You might also like
- Diff Between ML DL AI PDFDocument3 pagesDiff Between ML DL AI PDFbarathNo ratings yet
- SAS IML User Guide PDFDocument1,108 pagesSAS IML User Guide PDFJorge Muñoz AristizabalNo ratings yet
- Macro and Macro PreprocessorDocument72 pagesMacro and Macro PreprocessorNitin Birari0% (1)
- Lab 1Document7 pagesLab 1Tanjila Islam Ritu 1811017642No ratings yet
- Mini Project I: Literature SearchDocument5 pagesMini Project I: Literature SearchFernando GalindoNo ratings yet
- VO ExtensionDocument6 pagesVO ExtensionnagkkkkkNo ratings yet
- Matlab Automotive QAsDocument121 pagesMatlab Automotive QAsrathnam.pmNo ratings yet
- Oracle Treasury PDFDocument512 pagesOracle Treasury PDFSriram KalidossNo ratings yet
- C++ Programming - Code - Design PatternsDocument18 pagesC++ Programming - Code - Design Patternsmodis777No ratings yet
- Cost Accounting Book Basu Das Solution In6tlyjzDocument2 pagesCost Accounting Book Basu Das Solution In6tlyjzasgari sheikh20% (5)
- MSC SyllabusDocument27 pagesMSC SyllabusK Kunal RajNo ratings yet
- Compititive Programming - I ManualDocument79 pagesCompititive Programming - I ManualArun ChaudhariNo ratings yet
- AI LAB Manual PDFDocument23 pagesAI LAB Manual PDFRahul PrakashNo ratings yet
- 2014-CD Ch-03 SAnDocument21 pages2014-CD Ch-03 SAnHASEN SEIDNo ratings yet
- Software Design and Architecture JUNE-2021 Sem - II SET-5 (T.Y.B.tech COMP)Document6 pagesSoftware Design and Architecture JUNE-2021 Sem - II SET-5 (T.Y.B.tech COMP)1367 AYUSHA KATEPALLEWARNo ratings yet
- DSE 3 Unit 2Document18 pagesDSE 3 Unit 2Priyaranjan SorenNo ratings yet
- AWP Unit 1Document39 pagesAWP Unit 1RishabNo ratings yet
- Eclipse - STM32 GDB - OpenOCD Commands and Initialization For Flash and Ram Debugging - Stack OverflowDocument6 pagesEclipse - STM32 GDB - OpenOCD Commands and Initialization For Flash and Ram Debugging - Stack OverflowAli TorabiNo ratings yet
- Experiment No 1: 1. Study of Arm Evaluation SystemDocument30 pagesExperiment No 1: 1. Study of Arm Evaluation SystemAshok KumarNo ratings yet
- Solutions&Notes On Imp TopicsDocument15 pagesSolutions&Notes On Imp TopicsMarwan AhmedNo ratings yet
- Tutorial For NXP S32 Design Studio: Starting Out - Creating A WorkspaceDocument17 pagesTutorial For NXP S32 Design Studio: Starting Out - Creating A WorkspaceHtet lin AgNo ratings yet
- CH03 Loaders and LinkersDocument20 pagesCH03 Loaders and LinkersTedo Ham100% (4)
- PPTDocument35 pagesPPTsyulmnmdNo ratings yet
- Design and Analysis of AlgorithmsDocument102 pagesDesign and Analysis of AlgorithmskIller mObNo ratings yet
- Elective I Java Programming NotesDocument219 pagesElective I Java Programming Notessomany12No ratings yet
- Os NotesDocument67 pagesOs NotesHow To ?No ratings yet
- LP - V - Lab Manual - DLDocument53 pagesLP - V - Lab Manual - DLAtharva Nitin ChandwadkarNo ratings yet
- RahulDocument100 pagesRahulPriyanka mestryNo ratings yet
- Merge SortDocument15 pagesMerge Sortapi-3825559No ratings yet
- 1 Types of Parsers in Compiler DesignDocument4 pages1 Types of Parsers in Compiler Designnajma rasoolNo ratings yet
- Ekon27 Pas2js SignDocument22 pagesEkon27 Pas2js Signbreitsch breitschNo ratings yet
- Introduction Nano ProgrammingDocument57 pagesIntroduction Nano ProgrammingDharvendra SinghNo ratings yet
- Practical 1 Dyna KitDocument5 pagesPractical 1 Dyna KitHet PatelNo ratings yet
- Derived Syntactical Constructs in Java: (Type Here)Document25 pagesDerived Syntactical Constructs in Java: (Type Here)Amaan ShaikhNo ratings yet
- Devi Balika Revision PaperDocument16 pagesDevi Balika Revision PaperDahanyakage WickramathungaNo ratings yet
- Operating Systems: Lecture NotesDocument222 pagesOperating Systems: Lecture NotesMinuJose JojyNo ratings yet
- OOP Lab-6Document4 pagesOOP Lab-6Saba ChNo ratings yet
- Lab #4Document4 pagesLab #4Bryan Ricardo Boyer0% (1)
- Application Protocol Not PresentDocument4 pagesApplication Protocol Not PresentPlayIt AllNo ratings yet
- 18CS653 - NOTES Module 1Document24 pages18CS653 - NOTES Module 1SuprithaNo ratings yet
- DataBase Management (VBSPU 4th Sem)Document108 pagesDataBase Management (VBSPU 4th Sem)Atharv KatkarNo ratings yet
- Unit 4Document24 pagesUnit 4TesterNo ratings yet
- Network Programming ImpDocument5 pagesNetwork Programming Impsharath_rakkiNo ratings yet
- Unit - 9 System Construction and ImplementationDocument20 pagesUnit - 9 System Construction and ImplementationSAJAL KOIRALANo ratings yet
- UNIT-III Inheritance, Interfaces, Packages and Exception HandlingDocument63 pagesUNIT-III Inheritance, Interfaces, Packages and Exception Handlingdil rockNo ratings yet
- Data Analytics Unit 3Document14 pagesData Analytics Unit 3Aditi JaiswalNo ratings yet
- Material For CAT 1Document22 pagesMaterial For CAT 1Rithik Narayn100% (1)
- Java Unit 1Document31 pagesJava Unit 1jagan nathanNo ratings yet
- Working With Unix QuizDocument7 pagesWorking With Unix QuizBright Star33% (3)
- Instruction Set of 8085 MicroprocessorDocument8 pagesInstruction Set of 8085 MicroprocessorRocky SamratNo ratings yet
- Ai Important Questions For Semester ExamsDocument197 pagesAi Important Questions For Semester ExamsDeepak YaduvanshiNo ratings yet
- Instruction Codes Computer Registers Computer Instructions Timing and Control Instruction Cycle Memory Reference Instructions Input-Output and Interrupt Complete Computer DescriptionDocument38 pagesInstruction Codes Computer Registers Computer Instructions Timing and Control Instruction Cycle Memory Reference Instructions Input-Output and Interrupt Complete Computer DescriptionYash Gupta MauryaNo ratings yet
- Ssad Notes-Ii BcaDocument68 pagesSsad Notes-Ii Bcaraj kumarNo ratings yet
- Os 1Document46 pagesOs 1kareem mohamedNo ratings yet
- 4340703-CN Lab Manua - 230331 - 134836Document19 pages4340703-CN Lab Manua - 230331 - 134836Kamlesh ParmarNo ratings yet
- Unix Device DriversDocument22 pagesUnix Device DriversSwetang KhatriNo ratings yet
- Ip Lab ManualDocument52 pagesIp Lab Manualanuj1166No ratings yet
- Micro Programmed Control Unit 2.1.2Document4 pagesMicro Programmed Control Unit 2.1.2Ashwani KumarNo ratings yet
- Software Engineering - Functional Point (FP) Analysis - GeeksforGeeksDocument12 pagesSoftware Engineering - Functional Point (FP) Analysis - GeeksforGeeksGanesh PanigrahiNo ratings yet
- Mother BoardDocument29 pagesMother BoardSwayamprakash PatelNo ratings yet
- Computer Organization NotesDocument115 pagesComputer Organization NotesEbbaqhbqNo ratings yet
- Stack Vs QueueDocument1 pageStack Vs QueueSutanu MUKHERJEENo ratings yet
- Chapter 5-The Memory SystemDocument80 pagesChapter 5-The Memory Systemjsanandkumar22No ratings yet
- Ai 2markDocument15 pagesAi 2markrcgramNo ratings yet
- Input / Output Device Inference Engine Knowledge BaseDocument15 pagesInput / Output Device Inference Engine Knowledge BasePuspha Vasanth RNo ratings yet
- SearchingDocument24 pagesSearchingVijaya Prakash RajanalaNo ratings yet
- 2927-Article Text-7193-4-10-20191105Document23 pages2927-Article Text-7193-4-10-20191105Vijaya Prakash RajanalaNo ratings yet
- SearchingDocument24 pagesSearchingVijaya Prakash RajanalaNo ratings yet
- WCE2017 pp211-214 PDFDocument4 pagesWCE2017 pp211-214 PDFVijaya Prakash RajanalaNo ratings yet
- Data Mining: Concepts and Techniques: - Chapter 10Document50 pagesData Mining: Concepts and Techniques: - Chapter 10Vijaya Prakash RajanalaNo ratings yet
- CoCubes The GenZ Employability Report v3Document30 pagesCoCubes The GenZ Employability Report v3Vijaya Prakash Rajanala100% (1)
- Computer - Hardware: Arithmetic and Logic Unit Micro ProcessorDocument24 pagesComputer - Hardware: Arithmetic and Logic Unit Micro Processorkris_gn54No ratings yet
- Why We Model?: Keng Siau University of Nebraska-LincolnDocument8 pagesWhy We Model?: Keng Siau University of Nebraska-LincolnVijaya Prakash RajanalaNo ratings yet
- Graph Coloring - Wikipedia, The Free EncyclopediaDocument17 pagesGraph Coloring - Wikipedia, The Free EncyclopediaVijaya Prakash RajanalaNo ratings yet
- Aata 20110810Document438 pagesAata 20110810Tram VoNo ratings yet
- T & PDocument7 pagesT & PVijaya Prakash RajanalaNo ratings yet
- CPDSDocument63 pagesCPDSVijaya Prakash RajanalaNo ratings yet
- Unit 1 JWFILES PDFDocument52 pagesUnit 1 JWFILES PDFsrilakshmisiriNo ratings yet
- AI Chapter1Document39 pagesAI Chapter1Rahul RahulNo ratings yet
- JournalsDocument1 pageJournalsVijaya Prakash RajanalaNo ratings yet
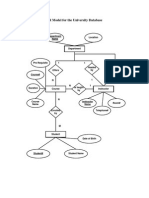
- ER Model For The University Database: Location Department NameDocument1 pageER Model For The University Database: Location Department NameVijaya Prakash RajanalaNo ratings yet
- Unit 1 JWFILES PDFDocument52 pagesUnit 1 JWFILES PDFsrilakshmisiriNo ratings yet
- NLP Starting PagesDocument7 pagesNLP Starting PagesVijaya Prakash RajanalaNo ratings yet
- CorrelationsDocument3 pagesCorrelationsLala AlalNo ratings yet
- 02 Laboratory Exercise 1 PDFDocument1 page02 Laboratory Exercise 1 PDFAeirra Mae Mislang ReyesNo ratings yet
- BIS Advisory Opinion On General Technology Note 3.25.14Document2 pagesBIS Advisory Opinion On General Technology Note 3.25.14dougj1No ratings yet
- Eviews 5 Users Guide PDFDocument2 pagesEviews 5 Users Guide PDFFredNo ratings yet
- 06 - Kinematics PDFDocument60 pages06 - Kinematics PDFFiriz FarizNo ratings yet
- Atmel 24C02Document26 pagesAtmel 24C02kukinjosNo ratings yet
- Truphone User Guide IphoneDocument33 pagesTruphone User Guide IphoneblindexilNo ratings yet
- Conclusions and Scope For Future WorkDocument5 pagesConclusions and Scope For Future WorkPreet ChahalNo ratings yet
- Eurachem Leaflet 17025 EN PDFDocument2 pagesEurachem Leaflet 17025 EN PDFfaheemqcNo ratings yet
- HCS08 Cpu WBTDocument24 pagesHCS08 Cpu WBTSmiley Grace GooNo ratings yet
- IACBOX Datasheet ENDocument2 pagesIACBOX Datasheet ENmpmtechnologyNo ratings yet
- Ease of Doing BusinessDocument3 pagesEase of Doing BusinessAkshayNo ratings yet
- Perl Variables: ScalarsDocument9 pagesPerl Variables: Scalarssravya kothamasuNo ratings yet
- UGF2824 - Elsins-OOW15 - Maris Elsins - Mining AWRDocument101 pagesUGF2824 - Elsins-OOW15 - Maris Elsins - Mining AWRgirglNo ratings yet
- MVH S325BT Owners Manual PDFDocument135 pagesMVH S325BT Owners Manual PDFosmanNo ratings yet
- Cloud Based End-to-End AMI Solution PDFDocument258 pagesCloud Based End-to-End AMI Solution PDFNaresh PattanaikNo ratings yet
- HDP Certified Administrator (HDPCA) : Certification Overview Take The Exam Anytime, AnywhereDocument3 pagesHDP Certified Administrator (HDPCA) : Certification Overview Take The Exam Anytime, AnywheredebkrcNo ratings yet
- Effect of Model and Pretraining Scale On Catastrophic Forgetting in Neural NetworksDocument33 pagesEffect of Model and Pretraining Scale On Catastrophic Forgetting in Neural Networkskai luNo ratings yet
- Passport Management SystemDocument2 pagesPassport Management Systemsobana narayanasamy100% (1)
- Cathay Pacific Airways Assignment-2 QuestionsDocument2 pagesCathay Pacific Airways Assignment-2 Questionssiddharth arkheNo ratings yet
- ManualDocument532 pagesManualosuwiraNo ratings yet
- Codigos Autodesk 2015Document3 pagesCodigos Autodesk 2015RubenCH59No ratings yet
- Jet Way J695as r0.1 SchematicsDocument23 pagesJet Way J695as r0.1 SchematicsGleison GomesNo ratings yet
- Programming Instruction For Hach DR 2800Document7 pagesProgramming Instruction For Hach DR 2800saras unggulNo ratings yet
- Brand Audit of BSNL Mobile ServiceDocument32 pagesBrand Audit of BSNL Mobile ServiceNikita SanghviNo ratings yet