You might also like
- Ultrasonic Inspection Standards for Wrought MetalsDocument44 pagesUltrasonic Inspection Standards for Wrought Metalsdomsoneng100% (1)
- SPSS2 Workshop Handout 20200917Document17 pagesSPSS2 Workshop Handout 20200917kannan_r02No ratings yet
- Example How To Perform Multiple Regression Analysis Using SPSS StatisticsDocument14 pagesExample How To Perform Multiple Regression Analysis Using SPSS StatisticsMunirul Ula100% (1)
- Multiple RegressionDocument31 pagesMultiple Regressionkhem_singhNo ratings yet
- Access Database Objects: IBS, Chennai II IT Workshop On MS Access October 3-6, 2008 #Document36 pagesAccess Database Objects: IBS, Chennai II IT Workshop On MS Access October 3-6, 2008 #rahulNo ratings yet
- Regression Analysis | April 1Document8 pagesRegression Analysis | April 1VICKY GAURAVNo ratings yet
- Final Biomechanics of Edentulous StateDocument114 pagesFinal Biomechanics of Edentulous StateSnigdha SahaNo ratings yet
- EDP/LRP Well Intervention System OverviewDocument22 pagesEDP/LRP Well Intervention System OverviewJerome LIKIBINo ratings yet
- Database Design: - Tables - Constraints - Relationships - QueriesDocument9 pagesDatabase Design: - Tables - Constraints - Relationships - QueriesrahulNo ratings yet
- Logistic RegressionDocument30 pagesLogistic RegressionSaba Khan100% (1)
- Method Statement of Static Equipment ErectionDocument20 pagesMethod Statement of Static Equipment Erectionsarsan nedumkuzhi mani100% (4)
- Icfai: Information Systems DevelopmentDocument20 pagesIcfai: Information Systems DevelopmentrahulNo ratings yet
- Multivariate Analysis Techniques for Market SegmentationDocument57 pagesMultivariate Analysis Techniques for Market Segmentationsuduku007100% (1)
- What is a Sample SizeDocument5 pagesWhat is a Sample Sizerigan100% (1)
- Dbms 6 Er ModelingDocument91 pagesDbms 6 Er ModelingrahulNo ratings yet
- Peter DruckerDocument63 pagesPeter DruckerrahulNo ratings yet
- Predict Binary Outcomes with Logistic RegressionDocument11 pagesPredict Binary Outcomes with Logistic RegressionOsama RiazNo ratings yet
- Sample Size DeterminationDocument19 pagesSample Size Determinationsanchi rajputNo ratings yet
- Accident Causation Theories and ConceptDocument4 pagesAccident Causation Theories and ConceptShayne Aira AnggongNo ratings yet
- 5682 - 4433 - Factor & Cluster AnalysisDocument22 pages5682 - 4433 - Factor & Cluster AnalysisSubrat NandaNo ratings yet
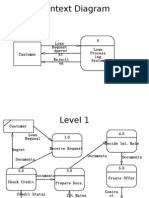
- Context Diagram: Loan Request Approv Al Rejecti On 0Document4 pagesContext Diagram: Loan Request Approv Al Rejecti On 0rahulNo ratings yet
- 16 BPI V FernandezDocument1 page16 BPI V FernandezAngelica Joyce BelenNo ratings yet
- Chirala, Andhra PradeshDocument7 pagesChirala, Andhra PradeshRam KumarNo ratings yet
- Analysis Analysis: Multivariat E Multivariat EDocument12 pagesAnalysis Analysis: Multivariat E Multivariat Epopat vishalNo ratings yet
- AnovaDocument49 pagesAnovabrianmore10No ratings yet
- Diane L. Fairclough - Design and Analysis of QualiDocument426 pagesDiane L. Fairclough - Design and Analysis of Qualiedwardeduardo10No ratings yet
- Parametric Statistical Analysis in SPSSDocument56 pagesParametric Statistical Analysis in SPSSKarl John A. GalvezNo ratings yet
- Assumptions of Multiple Regression AnalysisDocument4 pagesAssumptions of Multiple Regression AnalysisSheikh Aakif100% (1)
- VSP-12Way - Is Rev.03Document55 pagesVSP-12Way - Is Rev.03Marcelo AlmeidaNo ratings yet
- Multinomial Logistic Regression - R Data Analysis Examples - IDRE StatsDocument8 pagesMultinomial Logistic Regression - R Data Analysis Examples - IDRE StatsDina NadhirahNo ratings yet
- Anova (Quality Management)Document62 pagesAnova (Quality Management)yttan1116No ratings yet
- Correlation and RegressionDocument31 pagesCorrelation and RegressionDela Cruz GenesisNo ratings yet
- Recommended Sample Size For Conducting Exploratory Factor AnalysiDocument11 pagesRecommended Sample Size For Conducting Exploratory Factor AnalysimedijumNo ratings yet
- Logistic Regression AnalysisDocument16 pagesLogistic Regression AnalysisPIE TUTORSNo ratings yet
- Random ForestDocument83 pagesRandom ForestBharath Reddy MannemNo ratings yet
- Linear RegressionDocument27 pagesLinear RegressionAmit SinghNo ratings yet
- Inferential Statistics in Psychology3Document11 pagesInferential Statistics in Psychology3ailui202No ratings yet
- SPSS Binary Logistic Regression Demo 1 TerminateDocument22 pagesSPSS Binary Logistic Regression Demo 1 Terminatefahadraja78No ratings yet
- R Lesson (1 of 2) PDFDocument182 pagesR Lesson (1 of 2) PDFVince AlmoreNo ratings yet
- Runs Test for Randomness ExplainedDocument5 pagesRuns Test for Randomness ExplaineddilpalsNo ratings yet
- Application of Ordinal Logistic Regression in The Study of Students' Performance PDFDocument11 pagesApplication of Ordinal Logistic Regression in The Study of Students' Performance PDFAlexander DeckerNo ratings yet
- RegressionDocument19 pagesRegressionShardul PatelNo ratings yet
- Survival Analysis GuideDocument133 pagesSurvival Analysis GuideRobi LeoNo ratings yet
- Multiple Regression AnalysisDocument77 pagesMultiple Regression Analysishayati5823No ratings yet
- Applied Nonparametric Statistics 2Document15 pagesApplied Nonparametric Statistics 2Shan TiNo ratings yet
- Multivariate Analysis TechniquesDocument20 pagesMultivariate Analysis Techniquesrahul_arora_20No ratings yet
- Linear Regression Assumptions and Diagnostics in R - Essentials - Articles - STHDADocument21 pagesLinear Regression Assumptions and Diagnostics in R - Essentials - Articles - STHDAicen00bNo ratings yet
- Estimation of Sample SizeDocument33 pagesEstimation of Sample SizekhoafnnNo ratings yet
- Generalized Linear Models: Simon Jackman Stanford UniversityDocument7 pagesGeneralized Linear Models: Simon Jackman Stanford UniversityababacarbaNo ratings yet
- Multiple RegressionDocument37 pagesMultiple RegressionMichael ThungNo ratings yet
- Regression Modeling Strategies: Frank E. Harrell, JRDocument11 pagesRegression Modeling Strategies: Frank E. Harrell, JRCipriana Gîrbea50% (2)
- Handleiding Spss Multinomial Logit RegressionDocument35 pagesHandleiding Spss Multinomial Logit RegressionbartvansantenNo ratings yet
- Lecture 11 Factor AnalysisDocument21 pagesLecture 11 Factor AnalysisKhurram SherazNo ratings yet
- Research Methods & Reporting: STARD 2015: An Updated List of Essential Items For Reporting Diagnostic Accuracy StudiesDocument9 pagesResearch Methods & Reporting: STARD 2015: An Updated List of Essential Items For Reporting Diagnostic Accuracy StudiesJorge Villoslada Terrones100% (1)
- Data Analysis With SASDocument353 pagesData Analysis With SASVictoria Liendo100% (1)
- Population - Entire Group of Individuals About Which We Want Information. Sample - Part of The Population From Which We Actually Collect InformationDocument5 pagesPopulation - Entire Group of Individuals About Which We Want Information. Sample - Part of The Population From Which We Actually Collect Informationlauren smithNo ratings yet
- What Statistical Analysis Should I UseDocument3 pagesWhat Statistical Analysis Should I UseeswarlalbkNo ratings yet
- BCBB Workshop Applied Statistics II-2 & IIIDocument59 pagesBCBB Workshop Applied Statistics II-2 & IIIMagnifico FangaWoroNo ratings yet
- Logistic RegressionDocument21 pagesLogistic Regressioncvrpraveen100% (1)
- Handle Missing DataDocument32 pagesHandle Missing DataGuja NagiNo ratings yet
- Notes on Linear Regression ModelsDocument46 pagesNotes on Linear Regression Modelsken_ng333No ratings yet
- Types of Statistical AnalysisDocument2 pagesTypes of Statistical AnalysispunojanielynNo ratings yet
- Regression Analysis Predicts Travel TimeDocument12 pagesRegression Analysis Predicts Travel Timekuashask2No ratings yet
- Logistic Regression TutorialDocument25 pagesLogistic Regression TutorialDaphneNo ratings yet
- L5 Logistic Regression (2011)Document55 pagesL5 Logistic Regression (2011)woihon100% (1)
- Logistics RegressionDocument14 pagesLogistics RegressiondownloadarticleNo ratings yet
- Graphical Representation of Multivariate DataFrom EverandGraphical Representation of Multivariate DataPeter C. C. WangNo ratings yet
- Logistic RegressionDocument71 pagesLogistic Regressionanil_kumar31847540% (1)
- ARIMA ForecastingDocument9 pagesARIMA Forecastingilkom12No ratings yet
- Class 7Document42 pagesClass 7rishabhNo ratings yet
- BlackberryDocument6 pagesBlackberryneer4scridNo ratings yet
- MF-Equity Presentation Q2 2011Document17 pagesMF-Equity Presentation Q2 2011rahulNo ratings yet
- Icfai: Enterprise-Wide Information SystemsDocument45 pagesIcfai: Enterprise-Wide Information SystemsrahulNo ratings yet
- The Dream Every Company Wants To BeDocument16 pagesThe Dream Every Company Wants To BerahulNo ratings yet
- 6 SigmaDocument27 pages6 SigmarahulNo ratings yet
- Database Management System - ClassroomDocument39 pagesDatabase Management System - ClassroomrahulNo ratings yet
- MRP - Final ReportDocument127 pagesMRP - Final ReportrahulNo ratings yet
- Structured Query LanguageDocument45 pagesStructured Query LanguagerahulNo ratings yet
- Process QuizDocument32 pagesProcess QuizrahulNo ratings yet
- Structured DevelopmentDocument43 pagesStructured DevelopmentrahulNo ratings yet
- DFD Common MistakeDocument14 pagesDFD Common Mistakerahul100% (2)
- NormalisationDocument18 pagesNormalisationrahul0% (1)
- Book AcquisitionDocument12 pagesBook AcquisitionrahulNo ratings yet
- Supply Chain ManagementDocument19 pagesSupply Chain ManagementrahulNo ratings yet
- Multivariate AnalysisDocument34 pagesMultivariate AnalysisrahulNo ratings yet
- Ant AnalysisDocument18 pagesAnt AnalysisrahulNo ratings yet
- Attitude Measurementfinal1Document45 pagesAttitude Measurementfinal1rahulNo ratings yet
- Ant AnalysisDocument18 pagesAnt AnalysisrahulNo ratings yet
- Research DesignDocument35 pagesResearch DesignrahulNo ratings yet
- Why Study Resarch 2Document35 pagesWhy Study Resarch 2rahulNo ratings yet
- Class Factor AnalysisDocument21 pagesClass Factor AnalysisrahulNo ratings yet
- Measurenent ScalesDocument52 pagesMeasurenent ScalesrahulNo ratings yet
- Why Study Research 1Document41 pagesWhy Study Research 1rahulNo ratings yet
- TransformerDocument50 pagesTransformerبنیاد پرست100% (8)
- Assignment 2 - p1 p2 p3Document16 pagesAssignment 2 - p1 p2 p3api-31192579150% (2)
- Laporan Mutasi Inventory GlobalDocument61 pagesLaporan Mutasi Inventory GlobalEustas D PickNo ratings yet
- Curriculum Vitae 2010Document11 pagesCurriculum Vitae 2010ajombileNo ratings yet
- Kuliah Statistik Inferensial Ke4: Simple Linear RegressionDocument74 pagesKuliah Statistik Inferensial Ke4: Simple Linear Regressionvivian indrioktaNo ratings yet
- Road Safety GOs & CircularsDocument39 pagesRoad Safety GOs & CircularsVizag Roads100% (1)
- LeasingDocument2 pagesLeasingfollow_da_great100% (2)
- Nuxeo Platform 5.6 UserGuideDocument255 pagesNuxeo Platform 5.6 UserGuidePatrick McCourtNo ratings yet
- Dewatering Construction Sites Below Water TableDocument6 pagesDewatering Construction Sites Below Water TableSOMSUBHRA SINGHANo ratings yet
- Lea 201 Coverage Topics in Midterm ExamDocument40 pagesLea 201 Coverage Topics in Midterm Examshielladelarosa26No ratings yet
- Corena s2 p150 - Msds - 01185865Document17 pagesCorena s2 p150 - Msds - 01185865Javier LerinNo ratings yet
- Guardplc Certified Function Blocks - Basic Suite: Catalog Number 1753-CfbbasicDocument110 pagesGuardplc Certified Function Blocks - Basic Suite: Catalog Number 1753-CfbbasicTarun BharadwajNo ratings yet
- Exercise Manual For Course 973: Programming C# Extended Features: Hands-OnDocument122 pagesExercise Manual For Course 973: Programming C# Extended Features: Hands-OnAdrian GorganNo ratings yet
- Payroll Canadian 1st Edition Dryden Test BankDocument38 pagesPayroll Canadian 1st Edition Dryden Test Bankriaozgas3023100% (14)
- Java MCQ questions and answersDocument65 pagesJava MCQ questions and answersShermin FatmaNo ratings yet
- Triblender Wet Savoury F3218Document32 pagesTriblender Wet Savoury F3218danielagomezga_45545100% (1)
- Terminología Sobre Reducción de Riesgo de DesastresDocument43 pagesTerminología Sobre Reducción de Riesgo de DesastresJ. Mario VeraNo ratings yet
- What Role Can IS Play in The Pharmaceutical Industry?Document4 pagesWhat Role Can IS Play in The Pharmaceutical Industry?Đức NguyễnNo ratings yet
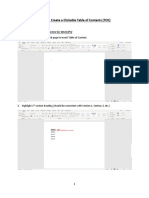
- How To: Create A Clickable Table of Contents (TOC)Document10 pagesHow To: Create A Clickable Table of Contents (TOC)Xuan Mai Nguyen ThiNo ratings yet
- Pass Issuance Receipt: Now You Can Also Buy This Pass On Paytm AppDocument1 pagePass Issuance Receipt: Now You Can Also Buy This Pass On Paytm AppAnoop SharmaNo ratings yet
- I-Parcel User GuideDocument57 pagesI-Parcel User GuideBrian GrayNo ratings yet
- Sierra Wireless AirPrimeDocument2 pagesSierra Wireless AirPrimeAminullah -No ratings yet