You might also like
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Favis vs. Mun. of SabanganDocument5 pagesFavis vs. Mun. of SabanganAyra CadigalNo ratings yet
- Calcined Clays For Sustainable Concrete Karen Scrivener, AurÇlie Favier, 2015Document552 pagesCalcined Clays For Sustainable Concrete Karen Scrivener, AurÇlie Favier, 2015Débora BretasNo ratings yet
- EIS Summary NotsDocument62 pagesEIS Summary NotsKESHAV DroliaNo ratings yet
- Booklet - Frantic Assembly Beautiful BurnoutDocument10 pagesBooklet - Frantic Assembly Beautiful BurnoutMinnie'xoNo ratings yet
- Education Law OutlineDocument53 pagesEducation Law Outlinemischa29100% (1)
- NetStumbler Guide2Document3 pagesNetStumbler Guide2Maung Bay0% (1)
- RBMWizardDocument286 pagesRBMWizardJesus EspinozaNo ratings yet
- New VibesDocument12 pagesNew VibesSangeeta S. Bhagwat90% (20)
- Operational Effectiveness + StrategyDocument7 pagesOperational Effectiveness + StrategyPaulo GarcezNo ratings yet
- An Analysis of The PoemDocument2 pagesAn Analysis of The PoemDayanand Gowda Kr100% (2)
- Stockholm KammarbrassDocument20 pagesStockholm KammarbrassManuel CoitoNo ratings yet
- The Music of OhanaDocument31 pagesThe Music of OhanaSquaw100% (3)
- A New Cloud Computing Governance Framework PDFDocument8 pagesA New Cloud Computing Governance Framework PDFMustafa Al HassanNo ratings yet
- Jordana Wagner Leadership Inventory Outcome 2Document22 pagesJordana Wagner Leadership Inventory Outcome 2api-664984112No ratings yet
- Ad1 MCQDocument11 pagesAd1 MCQYashwanth Srinivasa100% (1)
- BIOCHEM REPORT - OdtDocument16 pagesBIOCHEM REPORT - OdtLingeshwarry JewarethnamNo ratings yet
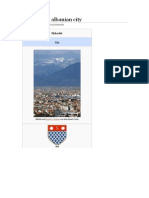
- Shkodër An Albanian CityDocument16 pagesShkodër An Albanian CityXINKIANGNo ratings yet
- Summar Training Report HRTC TRAINING REPORTDocument43 pagesSummar Training Report HRTC TRAINING REPORTPankaj ChauhanNo ratings yet
- Data Science Online Workshop Data Science vs. Data AnalyticsDocument1 pageData Science Online Workshop Data Science vs. Data AnalyticsGaurav VarshneyNo ratings yet
- 1 - HandBook CBBR4106Document29 pages1 - HandBook CBBR4106mkkhusairiNo ratings yet
- E 05-03-2022 Power Interruption Schedule FullDocument22 pagesE 05-03-2022 Power Interruption Schedule FullAda Derana100% (2)
- How Is Extra-Musical Meaning Possible - Music As A Place and Space For Work - T. DeNora (1986)Document12 pagesHow Is Extra-Musical Meaning Possible - Music As A Place and Space For Work - T. DeNora (1986)vladvaidean100% (1)
- Indus Valley Sites in IndiaDocument52 pagesIndus Valley Sites in IndiaDurai IlasunNo ratings yet
- Introduction To PTC Windchill PDM Essentials 11.1 For Light UsersDocument6 pagesIntroduction To PTC Windchill PDM Essentials 11.1 For Light UsersJYNo ratings yet
- Diabetes & Metabolic Syndrome: Clinical Research & ReviewsDocument3 pagesDiabetes & Metabolic Syndrome: Clinical Research & ReviewspotatoNo ratings yet
- Saxonville CaseDocument2 pagesSaxonville Casel103m393No ratings yet
- De La Salle Araneta University Grading SystemDocument2 pagesDe La Salle Araneta University Grading Systemnicolaus copernicus100% (2)
- Popular Music Analysis and MusicologyDocument15 pagesPopular Music Analysis and MusicologyAlexMartínVidal100% (3)
- Lets Install Cisco ISEDocument8 pagesLets Install Cisco ISESimon GarciaNo ratings yet
- Tugas 3Document20 pagesTugas 3dellaayuNo ratings yet