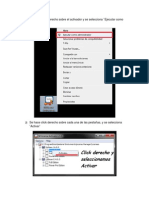
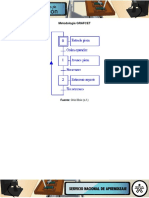
You might also like
- 100000anexo Apartado ProyectoDocument2 pages100000anexo Apartado ProyectoLina Rodriguez CortesNo ratings yet
- How To Install 3rd Party SIM Cards in A TrackLight GPS Tracker SPDocument2 pagesHow To Install 3rd Party SIM Cards in A TrackLight GPS Tracker SPJasonYedufroNo ratings yet
- Lab 4 Del Menos Al Más SignificativoDocument14 pagesLab 4 Del Menos Al Más SignificativoJasonYedufroNo ratings yet
- Manual de Usuario TD BLEDocument51 pagesManual de Usuario TD BLEJasonYedufroNo ratings yet
- MRAS Basado en LyapunovDocument10 pagesMRAS Basado en LyapunovJasonYedufroNo ratings yet
- Formato de Licencias Obligatorias V1Document1 pageFormato de Licencias Obligatorias V1JasonYedufroNo ratings yet
- RT Control Notas Metodos1Document47 pagesRT Control Notas Metodos1JasonYedufroNo ratings yet
- Taller 1 Ejer Cici Os SandraDocument3 pagesTaller 1 Ejer Cici Os SandraJasonYedufroNo ratings yet
- PrácticasDocument2 pagesPrácticasJasonYedufroNo ratings yet
- Matemáticas Financieras - Tema 1Document57 pagesMatemáticas Financieras - Tema 1JasonYedufroNo ratings yet
- Guía de Instalación de PSPICE 9,2Document24 pagesGuía de Instalación de PSPICE 9,2JasonYedufroNo ratings yet
- Ambardar v01 PDFDocument1,564 pagesAmbardar v01 PDFjandy0820No ratings yet
- Companero Conyuge PDFDocument1 pageCompanero Conyuge PDFKaren Lorena JOYA HERNANDEZNo ratings yet
- Activar Productos National InstrumentsDocument2 pagesActivar Productos National InstrumentsCristian Cabello CarhuasNo ratings yet
- La Capitulación de La Gramática Básica CoreanaDocument4 pagesLa Capitulación de La Gramática Básica CoreanaJasonYedufroNo ratings yet
- Una Trigonometria Analitica, Didactica y Muy Interesante... A Mi Me Gusto!!!Document122 pagesUna Trigonometria Analitica, Didactica y Muy Interesante... A Mi Me Gusto!!!JALSNo ratings yet
- Teoria Espectral Operadores HilbertDocument57 pagesTeoria Espectral Operadores HilbertJasonYedufro100% (1)
- Tabla FDocument2 pagesTabla FJasonYedufroNo ratings yet
- PH Proporciones y Bondad de AjusteDocument23 pagesPH Proporciones y Bondad de AjusteJasonYedufroNo ratings yet
- Tutorial LatexDocument10 pagesTutorial Latexlunatic0No ratings yet
- 120 VERBOS DE ACCION COREANOS QUE DEBES SABER by Koreanyol PDFDocument10 pages120 VERBOS DE ACCION COREANOS QUE DEBES SABER by Koreanyol PDFLinaMarcelaGonzalez80% (5)
- LatexDocument127 pagesLatexNancy Cifuentes EscobarNo ratings yet
- Tablas Normal T y JiDocument1 pageTablas Normal T y JiMauricioRendonNo ratings yet
- Recomendacion-Sonorizacion de Pequeñas y Medianas Instalaciones-Domos y MillenniumDocument52 pagesRecomendacion-Sonorizacion de Pequeñas y Medianas Instalaciones-Domos y MillenniumJorge Martinez100% (1)
- Velocidad DirectrizDocument4 pagesVelocidad DirectrizValerita Silvana Ramirez50% (2)
- Levantamiento Topografico Por Medio de Angulos InterioresDocument5 pagesLevantamiento Topografico Por Medio de Angulos InterioresDaniel Martinez100% (1)
- Sistema Electrico 13Document7 pagesSistema Electrico 13angelNo ratings yet
- Reflex I OnesDocument63 pagesReflex I OnesBrisa Martinez G.No ratings yet
- Tema - (ACV-S07) Foro de Debate Calificado 05 - EP - Distribución de ProbabilidadDocument78 pagesTema - (ACV-S07) Foro de Debate Calificado 05 - EP - Distribución de ProbabilidadLorena Meza100% (1)
- Silogismos Categoricos PDFDocument28 pagesSilogismos Categoricos PDFAndres Acevedo100% (1)
- Formulas Excel Ingles y EspañolDocument10 pagesFormulas Excel Ingles y EspañolDaniel VelasquezNo ratings yet
- Examen de Estadistica Unidad III 1 IntentoDocument7 pagesExamen de Estadistica Unidad III 1 IntentoMarianela RomeroNo ratings yet
- Resumen Tema 8 Diseños de Investigación y Analisis de DatosDocument20 pagesResumen Tema 8 Diseños de Investigación y Analisis de DatosRobertTurnerCoboNo ratings yet
- Procesos MorfodinamicosDocument225 pagesProcesos Morfodinamicosjeremias sprinfielNo ratings yet
- Resueltos Calculo 2Document125 pagesResueltos Calculo 2Felipe U. BarberisNo ratings yet
- Introduccion Al Pensamiento MatematicoDocument38 pagesIntroduccion Al Pensamiento MatematicoCarlos AlvaresNo ratings yet
- Clasificación HidrociclónicaDocument19 pagesClasificación HidrociclónicaGustavo Espinoza RiveraNo ratings yet
- SESIÓN MATEFIN 4 INTERÉS COMPUESTO 2022-1 (Anexo Complementario)Document8 pagesSESIÓN MATEFIN 4 INTERÉS COMPUESTO 2022-1 (Anexo Complementario)Evelyn Chávez GutiérrezNo ratings yet
- FUERZASFISICA4ESODocument20 pagesFUERZASFISICA4ESODiana VehaNo ratings yet
- PT 741Document54 pagesPT 741J Elías JSNo ratings yet
- Sistemas de EcuacionesDocument9 pagesSistemas de EcuacionesMarlon Mattos BeltránNo ratings yet
- MatsupDocument23 pagesMatsupKevin A. ChavarriaNo ratings yet
- Losas Compuestas Metodos Experimentacion DisenoDocument17 pagesLosas Compuestas Metodos Experimentacion DisenoRoberto CeballosNo ratings yet
- Canaleta y Camara de Aquietamiento y DosificacionDocument28 pagesCanaleta y Camara de Aquietamiento y DosificacionSebastian RiquettNo ratings yet
- Movimiento de Los Astros PDFDocument33 pagesMovimiento de Los Astros PDFnoeruaNo ratings yet
- Metodologia GRAFCETDocument9 pagesMetodologia GRAFCETEddy Yohanna Martinez RoaNo ratings yet
- Ensayo de Impacto Charpy de Muestras PequeñasDocument9 pagesEnsayo de Impacto Charpy de Muestras Pequeñasrazor926No ratings yet
- Informe 1-Análisis EspectralDocument6 pagesInforme 1-Análisis EspectralErnesto Ortiz PerdomoNo ratings yet
- 2019 2 IpDocument252 pages2019 2 IpDANIEL ALFONSO VARGAS ORTIZNo ratings yet
- Proyecto de Aprendizaje II Lapso 3ero FVM 2013 - 2014Document9 pagesProyecto de Aprendizaje II Lapso 3ero FVM 2013 - 2014Carol Polanco FloresNo ratings yet
- Aprendizajes EsperadosDocument9 pagesAprendizajes EsperadosJoel ZambranoNo ratings yet
- Comparando A Los Numeros Naturales para Primero de PrimariaDocument4 pagesComparando A Los Numeros Naturales para Primero de PrimariaPILARNo ratings yet
- Modulo 3 Productos NotablesDocument7 pagesModulo 3 Productos NotablesGabriela Belén Clavería MolinaNo ratings yet
- Campos de AplicaciónDocument2 pagesCampos de AplicaciónEththevi Flores43% (14)