You might also like
- Learn Statistics Fast: A Simplified Detailed Version for StudentsFrom EverandLearn Statistics Fast: A Simplified Detailed Version for StudentsNo ratings yet
- Testing of Hypothesis: 1 Steps For SolutionDocument8 pagesTesting of Hypothesis: 1 Steps For SolutionAaron MillsNo ratings yet
- Advanced Statistics Hypothesis TestingDocument42 pagesAdvanced Statistics Hypothesis TestingShermaine CachoNo ratings yet
- ) and Variance, So The Hypothesis, H: andDocument4 pages) and Variance, So The Hypothesis, H: andPi YaNo ratings yet
- S2 Revision NotesDocument2 pagesS2 Revision NotesimnulNo ratings yet
- L7 Hypothesis TestingDocument59 pagesL7 Hypothesis Testingمصطفى سامي شهيد لفتهNo ratings yet
- Testing of HypothesisDocument37 pagesTesting of HypothesisSiddharth Bahri67% (3)
- Business Statistics and Management Science NotesDocument74 pagesBusiness Statistics and Management Science Notes0pointsNo ratings yet
- Lecture21 HypothesisTest1Document53 pagesLecture21 HypothesisTest1Sonam AlviNo ratings yet
- Statistics Cheat SheetDocument23 pagesStatistics Cheat Sheetcannickg100% (2)
- Test of HypothesisDocument85 pagesTest of HypothesisJyoti Prasad Sahu64% (11)
- Hypothesis Statistics-1-1Document35 pagesHypothesis Statistics-1-111- NikunjNo ratings yet
- Chapter Five Hypothesis TestingDocument50 pagesChapter Five Hypothesis TestingdenekeNo ratings yet
- Basic Concepts in Hypothesis Testing (Rosalind L P Phang)Document7 pagesBasic Concepts in Hypothesis Testing (Rosalind L P Phang)SARA MORALES GALVEZNo ratings yet
- Stat 255 Supplement 2011 FallDocument78 pagesStat 255 Supplement 2011 Fallgoofbooter100% (1)
- CFA Level 1 Review - Quantitative MethodsDocument10 pagesCFA Level 1 Review - Quantitative MethodsAamirx6450% (2)
- Flipped Notes 9 - Applications of Testing HypothesisDocument13 pagesFlipped Notes 9 - Applications of Testing HypothesisJoemar Doctör SubongNo ratings yet
- APNotes Chap09 876543445678Document2 pagesAPNotes Chap09 876543445678Laayba BasitNo ratings yet
- Handout 7Document16 pagesHandout 7farahNo ratings yet
- MODULE 3 Normal Probabaility Curve and Hypothesis TestingDocument7 pagesMODULE 3 Normal Probabaility Curve and Hypothesis TestingShijiThomasNo ratings yet
- Testing of HypothesisDocument15 pagesTesting of HypothesisALLADA JAYAVANTH KUMARNo ratings yet
- Statistics For College Students-Part 2Document43 pagesStatistics For College Students-Part 2Yeyen Patino100% (1)
- ECN 416 - Applied Statistics Week 6Document73 pagesECN 416 - Applied Statistics Week 6OREJESU EUNICE OJUTIKUNo ratings yet
- Hypothesis Testing ReviewDocument5 pagesHypothesis Testing ReviewhalleyworldNo ratings yet
- Forms of Test StatisticDocument31 pagesForms of Test StatisticJackielou TrongcosoNo ratings yet
- Review of StatisticsDocument36 pagesReview of StatisticsJessica AngelinaNo ratings yet
- Test Hypothsisng 10-2022Document9 pagesTest Hypothsisng 10-2022ALSAIDI ALTAHERNo ratings yet
- TohDocument53 pagesTohY20me135 V.LokeshNo ratings yet
- L4 Hypothesis Tests 2021 FDocument27 pagesL4 Hypothesis Tests 2021 Fama kumarNo ratings yet
- Hypothesis TestingDocument69 pagesHypothesis TestingGaurav SonkarNo ratings yet
- Assignment 2Document22 pagesAssignment 2Nurul Absar RashedNo ratings yet
- Lecture 12 - T-Test IDocument33 pagesLecture 12 - T-Test Iamedeuce lyatuuNo ratings yet
- Statistical Analysis Data Treatment and EvaluationDocument55 pagesStatistical Analysis Data Treatment and EvaluationJyl CodeñieraNo ratings yet
- Hypothesis Testing. BCApptxDocument34 pagesHypothesis Testing. BCApptxshedotuoyNo ratings yet
- Hypothesis TestingDocument45 pagesHypothesis TestingHerman R. SuwarmanNo ratings yet
- Chapter 8 and 9Document7 pagesChapter 8 and 9Ellii YouTube channelNo ratings yet
- CH 9 (Notes)Document23 pagesCH 9 (Notes)Chilombo Kelvin100% (2)
- Hypothesis+tests+involving+a+sample+mean+or+proportionDocument45 pagesHypothesis+tests+involving+a+sample+mean+or+proportionJerome Badillo100% (1)
- Chapter 1Document19 pagesChapter 1camerogabriel5No ratings yet
- Stat and Prob Q4 Week 3 Module 11 Alexander Randy EstradaDocument21 pagesStat and Prob Q4 Week 3 Module 11 Alexander Randy Estradagabezarate071No ratings yet
- Chapters 10,11,12Document6 pagesChapters 10,11,12sarkarigamingytNo ratings yet
- Unit 5 MTH302Document53 pagesUnit 5 MTH302Rohit KumarNo ratings yet
- Z Test and T TestDocument7 pagesZ Test and T TestTharhanee MuniandyNo ratings yet
- Sampling PDFDocument117 pagesSampling PDFDiyaliNo ratings yet
- Hypothesis Test For DiffDocument30 pagesHypothesis Test For Diffفاطمه حسينNo ratings yet
- 4-Decision Making For Single SampleDocument71 pages4-Decision Making For Single SampleHassan AyashNo ratings yet
- Chapter No. 08 Fundamental Sampling Distributions and Data Descriptions - 02 (Presentation)Document91 pagesChapter No. 08 Fundamental Sampling Distributions and Data Descriptions - 02 (Presentation)Sahib Ullah MukhlisNo ratings yet
- QueDocument13 pagesQueSatish G KulkarniNo ratings yet
- Hoda MR S23 Hypothesis Testing UpdatedDocument92 pagesHoda MR S23 Hypothesis Testing UpdatedNadineNo ratings yet
- Test of HypothesisDocument3 pagesTest of HypothesisMd MahfuzNo ratings yet
- ST 5Document21 pagesST 5HIMANSHU ATALNo ratings yet
- CH7 - Statistical Data Treatment and EvaluationDocument56 pagesCH7 - Statistical Data Treatment and EvaluationGiovanni PelobilloNo ratings yet
- Normal Distribution: X e X FDocument30 pagesNormal Distribution: X e X FNilesh DhakeNo ratings yet
- Lecture 03 & 04 EC5002 CLT & Normal Distribution 2015-16Document13 pagesLecture 03 & 04 EC5002 CLT & Normal Distribution 2015-16nishit0157623637No ratings yet
- Introduction To Hypothesis Testing Purpose: Goodson/ 3360hyp 1Document5 pagesIntroduction To Hypothesis Testing Purpose: Goodson/ 3360hyp 1norvin_tolineroNo ratings yet
- qm2 NotesDocument9 pagesqm2 NotesdeltathebestNo ratings yet
- Statistics Hypothesis TestingDocument7 pagesStatistics Hypothesis TestingWasif ImranNo ratings yet
- Statistical Inference: Dr. Mona Hassan AhmedDocument34 pagesStatistical Inference: Dr. Mona Hassan Ahmedkareem3456No ratings yet
- CHP9Document21 pagesCHP9shoaib625No ratings yet
- CHP7Document3 pagesCHP7shoaib625No ratings yet
- Pakistan Economic SurveyDocument18 pagesPakistan Economic SurveyNabi BakhshNo ratings yet
- CHP6Document24 pagesCHP6shoaib625No ratings yet
- CHP5Document15 pagesCHP5shoaib625No ratings yet
- CHP8Document6 pagesCHP8shoaib625No ratings yet
- Selected Economic: Million RupeesDocument2 pagesSelected Economic: Million Rupeesshoaib625No ratings yet
- Macroeconomic Indicators Improve: SBP's Quarterly ReportDocument2 pagesMacroeconomic Indicators Improve: SBP's Quarterly Reportshoaib625No ratings yet
- LecanoralesDocument9 pagesLecanoralesshoaib625No ratings yet
- CV Salman Saif 15Document5 pagesCV Salman Saif 15shoaib625No ratings yet
- 2.1 Gross National ProductDocument8 pages2.1 Gross National Productshoaib625No ratings yet
- Pak Afghan RelationDocument6 pagesPak Afghan Relationshoaib625100% (2)
- Collection Development PolicyDocument7 pagesCollection Development Policyshoaib625No ratings yet
- C.V SajidDocument2 pagesC.V Sajidshoaib625No ratings yet
- 01the First Prime Minister of Bangladesh WasDocument10 pages01the First Prime Minister of Bangladesh Wasshoaib625No ratings yet
- SdsDocument101 pagesSdsshoaib625No ratings yet
- Condition ProbDocument30 pagesCondition Probshoaib625No ratings yet
- Basic Arithmetic PDFDocument18 pagesBasic Arithmetic PDFMuhammad Bilal56% (9)
- Types of UnemploymentDocument7 pagesTypes of UnemploymentshoaibNo ratings yet
- AhsanDocument5 pagesAhsanshoaib625No ratings yet
- RandomnessDocument33 pagesRandomnessshoaib625No ratings yet
- 01 - Mehmood, AzimDocument9 pages01 - Mehmood, AzimAdriana CalinNo ratings yet
- Pakistan KnowledgeDocument3 pagesPakistan KnowledgeSHOAIBNo ratings yet
- Main Macroeconomic IndicatorsDocument59 pagesMain Macroeconomic Indicatorsshoaib625No ratings yet
- My C.VDocument2 pagesMy C.Vshoaib625No ratings yet
- Sampling DistributionDocument9 pagesSampling DistributionLydda CadienteNo ratings yet
- BCG Matrix TemplateDocument3 pagesBCG Matrix Templateshoaib625No ratings yet
- Sadia RafiqueDocument5 pagesSadia Rafiqueshoaib625No ratings yet
- The English Novel of The 18th CenturyDocument9 pagesThe English Novel of The 18th Centuryshoaib625100% (1)
- Statistical InfrenceDocument9 pagesStatistical Infrenceshoaib625No ratings yet
- Sample MT 2 MckeyDocument5 pagesSample MT 2 MckeyFarrukh Ali KhanNo ratings yet
- Community DiagnosisDocument2 pagesCommunity DiagnosiskimerellaNo ratings yet
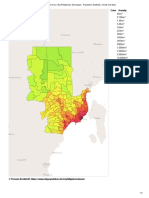
- Davao City (Philippines) - Barangays - Population Statistics, Charts and MapDocument1 pageDavao City (Philippines) - Barangays - Population Statistics, Charts and MapKristin Faye OlaloNo ratings yet
- Pa-4 1649Document4 pagesPa-4 1649Soham GuptaNo ratings yet
- Measures of SpreadDocument9 pagesMeasures of SpreadRizza MongeNo ratings yet
- 2017 APHG Population Pyramid AssignmentDocument6 pages2017 APHG Population Pyramid AssignmentJenniferNo ratings yet
- History of Delfin Albano IsabelaDocument4 pagesHistory of Delfin Albano IsabelaLisa Marsh0% (1)
- Quantitative GeneticsDocument31 pagesQuantitative GeneticsMamtaNo ratings yet
- Statistical Year Book, 2016Document426 pagesStatistical Year Book, 2016Kranti Kumar100% (1)
- Practical 3Document2 pagesPractical 3Phathutshedzo Shonisani MadzwuheNo ratings yet
- How Many Pens That You Have in Pencil BoxDocument11 pagesHow Many Pens That You Have in Pencil BoxMohamad NawawiNo ratings yet
- Dan Shuster's Exploring Data AP StatisticsDocument3 pagesDan Shuster's Exploring Data AP Statisticsgoogle0987No ratings yet
- History: California City Is A City Incorporated in 1965 in The NorthernDocument4 pagesHistory: California City Is A City Incorporated in 1965 in The NorthernDouglas WilsonNo ratings yet
- Introduction To Geography: Arthur Getis, Judith Getis, & Jerome D. FellmannDocument17 pagesIntroduction To Geography: Arthur Getis, Judith Getis, & Jerome D. FellmannMuhamad Kamarulzaman OmarNo ratings yet
- Guiguinto 2010 PopulationDocument1 pageGuiguinto 2010 PopulationDianne RamosNo ratings yet
- Front 23 JulyDocument1 pageFront 23 JulyRebecca BlackNo ratings yet
- 1.2 Demography, Health Statistics & EpidemiologyDocument4 pages1.2 Demography, Health Statistics & Epidemiologyライ0% (1)
- ch9 0Document59 pagesch9 0Mr. ANo ratings yet
- Box-And-Whisker Plot ONLYDocument4 pagesBox-And-Whisker Plot ONLYJoseph HistonNo ratings yet
- India DemographicsDocument1 pageIndia DemographicsamrikesaNo ratings yet
- World Urbanization Prospects 2009 Revision (United Nations 2010)Document56 pagesWorld Urbanization Prospects 2009 Revision (United Nations 2010)geografia e ensino de geografia100% (1)
- Urban Scenario in Tamil NaduDocument18 pagesUrban Scenario in Tamil NaduSherine David SANo ratings yet
- Tribal Demography of UttarakhandDocument10 pagesTribal Demography of UttarakhandVinod S RawatNo ratings yet
- Tabavg 1Document3 pagesTabavg 1api-400431045No ratings yet
- Favel AncestoryDocument36 pagesFavel AncestoryMalcolm AndrewsNo ratings yet
- Albanian LanguageDocument5 pagesAlbanian LanguageAlessandraBattagliaNo ratings yet
- Cumulative FrequencyDocument9 pagesCumulative FrequencyKaran PrabaNo ratings yet
- Statistical Yearbook of Ireland 2013Document383 pagesStatistical Yearbook of Ireland 2013MykaelNo ratings yet
- Ch9 Testbank HandoutDocument2 pagesCh9 Testbank Handoutjoebloggs1888100% (2)
- Skittles ProjectDocument17 pagesSkittles Projectapi-359548770No ratings yet