You might also like
- Shapes: Challenge 2 QuadrilateralsDocument1 pageShapes: Challenge 2 QuadrilateralsChandrahasa Reddy ThatimakulaNo ratings yet
- Measuring: Units and Conversions Challenge 1Document1 pageMeasuring: Units and Conversions Challenge 1Chandrahasa Reddy ThatimakulaNo ratings yet
- Making Sense of SexDocument322 pagesMaking Sense of SexChandrahasa Reddy ThatimakulaNo ratings yet
- Chapter 5Document22 pagesChapter 5Chandrahasa Reddy Thatimakula100% (1)
- Chapter 4 000Document46 pagesChapter 4 000Chandrahasa Reddy ThatimakulaNo ratings yet
- Chapter 3Document19 pagesChapter 3Chandrahasa Reddy Thatimakula100% (1)
- Chapter 4Document27 pagesChapter 4Chandrahasa Reddy ThatimakulaNo ratings yet
- Different Branches of Finance Department: SL .No Name of The Branch SL .No Name of The BranchDocument1 pageDifferent Branches of Finance Department: SL .No Name of The Branch SL .No Name of The BranchChandrahasa Reddy ThatimakulaNo ratings yet
- Chapter 2Document19 pagesChapter 2Chandrahasa Reddy ThatimakulaNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- BA 4722 Marketing Strategy SyllabusDocument6 pagesBA 4722 Marketing Strategy SyllabusSri GunawanNo ratings yet
- JCIPDocument5 pagesJCIPdinesh.nayak.bbsrNo ratings yet
- Digestive System Worksheet 2013 2Document3 pagesDigestive System Worksheet 2013 2contessa padonNo ratings yet
- ICU General Admission Orders: OthersDocument2 pagesICU General Admission Orders: OthersHANIMNo ratings yet
- Catalog Tu ZG3.2 Gian 35kV H'MunDocument40 pagesCatalog Tu ZG3.2 Gian 35kV H'MunHà Văn TiếnNo ratings yet
- Research Methods in Developmental PsychologyDocument9 pagesResearch Methods in Developmental PsychologyHugoNo ratings yet
- List of Olympic MascotsDocument10 pagesList of Olympic MascotsmukmukkumNo ratings yet
- 16 Personalities ResultsDocument9 pages16 Personalities Resultsapi-605848036No ratings yet
- Topic 1 - ICT Tools at USP - Theoretical Notes With Google AppsDocument18 pagesTopic 1 - ICT Tools at USP - Theoretical Notes With Google AppsAvantika PrasadNo ratings yet
- What Is Product Management?Document37 pagesWhat Is Product Management?Jeffrey De VeraNo ratings yet
- STARCHETYPE REPORT ReLOADED AUGURDocument5 pagesSTARCHETYPE REPORT ReLOADED AUGURBrittany-faye OyewumiNo ratings yet
- ATS2017 ProspectusDocument13 pagesATS2017 ProspectusGiri WakshanNo ratings yet
- Ethiopian Airlines-ResultsDocument1 pageEthiopian Airlines-Resultsabdirahmanguray46No ratings yet
- Micro - Systemic Bacteriology Questions PDFDocument79 pagesMicro - Systemic Bacteriology Questions PDFShashipriya AgressNo ratings yet
- Module 2 TechnologyDocument20 pagesModule 2 Technologybenitez1No ratings yet
- Bin Adam Group of CompaniesDocument8 pagesBin Adam Group of CompaniesSheema AhmadNo ratings yet
- SXV RXV ChassisDocument239 pagesSXV RXV Chassischili_s16No ratings yet
- Malling DemallingDocument25 pagesMalling DemallingVijay KumarNo ratings yet
- Taxation Law 1Document7 pagesTaxation Law 1jalefaye abapoNo ratings yet
- Marieb ch3dDocument20 pagesMarieb ch3dapi-229554503No ratings yet
- Rin Case StudyDocument4 pagesRin Case StudyReha Nayyar100% (1)
- Durability of Prestressed Concrete StructuresDocument12 pagesDurability of Prestressed Concrete StructuresMadura JobsNo ratings yet
- Strategic Capital Management: Group - 4 Jahnvi Jethanandini Shreyasi Halder Siddhartha Bayye Sweta SarojDocument5 pagesStrategic Capital Management: Group - 4 Jahnvi Jethanandini Shreyasi Halder Siddhartha Bayye Sweta SarojSwetaSarojNo ratings yet
- RevlonDocument13 pagesRevlonSarosh AtaNo ratings yet
- Epistemology and OntologyDocument6 pagesEpistemology and OntologyPriyankaNo ratings yet
- Phy Mock SolDocument17 pagesPhy Mock SolA PersonNo ratings yet
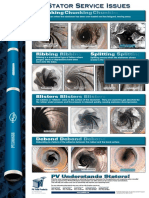
- Chunking Chunking Chunking: Stator Service IssuesDocument1 pageChunking Chunking Chunking: Stator Service IssuesGina Vanessa Quintero CruzNo ratings yet
- Saif Powertec Limited Project "Standard Operating Process" As-Is DocumentDocument7 pagesSaif Powertec Limited Project "Standard Operating Process" As-Is DocumentAbhishekChowdhuryNo ratings yet
- Perturbation MethodsDocument29 pagesPerturbation Methodsmhdr100% (1)
- ProspDocument146 pagesProspRajdeep BharatiNo ratings yet