You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Leonard Nadler' ModelDocument3 pagesLeonard Nadler' ModelPiet Gabz67% (3)
- Enhancing Nurses Pain Assessment To Improve.11Document2 pagesEnhancing Nurses Pain Assessment To Improve.11Na d'Nazaie CodeNo ratings yet
- Model Klasifikasi Menggunakan Metode Regresi Logistik Dan Multivariate Adaptive Regression Splines (Mars) (Studi Kasus: Data Survei Biaya Hidup (SBH) Kota Kediri Tahun 2012)Document12 pagesModel Klasifikasi Menggunakan Metode Regresi Logistik Dan Multivariate Adaptive Regression Splines (Mars) (Studi Kasus: Data Survei Biaya Hidup (SBH) Kota Kediri Tahun 2012)Na d'Nazaie CodeNo ratings yet
- FallsintheElderly PDFDocument12 pagesFallsintheElderly PDFNa d'Nazaie CodeNo ratings yet
- NIH Public Access: Interventions To Improve Walking in Older AdultsDocument13 pagesNIH Public Access: Interventions To Improve Walking in Older AdultsNa d'Nazaie CodeNo ratings yet
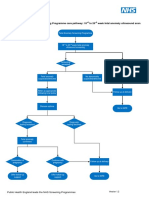
- FASP Fetal Anomaly Ultrasound Screening Pathwayv12Document1 pageFASP Fetal Anomaly Ultrasound Screening Pathwayv12Na d'Nazaie CodeNo ratings yet
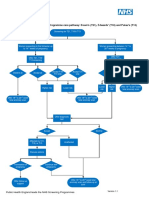
- FASPDownsT21EdwardsT18andPatausT13pathway11 PDFDocument1 pageFASPDownsT21EdwardsT18andPatausT13pathway11 PDFNa d'Nazaie CodeNo ratings yet
- FallsintheElderly PDFDocument12 pagesFallsintheElderly PDFNa d'Nazaie CodeNo ratings yet
- 2 10 1 PBDocument3 pages2 10 1 PBNa d'Nazaie CodeNo ratings yet
- R1 - Vo3No4 KJHDocument14 pagesR1 - Vo3No4 KJHNa d'Nazaie CodeNo ratings yet
- ITS Undergraduate 18940 Bibliographypdf PDFDocument2 pagesITS Undergraduate 18940 Bibliographypdf PDFNa d'Nazaie CodeNo ratings yet
- Kusiima Chs Masters Abstract PDFDocument3 pagesKusiima Chs Masters Abstract PDFNa d'Nazaie CodeNo ratings yet
- Rita Dwi HartantiDocument9 pagesRita Dwi HartantiNa d'Nazaie CodeNo ratings yet
- Kualitas HidupDocument8 pagesKualitas Hidupsrihandayani1984No ratings yet
- TB Riskfactors SocialdeterminantsDocument7 pagesTB Riskfactors SocialdeterminantsNa d'Nazaie CodeNo ratings yet
- Dochtermann Jenkins ResponseDocument11 pagesDochtermann Jenkins ResponseNa d'Nazaie CodeNo ratings yet
- 20Document3 pages20Na d'Nazaie CodeNo ratings yet
- JurnalDocument87 pagesJurnalNa d'Nazaie CodeNo ratings yet
- WOQOL Measuring QV MentalDocument15 pagesWOQOL Measuring QV MentalpenfoNo ratings yet
- Ipi200729 PDFDocument14 pagesIpi200729 PDFNa d'Nazaie CodeNo ratings yet
- Power and Minimal Sample Size For Multivariate Analysis of MicroarraysDocument1 pagePower and Minimal Sample Size For Multivariate Analysis of MicroarraysNa d'Nazaie CodeNo ratings yet
- Circulation 2014 Hansen 1859 67Document15 pagesCirculation 2014 Hansen 1859 67Na d'Nazaie CodeNo ratings yet
- Calculating The Sample Size of Multivariate Populations: Norms of RepresentationDocument6 pagesCalculating The Sample Size of Multivariate Populations: Norms of RepresentationNa d'Nazaie CodeNo ratings yet
- Kuesioner SSQDocument15 pagesKuesioner SSQNa d'Nazaie Code100% (3)
- Circulation 2011 Kilgannon 2717 22Document7 pagesCirculation 2011 Kilgannon 2717 22Na d'Nazaie CodeNo ratings yet
- Toxicon: SciencedirectDocument14 pagesToxicon: SciencedirectNa d'Nazaie CodeNo ratings yet
- Circulation 2014 Hansen 1859 67Document15 pagesCirculation 2014 Hansen 1859 67Na d'Nazaie CodeNo ratings yet
- 995 FullDocument8 pages995 FullNa d'Nazaie CodeNo ratings yet
- The Blind MotherDocument2 pagesThe Blind MotherNa d'Nazaie CodeNo ratings yet
- Artificial Intelligence and Expert Systems: Management Information Systems, 4 EditionDocument27 pagesArtificial Intelligence and Expert Systems: Management Information Systems, 4 Editionabhi7219No ratings yet
- MICRF230Document20 pagesMICRF230Amador Garcia IIINo ratings yet
- Grade 8 Least Mastered Competencies Sy 2020-2021: Handicraft Making Dressmaking CarpentryDocument9 pagesGrade 8 Least Mastered Competencies Sy 2020-2021: Handicraft Making Dressmaking CarpentryHJ HJNo ratings yet
- E Business - Module 1Document75 pagesE Business - Module 1Kannan V KumarNo ratings yet
- 1980 - William Golding - Rites of PassageDocument161 pages1980 - William Golding - Rites of PassageZi Knight100% (1)
- TOPIC 2 - Fans, Blowers and Air CompressorDocument69 pagesTOPIC 2 - Fans, Blowers and Air CompressorCllyan ReyesNo ratings yet
- Green ChemistryDocument17 pagesGreen ChemistryAaditya RamanNo ratings yet
- The Eye WorksheetDocument3 pagesThe Eye WorksheetCally ChewNo ratings yet
- Porsche Dealer Application DataDocument3 pagesPorsche Dealer Application DataEdwin UcheNo ratings yet
- PTD30600301 4202 PDFDocument3 pagesPTD30600301 4202 PDFwoulkanNo ratings yet
- Water Works RTADocument15 pagesWater Works RTAalfaza3No ratings yet
- Manual ML 1675 PDFDocument70 pagesManual ML 1675 PDFSergio de BedoutNo ratings yet
- Grade 8 Science Text Book 61fb9947be91fDocument289 pagesGrade 8 Science Text Book 61fb9947be91fNadarajah PragatheeswarNo ratings yet
- GMDSSDocument1 pageGMDSSRahul rajeshNo ratings yet
- Anglo Afghan WarsDocument79 pagesAnglo Afghan WarsNisar AhmadNo ratings yet
- JurnalDocument12 pagesJurnalSandy Ronny PurbaNo ratings yet
- 525 2383 2 PBDocument5 pages525 2383 2 PBiwang saudjiNo ratings yet
- Zanussi Parts & Accessories - Search Results3 - 91189203300Document4 pagesZanussi Parts & Accessories - Search Results3 - 91189203300Melissa WilliamsNo ratings yet
- LANY Lyrics: "Thru These Tears" LyricsDocument2 pagesLANY Lyrics: "Thru These Tears" LyricsAnneNo ratings yet
- Assignment # 1 POMDocument10 pagesAssignment # 1 POMnaeemNo ratings yet
- Hydraulic Excavator: Engine WeightsDocument28 pagesHydraulic Excavator: Engine WeightsFelipe Pisklevits LaubeNo ratings yet
- Def - Pemf Chronic Low Back PainDocument17 pagesDef - Pemf Chronic Low Back PainFisaudeNo ratings yet
- Part TOEFLDocument7 pagesPart TOEFLFrisca Rahma DwinantiNo ratings yet
- Traulsen RHT-AHT Reach in Refrigerator WUT Glass DoorDocument2 pagesTraulsen RHT-AHT Reach in Refrigerator WUT Glass Doorwsfc-ebayNo ratings yet
- Forlong - Rivers of LifeDocument618 pagesForlong - Rivers of LifeCelephaïs Press / Unspeakable Press (Leng)100% (15)
- Inglês - Advérbios - Adverbs.Document18 pagesInglês - Advérbios - Adverbs.KhyashiNo ratings yet
- Fisker Karma - Battery 12V Jump StartDocument2 pagesFisker Karma - Battery 12V Jump StartRedacTHORNo ratings yet
- Quiz EditedDocument6 pagesQuiz EditedAbigail LeronNo ratings yet
- The Origin, Nature, and Challenges of Area Studies in The United StatesDocument22 pagesThe Origin, Nature, and Challenges of Area Studies in The United StatesannsaralondeNo ratings yet