You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- (R#1) XQ-450 - 600-800VDocument121 pages(R#1) XQ-450 - 600-800VFrancisco PestañoNo ratings yet
- Kristen Swanson's Theory of CaringDocument12 pagesKristen Swanson's Theory of CaringAlexandria David50% (2)
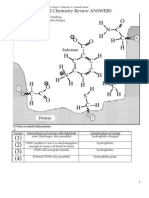
- N H H C C O: 7.012 Chemistry Review ANSWERSDocument2 pagesN H H C C O: 7.012 Chemistry Review ANSWERSGlendonNo ratings yet
- MIT Biology Department 7.012: Introductory BiologyDocument3 pagesMIT Biology Department 7.012: Introductory BiologyGlendonNo ratings yet
- Lecture2 ConceptDocument1 pageLecture2 ConceptGlendonNo ratings yet
- 7.012 First Section Self-Quiz SolutionsDocument2 pages7.012 First Section Self-Quiz SolutionsGlendonNo ratings yet
- Anthropometric Article2Document11 pagesAnthropometric Article2Lakshita SainiNo ratings yet
- DexaDocument36 pagesDexaVioleta Naghiu100% (1)
- Brooklyn Hops BreweryDocument24 pagesBrooklyn Hops BrewerynyairsunsetNo ratings yet
- Arcelor Mittal Operations: Operational Area Is Sub-Divided Into 4 PartsDocument5 pagesArcelor Mittal Operations: Operational Area Is Sub-Divided Into 4 Partsarpit agrawalNo ratings yet
- 3 Growing in FaithDocument5 pages3 Growing in FaithJohnny PadernalNo ratings yet
- TEC3000 Series On/Off or Floating Fan Coil and Individual Zone Thermostat Controllers With Dehumidification CapabilityDocument48 pagesTEC3000 Series On/Off or Floating Fan Coil and Individual Zone Thermostat Controllers With Dehumidification CapabilityIvar Denicia DelgadilloNo ratings yet
- Paramagnetic Article PDFDocument5 pagesParamagnetic Article PDFJonathan SinclairNo ratings yet
- Membrane AutopsyDocument2 pagesMembrane AutopsyBiljana TausanovicNo ratings yet
- EMI Course CatalogDocument645 pagesEMI Course CatalogFarouk OthmaniNo ratings yet
- Showalter Female MaladyDocument13 pagesShowalter Female MaladyKevin Sebastian Patarroyo GalindoNo ratings yet
- Imperial SpeechDocument2 pagesImperial SpeechROJE DANNELL GALVANNo ratings yet
- Blood Anatomy and Physiology ReviewDocument20 pagesBlood Anatomy and Physiology ReviewStacey CamilleNo ratings yet
- Von Willebrand Disease in WomenDocument0 pagesVon Willebrand Disease in WomenMarios SkarmoutsosNo ratings yet
- G1 CurvedDocument16 pagesG1 CurvedElbert Ryan OcampoNo ratings yet
- Low Cholesterol DietDocument10 pagesLow Cholesterol Dietkevintotz73No ratings yet
- Parle G ReportDocument7 pagesParle G ReportnikhilNo ratings yet
- Refuse Chute PPT 01Document11 pagesRefuse Chute PPT 01sanika shindeNo ratings yet
- 04 TitrimetryDocument7 pages04 TitrimetryDarwin Fetalbero ReyesNo ratings yet
- Multiscale Modeling of Bone Tissue MechanobiologyDocument12 pagesMultiscale Modeling of Bone Tissue MechanobiologyLina AvilaNo ratings yet
- Pharmacy Incharge JDDocument5 pagesPharmacy Incharge JDUsman JamilNo ratings yet
- Module 3 Passive Heating 8.3.18Document63 pagesModule 3 Passive Heating 8.3.18Aman KashyapNo ratings yet
- Measurement LabDocument4 pagesMeasurement LabHenessa GumiranNo ratings yet
- Weather and ClimateDocument5 pagesWeather and ClimateprititjadhavnNo ratings yet
- Cystostomy NewDocument32 pagesCystostomy Newkuncupcupu1368No ratings yet
- Matter and Change 2008 Chapter 14Document40 pagesMatter and Change 2008 Chapter 14cattmy100% (1)
- LUBRICANTCOOLANT Answer With ReflectionDocument5 pagesLUBRICANTCOOLANT Answer With ReflectionCharles Vincent PaniamoganNo ratings yet
- KorfundDocument68 pagesKorfundnhy.mail2709100% (1)
- Evaluation of Bond Strenght of Dentin Adhesive at Dry and Moist Dentin-Resin Interface PDFDocument4 pagesEvaluation of Bond Strenght of Dentin Adhesive at Dry and Moist Dentin-Resin Interface PDFOpris PaulNo ratings yet