You might also like
- Database Migration From MySql To Oracle 11g Using Golden GateDocument8 pagesDatabase Migration From MySql To Oracle 11g Using Golden GateArshad Taqvi100% (2)
- Central Authentication Service CAS Complete Self-Assessment GuideFrom EverandCentral Authentication Service CAS Complete Self-Assessment GuideNo ratings yet
- 70-223 (Verbeterd) : Number: 070-223 Passing Score: 800 Time Limit: 120 Min File Version: 1.0Document35 pages70-223 (Verbeterd) : Number: 070-223 Passing Score: 800 Time Limit: 120 Min File Version: 1.0smile2meguysNo ratings yet
- How To Create and Test A Sudo Group Policy For Linux and UnixDocument9 pagesHow To Create and Test A Sudo Group Policy For Linux and UnixLikewise Software100% (2)
- Case StudyDocument7 pagesCase StudyÀüsåf MûghãlNo ratings yet
- Real Time Operating System A Complete Guide - 2020 EditionFrom EverandReal Time Operating System A Complete Guide - 2020 EditionNo ratings yet
- Shareplex PresentationDocument44 pagesShareplex Presentation7862005No ratings yet
- Building Websites with VB.NET and DotNetNuke 4From EverandBuilding Websites with VB.NET and DotNetNuke 4Rating: 1 out of 5 stars1/5 (1)
- Lazarus - Chapter 12Document2 pagesLazarus - Chapter 12Francis JSNo ratings yet
- Docu54068 Data Domain Boost OpenStorage Release Notes, 2.6.3.0Document9 pagesDocu54068 Data Domain Boost OpenStorage Release Notes, 2.6.3.0echoicmpNo ratings yet
- OCA 05 - Configuring The Oracle Network EnvironmentDocument46 pagesOCA 05 - Configuring The Oracle Network EnvironmentMuhammad Asghar Khan100% (1)
- 11gR2 Clusterware Technical WP PDFDocument108 pages11gR2 Clusterware Technical WP PDFpavan0927No ratings yet
- SupportSave Logs Collection Using Brocade - CMCNE - CLI - USBDocument8 pagesSupportSave Logs Collection Using Brocade - CMCNE - CLI - USBsatya.chennojuNo ratings yet
- OrangeHRM Code OverviewDocument76 pagesOrangeHRM Code OverviewJaved Pathan50% (2)
- HP-UX 11.0 Installation and Update GuideDocument180 pagesHP-UX 11.0 Installation and Update GuideDaniel BurzawaNo ratings yet
- 5 - Field Technician Networking and StorageDocument12 pages5 - Field Technician Networking and StoragenaveenNo ratings yet
- Silver Oak College of Engineering and Technology Laboratory ManualDocument27 pagesSilver Oak College of Engineering and Technology Laboratory ManualBilal ShaikhNo ratings yet
- Consolidating HP Serviceguard For Linux and Oracle RAC 10g ClustersDocument7 pagesConsolidating HP Serviceguard For Linux and Oracle RAC 10g ClustersShahid Mahmud100% (1)
- Coq 8.10.2 Reference Manual PDFDocument643 pagesCoq 8.10.2 Reference Manual PDFJohn BardakosNo ratings yet
- Systems With WriteBack Smart Flash Cache (WBFC) Enabled Running Into Unnecessary Block Repair During Resilvering Could Cause Data LossDocument4 pagesSystems With WriteBack Smart Flash Cache (WBFC) Enabled Running Into Unnecessary Block Repair During Resilvering Could Cause Data Losskarim ghazouaniNo ratings yet
- DHomesb Chapter 1 - CCNA DiscoveryDocument6 pagesDHomesb Chapter 1 - CCNA DiscoveryAbdullah Al HawajNo ratings yet
- SQL Server - What Are The Differences Between A Clustered and A Non-Clustered Index - Stack OverflowDocument4 pagesSQL Server - What Are The Differences Between A Clustered and A Non-Clustered Index - Stack OverflowchhavishNo ratings yet
- IPMItool commands for server hardware infoDocument2 pagesIPMItool commands for server hardware infogirish979No ratings yet
- 2.5.2.4 Lab - Install A Virtual Machine On A Personal ComputerDocument3 pages2.5.2.4 Lab - Install A Virtual Machine On A Personal Computerluis enrique morel hernadezNo ratings yet
- Return To LibcDocument13 pagesReturn To Libcdarkasterion2009No ratings yet
- Themida - Winlicense Ultra Unpacker 1.4Document270 pagesThemida - Winlicense Ultra Unpacker 1.4VirlanRoberttNo ratings yet
- Configuring Oracle 10g ASM On LinuxDocument27 pagesConfiguring Oracle 10g ASM On LinuxMohd YasinNo ratings yet
- Logical Components of The Host: Vishal Kumar Singh 1DS10IS116Document12 pagesLogical Components of The Host: Vishal Kumar Singh 1DS10IS116Vishal Kumar100% (1)
- Project Report: Submitted byDocument20 pagesProject Report: Submitted byAnkit Ladha100% (1)
- Fencing Overview Redhat Linux FencingDocument8 pagesFencing Overview Redhat Linux FencingSudheer KhanduriNo ratings yet
- Oracle: SceneDocument56 pagesOracle: Sceneelcaso34No ratings yet
- SVCDocument22 pagesSVCjonematNo ratings yet
- Hpe 3Par/Primera Peak/Boss S3Mft S3 "Multi-Function Tool" User's GuideDocument76 pagesHpe 3Par/Primera Peak/Boss S3Mft S3 "Multi-Function Tool" User's GuideAkansha Singh100% (1)
- Cassandra NotesDocument6 pagesCassandra NotesAmit ShahNo ratings yet
- What is a WebLogic Server ClusterDocument16 pagesWhat is a WebLogic Server ClusterVeeru SreNo ratings yet
- EMC AX4-5 Hardware Installation and Troubleshooting GuideDocument60 pagesEMC AX4-5 Hardware Installation and Troubleshooting GuideShivam ChawlaNo ratings yet
- Eucalyptus Nimbus OpenNebulaDocument18 pagesEucalyptus Nimbus OpenNebulaAbhishek Nazare0% (1)
- LAB3Document21 pagesLAB3mahesh0% (1)
- Adding A Second Controller To Create An HA PairDocument24 pagesAdding A Second Controller To Create An HA PairPurushothama GnNo ratings yet
- Mother BoardDocument29 pagesMother BoardSwayamprakash PatelNo ratings yet
- Lecture 3 Operating System StructuresDocument30 pagesLecture 3 Operating System StructuresMarvin BucsitNo ratings yet
- Openstack Object Storage DatasheetDocument1 pageOpenstack Object Storage DatasheetMichael BirkNo ratings yet
- Cisco Aicte Internship: How To Create and Submit Project On Packet Tracer Project Submission Last Date: 3-JUL-2022Document43 pagesCisco Aicte Internship: How To Create and Submit Project On Packet Tracer Project Submission Last Date: 3-JUL-2022AyushNo ratings yet
- OpenCL Best Practices GuideDocument54 pagesOpenCL Best Practices Guideperdo_tempoNo ratings yet
- Scsi Design Analysis 2.6 v2Document45 pagesScsi Design Analysis 2.6 v2amit4gNo ratings yet
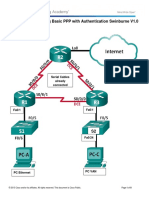
- 3.4.1.5 Lab - Troubleshooting Basic PPP With Authentication Swinburne V1.0Document8 pages3.4.1.5 Lab - Troubleshooting Basic PPP With Authentication Swinburne V1.0Ishu GaneshaMuralidharanNo ratings yet
- Understanding The Linux Kernel: From I/O Ports To Process Management - Daniel P. BovetDocument5 pagesUnderstanding The Linux Kernel: From I/O Ports To Process Management - Daniel P. BovethyjixexiNo ratings yet
- Access Database and Query Data in CDocument88 pagesAccess Database and Query Data in CdasskimyahoocomNo ratings yet
- Using OpenOCD JTAG in Android Kernel DebuggingDocument42 pagesUsing OpenOCD JTAG in Android Kernel DebuggingSyafiq Z ZulNo ratings yet
- Breaking The Mono Alphabetic Substitution Cipher: (../INDEX - PHP) Cryptography Lab (../index - PHP)Document3 pagesBreaking The Mono Alphabetic Substitution Cipher: (../INDEX - PHP) Cryptography Lab (../index - PHP)ananthNo ratings yet
- 1 Openstack Neutron Distributed Virtual RouterDocument11 pages1 Openstack Neutron Distributed Virtual RouterShabeer UppotungalNo ratings yet
- Assignment 2 CSCI235Document4 pagesAssignment 2 CSCI235Aidan AndrewsNo ratings yet
- Project 1 Yong Joseph KukwaDocument15 pagesProject 1 Yong Joseph Kukwayong joekayNo ratings yet
- POC Linux7 Multinode GFS2 Cluster On CentOS 7.3Document69 pagesPOC Linux7 Multinode GFS2 Cluster On CentOS 7.3kjell_furnesNo ratings yet
- Writing CSH Shell ScriptsDocument36 pagesWriting CSH Shell ScriptsMuhidin DelomarNo ratings yet
- Chapter 2 COM101Document5 pagesChapter 2 COM101Christean Val Bayani ValezaNo ratings yet
- Assignment 2 - SolutionDocument3 pagesAssignment 2 - SolutionKhaled NadyNo ratings yet
- Halcon 11 Brochure EnglishDocument20 pagesHalcon 11 Brochure EnglishSANKPLYNo ratings yet
- Inventory Pc2013Document3 pagesInventory Pc2013wizjimNo ratings yet
- Quickspecs: HP Pro Tower 290 G9 Desktop PCDocument35 pagesQuickspecs: HP Pro Tower 290 G9 Desktop PCdeadliner11No ratings yet
- Storage Technology BasicsDocument193 pagesStorage Technology BasicsphanisanyNo ratings yet
- Qs ManualDocument98 pagesQs ManualAbdul SattarNo ratings yet
- Developer ReferenceDocument118 pagesDeveloper ReferenceNomosflo FloresNo ratings yet
- Solidworks Hardware Recommendations - 2016 UpdateDocument16 pagesSolidworks Hardware Recommendations - 2016 UpdateAn CarNo ratings yet
- GEOVIA InSite 4.7 SystemRequirementsDocument2 pagesGEOVIA InSite 4.7 SystemRequirementsAxel VincesNo ratings yet
- SATURN v11.3.12 Manual (Main) PDFDocument1,009 pagesSATURN v11.3.12 Manual (Main) PDFLeonardo rojoNo ratings yet
- Computer System and ArchitectureDocument17 pagesComputer System and ArchitectureDeepak Kumar GuptaNo ratings yet
- Application of Disruptive Technologies in Business: Mba (M&S) Section-B Mba (RM) Section-ADocument18 pagesApplication of Disruptive Technologies in Business: Mba (M&S) Section-B Mba (RM) Section-AVarun LalwaniNo ratings yet
- Computing in A Parallel UniverseDocument6 pagesComputing in A Parallel UniverseMayeth MacedaNo ratings yet
- Oracle BI EE Architecture Deploymentv6Document22 pagesOracle BI EE Architecture Deploymentv6Rajender DudduNo ratings yet
- CPU Power User Buyer's Guide MemoryDocument112 pagesCPU Power User Buyer's Guide MemoryMac TabilisNo ratings yet
- Lenovo Thinksystem Sr590 Server (Xeon SP Gen 1) : Product GuideDocument62 pagesLenovo Thinksystem Sr590 Server (Xeon SP Gen 1) : Product Guideahmar.hp1212No ratings yet
- Ipp - Developer Reference - 2021.7 773258 773259Document1,801 pagesIpp - Developer Reference - 2021.7 773258 773259shadowattackNo ratings yet
- ENSP V100R001C00 Software Installation GuideDocument10 pagesENSP V100R001C00 Software Installation GuideUlap EdardnaNo ratings yet
- Assignment - 1Document6 pagesAssignment - 1Abbas HasanNo ratings yet
- HP All in One ComputerDocument2 pagesHP All in One ComputerDenis Shepherd KimathiNo ratings yet
- Stid 337Document3 pagesStid 337Hakan SyblNo ratings yet
- HP 17-2280NRDocument2 pagesHP 17-2280NRabhi4991No ratings yet
- Cpu BossDocument12 pagesCpu Bossheart_bglNo ratings yet
- OS - Unit 1Document67 pagesOS - Unit 1Pawan NaniNo ratings yet
- Debugger PpcqoriqDocument90 pagesDebugger Ppcqoriqcarver_uaNo ratings yet
- Acer Aspire A514-52G: Result InformationDocument5 pagesAcer Aspire A514-52G: Result InformationDedi IrwantoNo ratings yet
- CASI SolverDocument23 pagesCASI SolverJohney TanNo ratings yet
- Iphone Forensics 2009Document105 pagesIphone Forensics 2009cjhhkmnvjqwkcdNo ratings yet
- MS Word FundamentalsDocument72 pagesMS Word FundamentalsMohit TiwariNo ratings yet
- The 7 Habits of Highly Effective People: The Infographics EditionFrom EverandThe 7 Habits of Highly Effective People: The Infographics EditionRating: 4 out of 5 stars4/5 (2475)
- Think This, Not That: 12 Mindshifts to Breakthrough Limiting Beliefs and Become Who You Were Born to BeFrom EverandThink This, Not That: 12 Mindshifts to Breakthrough Limiting Beliefs and Become Who You Were Born to BeNo ratings yet
- Summary: The 5AM Club: Own Your Morning. Elevate Your Life. by Robin Sharma: Key Takeaways, Summary & AnalysisFrom EverandSummary: The 5AM Club: Own Your Morning. Elevate Your Life. by Robin Sharma: Key Takeaways, Summary & AnalysisRating: 4.5 out of 5 stars4.5/5 (22)
- The 5 Second Rule: Transform your Life, Work, and Confidence with Everyday CourageFrom EverandThe 5 Second Rule: Transform your Life, Work, and Confidence with Everyday CourageRating: 5 out of 5 stars5/5 (7)
- Indistractable: How to Control Your Attention and Choose Your LifeFrom EverandIndistractable: How to Control Your Attention and Choose Your LifeRating: 3.5 out of 5 stars3.5/5 (4)
- Eat That Frog!: 21 Great Ways to Stop Procrastinating and Get More Done in Less TimeFrom EverandEat That Frog!: 21 Great Ways to Stop Procrastinating and Get More Done in Less TimeRating: 4.5 out of 5 stars4.5/5 (3224)
- No Bad Parts: Healing Trauma and Restoring Wholeness with the Internal Family Systems ModelFrom EverandNo Bad Parts: Healing Trauma and Restoring Wholeness with the Internal Family Systems ModelRating: 5 out of 5 stars5/5 (2)
- The Coaching Habit: Say Less, Ask More & Change the Way You Lead ForeverFrom EverandThe Coaching Habit: Say Less, Ask More & Change the Way You Lead ForeverRating: 4.5 out of 5 stars4.5/5 (186)
- The One Thing: The Surprisingly Simple Truth Behind Extraordinary ResultsFrom EverandThe One Thing: The Surprisingly Simple Truth Behind Extraordinary ResultsRating: 4.5 out of 5 stars4.5/5 (708)
- Summary of Atomic Habits: An Easy and Proven Way to Build Good Habits and Break Bad Ones by James ClearFrom EverandSummary of Atomic Habits: An Easy and Proven Way to Build Good Habits and Break Bad Ones by James ClearRating: 4.5 out of 5 stars4.5/5 (557)
- The Millionaire Fastlane: Crack the Code to Wealth and Live Rich for a LifetimeFrom EverandThe Millionaire Fastlane: Crack the Code to Wealth and Live Rich for a LifetimeRating: 4 out of 5 stars4/5 (1)
- The Compound Effect by Darren Hardy - Book Summary: Jumpstart Your Income, Your Life, Your SuccessFrom EverandThe Compound Effect by Darren Hardy - Book Summary: Jumpstart Your Income, Your Life, Your SuccessRating: 5 out of 5 stars5/5 (456)
- Uptime: A Practical Guide to Personal Productivity and WellbeingFrom EverandUptime: A Practical Guide to Personal Productivity and WellbeingNo ratings yet
- Get to the Point!: Sharpen Your Message and Make Your Words MatterFrom EverandGet to the Point!: Sharpen Your Message and Make Your Words MatterRating: 4.5 out of 5 stars4.5/5 (280)
- Quantum Success: 7 Essential Laws for a Thriving, Joyful, and Prosperous Relationship with Work and MoneyFrom EverandQuantum Success: 7 Essential Laws for a Thriving, Joyful, and Prosperous Relationship with Work and MoneyRating: 5 out of 5 stars5/5 (38)
- Think Faster, Talk Smarter: How to Speak Successfully When You're Put on the SpotFrom EverandThink Faster, Talk Smarter: How to Speak Successfully When You're Put on the SpotRating: 5 out of 5 stars5/5 (1)
- Own Your Past Change Your Future: A Not-So-Complicated Approach to Relationships, Mental Health & WellnessFrom EverandOwn Your Past Change Your Future: A Not-So-Complicated Approach to Relationships, Mental Health & WellnessRating: 5 out of 5 stars5/5 (85)
- What's Best Next: How the Gospel Transforms the Way You Get Things DoneFrom EverandWhat's Best Next: How the Gospel Transforms the Way You Get Things DoneRating: 4.5 out of 5 stars4.5/5 (33)
- Summary: Hidden Potential: The Science of Achieving Greater Things By Adam Grant: Key Takeaways, Summary and AnalysisFrom EverandSummary: Hidden Potential: The Science of Achieving Greater Things By Adam Grant: Key Takeaways, Summary and AnalysisRating: 4.5 out of 5 stars4.5/5 (15)
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveFrom EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNo ratings yet
- The High 5 Habit: Take Control of Your Life with One Simple HabitFrom EverandThe High 5 Habit: Take Control of Your Life with One Simple HabitRating: 5 out of 5 stars5/5 (1)
- Mastering Productivity: Everything You Need to Know About Habit FormationFrom EverandMastering Productivity: Everything You Need to Know About Habit FormationRating: 4.5 out of 5 stars4.5/5 (21)
- Think Remarkable: 9 Paths to Transform Your Life and Make a DifferenceFrom EverandThink Remarkable: 9 Paths to Transform Your Life and Make a DifferenceNo ratings yet
- How to Be Better at Almost Everything: Learn Anything Quickly, Stack Your Skills, DominateFrom EverandHow to Be Better at Almost Everything: Learn Anything Quickly, Stack Your Skills, DominateRating: 4.5 out of 5 stars4.5/5 (856)
- Seeing What Others Don't: The Remarkable Ways We Gain InsightsFrom EverandSeeing What Others Don't: The Remarkable Ways We Gain InsightsRating: 4 out of 5 stars4/5 (288)
- Growth Mindset: 7 Secrets to Destroy Your Fixed Mindset and Tap into Your Psychology of Success with Self Discipline, Emotional Intelligence and Self ConfidenceFrom EverandGrowth Mindset: 7 Secrets to Destroy Your Fixed Mindset and Tap into Your Psychology of Success with Self Discipline, Emotional Intelligence and Self ConfidenceRating: 4.5 out of 5 stars4.5/5 (561)
- The Secret of The Science of Getting Rich: Change Your Beliefs About Success and Money to Create The Life You WantFrom EverandThe Secret of The Science of Getting Rich: Change Your Beliefs About Success and Money to Create The Life You WantRating: 5 out of 5 stars5/5 (34)