You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Chapter 32 Assessment of Hematologic Function and Treatment ModalitiesDocument19 pagesChapter 32 Assessment of Hematologic Function and Treatment ModalitiesAira Anne Tonee Villamin100% (3)
- Ece Viii Multimedia Communication (10ec841) NotesDocument140 pagesEce Viii Multimedia Communication (10ec841) NotesKory Woods0% (1)
- An Analysis of Sentence Level Text Classification For The Kannada LanguageDocument5 pagesAn Analysis of Sentence Level Text Classification For The Kannada Languagetjdandin1No ratings yet
- MSP430's Instruction SetDocument81 pagesMSP430's Instruction Settjdandin167% (3)
- Microcontroller Lab ManualDocument54 pagesMicrocontroller Lab Manualtjdandin1No ratings yet
- List of JournalsDocument4 pagesList of Journalstjdandin1No ratings yet
- Sci Journals ListDocument22 pagesSci Journals Listvj4249No ratings yet
- Proje ValDocument53 pagesProje Valtjdandin1No ratings yet
- Sysgen UserDocument424 pagesSysgen Uservicky_ani1986No ratings yet
- Wavelet Based Color Image Watermarking Scheme Giving High Robustness and Exact CorrelationDocument10 pagesWavelet Based Color Image Watermarking Scheme Giving High Robustness and Exact Correlationtjdandin1No ratings yet
- Digital Watermarking Technique For Authentication ofDocument7 pagesDigital Watermarking Technique For Authentication oftjdandin1No ratings yet
- D D W T: P: AbstractDocument5 pagesD D W T: P: AbstractAnjul SinghNo ratings yet
- Digital Image Watermarking Using 3 Level Discrete Wavelet TransformDocument5 pagesDigital Image Watermarking Using 3 Level Discrete Wavelet Transformtjdandin1No ratings yet
- Me - Rnsit NotesDocument71 pagesMe - Rnsit Notesantoshdyade100% (1)
- Researchpaper FPGA Implementation of Low Power High Speed Area Efficient Invisible Image Watermarking Algorithm For ImagesDocument6 pagesResearchpaper FPGA Implementation of Low Power High Speed Area Efficient Invisible Image Watermarking Algorithm For Imagestjdandin1No ratings yet
- HaarcsamDocument10 pagesHaarcsamtjdandin1No ratings yet
- Researchpaper FPGA Implementation of Low Power High Speed Area Efficient Invisible Image Watermarking Algorithm For ImagesDocument6 pagesResearchpaper FPGA Implementation of Low Power High Speed Area Efficient Invisible Image Watermarking Algorithm For Imagestjdandin1No ratings yet
- Leading and Managing Engineering and Technology Book 1Document31 pagesLeading and Managing Engineering and Technology Book 1tjdandin1No ratings yet
- WaveletTutorial PDFDocument67 pagesWaveletTutorial PDFdhrghamNo ratings yet
- VHDL CookbookDocument111 pagesVHDL Cookbookcoolboyz81990No ratings yet
- VHDL 3Document14 pagesVHDL 3tjdandin1No ratings yet
- Data Hiding For Digital AudioDocument4 pagesData Hiding For Digital Audiotjdandin1No ratings yet
- Paper68 ICARA2004 391 395Document5 pagesPaper68 ICARA2004 391 395tjdandin1No ratings yet
- ECG Signal Data HidingDocument4 pagesECG Signal Data Hidingtjdandin1No ratings yet
- Wedding March Piano Solo PDFDocument2 pagesWedding March Piano Solo PDFJulianaRochaNo ratings yet
- AdvancedDocument35 pagesAdvancedtjdandin1No ratings yet
- Accelerated Computing in Sensor NodesDocument6 pagesAccelerated Computing in Sensor Nodestjdandin1No ratings yet
- Tamper Detection and RecoveryDocument6 pagesTamper Detection and Recoverytjdandin1No ratings yet
- Ch1. VLSI System Design MethodologyDocument47 pagesCh1. VLSI System Design Methodologytjdandin1No ratings yet
- IV - Keshav, S. (2007) - How To Read A Paper PDFDocument2 pagesIV - Keshav, S. (2007) - How To Read A Paper PDFAurangzeb ChaudharyNo ratings yet
- Induction Presentation Biology A Level and Gcse.204719226Document25 pagesInduction Presentation Biology A Level and Gcse.204719226Cut TirayaNo ratings yet
- Contents of Practicals XIIDocument3 pagesContents of Practicals XIINibedeetaNo ratings yet
- PteridophytesDocument61 pagesPteridophytestapas kunduNo ratings yet
- Agrias Claudina Intermedia: Two New Records of From Eastern ColombiaDocument2 pagesAgrias Claudina Intermedia: Two New Records of From Eastern ColombiaJuan Carlos Flores PazNo ratings yet
- M.D. Sheets, M.L. Du Bois and J.G. WilliamsonDocument2 pagesM.D. Sheets, M.L. Du Bois and J.G. WilliamsonWinda AlpiniawatiNo ratings yet
- WRT 1020 Cause and Effect Paper - SmokingDocument10 pagesWRT 1020 Cause and Effect Paper - Smokingapi-248441390No ratings yet
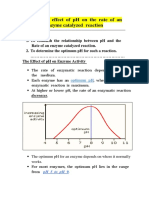
- Effect of PH On Enzyme ActivityDocument12 pagesEffect of PH On Enzyme ActivityAb AbNo ratings yet
- Hcin620 m6 Lab6 Hanifahmutesi-FinalprojectDocument5 pagesHcin620 m6 Lab6 Hanifahmutesi-Finalprojectapi-488096711No ratings yet
- Itch Mechanisms and ManagementDocument464 pagesItch Mechanisms and ManagementGaurav JaswalNo ratings yet
- Photosynthesis and RespiratDocument12 pagesPhotosynthesis and Respiratarlyn09160% (2)
- General AnatomiDocument28 pagesGeneral Anatomid25No ratings yet
- 2016 Annual Report - On Line VersionDocument86 pages2016 Annual Report - On Line VersionFebriyani SulistyaningsihNo ratings yet
- Photoexcited Molecules of Pteridine DerivativesDocument6 pagesPhotoexcited Molecules of Pteridine DerivativesDr. Amrit MitraNo ratings yet
- 143 150 (Ajpr)Document8 pages143 150 (Ajpr)SandraNo ratings yet
- Car - Structural Bases For Shaping of DolinesDocument18 pagesCar - Structural Bases For Shaping of DolinesCaegeoNo ratings yet
- Kroll Expert Report Avitabile V BeachDocument43 pagesKroll Expert Report Avitabile V Beachwolf woodNo ratings yet
- Long Range Sports Med 15Document6 pagesLong Range Sports Med 15api-361293242No ratings yet
- Immune Response in The Human BodyDocument30 pagesImmune Response in The Human BodyjohnosborneNo ratings yet
- Boger Boenninghausen Characteristics RepertoryDocument12 pagesBoger Boenninghausen Characteristics RepertoryDrx Rustom AliNo ratings yet
- Aspb 2012 - 106Document204 pagesAspb 2012 - 106arunprabhu_dhanapalNo ratings yet
- The Case For Increased Research On Male FertilityDocument23 pagesThe Case For Increased Research On Male FertilityIndyra AlencarNo ratings yet
- Robert Szentes - Unlimited Possibilities - SampleDocument63 pagesRobert Szentes - Unlimited Possibilities - Samplepurple_bad67% (3)
- Biology Form 4: Chapter 1 (Introduction To Biology)Document2 pagesBiology Form 4: Chapter 1 (Introduction To Biology)Gerard Selvaraj92% (12)
- Dalandan (Citrus Aurantium Linn.) Peelings and Calamansi (Citrofortunella Microcarpa) Extract As An Alternative Fire Ant KillerDocument6 pagesDalandan (Citrus Aurantium Linn.) Peelings and Calamansi (Citrofortunella Microcarpa) Extract As An Alternative Fire Ant KillerMaryknoll BernabeNo ratings yet
- Curs Ginkgo BilobaDocument7 pagesCurs Ginkgo BilobaAnamaria RizacNo ratings yet
- Strategies For Plant Regeneration From Mesophyll Protoplasts of The Recalcitrant Fruit and Farmwoodland Species L. (Sweet/wild Cherry)Document6 pagesStrategies For Plant Regeneration From Mesophyll Protoplasts of The Recalcitrant Fruit and Farmwoodland Species L. (Sweet/wild Cherry)Geral BlancoNo ratings yet
- Chapter 1 Life Span DevelopmentDocument24 pagesChapter 1 Life Span DevelopmentKayelita Wu100% (3)
- TNPSC Group 1 Mains Test Batch Revised Post ResultDocument11 pagesTNPSC Group 1 Mains Test Batch Revised Post ResultBeing HumaneNo ratings yet
- Guyabano Plant ResearchDocument2 pagesGuyabano Plant ResearchAnnie OmlangNo ratings yet