihNo ratings yet
- MATH-816 Applied Linear Algebra Matrices & Linear TransformationsDocument26 pagesMATH-816 Applied Linear Algebra Matrices & Linear TransformationsSadiqNo ratings yet
- Example of Calculus 1 by ClipvidvaDocument60 pagesExample of Calculus 1 by ClipvidvaTanawat ChansophonkulNo ratings yet
- Block Diagram ReductionDocument5 pagesBlock Diagram Reductionİsmail KayahanNo ratings yet
- Enlargement WorksheetDocument10 pagesEnlargement WorksheetAmjadNo ratings yet
- MT2176Document4 pagesMT2176Jeet JunejaNo ratings yet
- Multiple Choice Questions on MatricesDocument3 pagesMultiple Choice Questions on MatricesÁñsh KàñøjíâNo ratings yet
- Ch-2 RD MathsDocument60 pagesCh-2 RD MathsThe VRAJ GAMESNo ratings yet
- (Horizons in World Physics 237) A. S. Demidov - Generalized Functions in Mathematical Physics - Main Ideas and Concepts - Nova Science Pub Inc (2001)Document153 pages(Horizons in World Physics 237) A. S. Demidov - Generalized Functions in Mathematical Physics - Main Ideas and Concepts - Nova Science Pub Inc (2001)paku deyNo ratings yet
- boundary value problems+chawla - جستجوی GoogleDocument12 pagesboundary value problems+chawla - جستجوی GoogleHamed Daei KasmaeiNo ratings yet
- Kcet Maths Answer Key d3Document8 pagesKcet Maths Answer Key d3RohithNo ratings yet
- Araneta All Problem Sets Exams Practice Exams Math 83Document55 pagesAraneta All Problem Sets Exams Practice Exams Math 83Marvince AranetaNo ratings yet
- Programme 2024Document19 pagesProgramme 2024oumaimahajjouli783No ratings yet
- Module 4: Transportation Problem and Assignment Problem: Prasad A Y, Dept of CSE, ACSCE, B'lore-74Document37 pagesModule 4: Transportation Problem and Assignment Problem: Prasad A Y, Dept of CSE, ACSCE, B'lore-74Hào Văn TríNo ratings yet
- The B-Chromatic Number of A Graph: Robert W. Irving, David F. Manlove - 'Document15 pagesThe B-Chromatic Number of A Graph: Robert W. Irving, David F. Manlove - 'கார்த்திகேயன் சண்முகம்No ratings yet
- Operations on Functions GuideDocument9 pagesOperations on Functions GuideAira Mae PazNo ratings yet
- FV DiffusionDocument13 pagesFV DiffusionNâzım KoşanNo ratings yet
- MATH1231 TutorialDocument5 pagesMATH1231 TutorialMr. WayneNo ratings yet
- Matlab Programming Laboratory: X X X X X X X FDocument2 pagesMatlab Programming Laboratory: X X X X X X X FGeorgeNo ratings yet
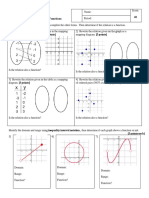
- HW Checkpoint #5 (Relations and Functions)Document2 pagesHW Checkpoint #5 (Relations and Functions)Menna ArafaNo ratings yet
- Fourier Transform and It's ApplicationsDocument24 pagesFourier Transform and It's ApplicationsImranNo ratings yet
- R-1 Transformation of RootsDocument2 pagesR-1 Transformation of RootsPrabhat SharmaNo ratings yet
- Matematika Ii: Fakultas Teknik Sipil Dan Perencanaan Institut Teknologi NasionalDocument32 pagesMatematika Ii: Fakultas Teknik Sipil Dan Perencanaan Institut Teknologi NasionalAdindaNo ratings yet
- Interpolation: 6.1 Interpolation in Sobolev Spaces by Polynomi-AlsDocument12 pagesInterpolation: 6.1 Interpolation in Sobolev Spaces by Polynomi-AlsJorgeAguayoNo ratings yet