You might also like
- Informatica PDFDocument55 pagesInformatica PDFharishkodeNo ratings yet
- Informatica Interview QnADocument345 pagesInformatica Interview QnASuresh DhinnepalliNo ratings yet
- Demantra Performance Solutions - Real World Problems and Solutions (ID 1081962.1)Document11 pagesDemantra Performance Solutions - Real World Problems and Solutions (ID 1081962.1)gentoo68No ratings yet
- A Interview Questions and AnswersDocument34 pagesA Interview Questions and Answersmallekrishna123No ratings yet
- DataStage Interview QuestionDocument9 pagesDataStage Interview Questionanamik2100No ratings yet
- Time-Series Forecasting Using Conv1D-LSTM - Multiple Timesteps Into FutureDocument6 pagesTime-Series Forecasting Using Conv1D-LSTM - Multiple Timesteps Into Future8c354be21dNo ratings yet
- A Interview Questions and Answers - Cool InterviewDocument30 pagesA Interview Questions and Answers - Cool Interviewcm_ram847118100% (16)
- Datastage Interview Questions - Answers - 0516Document29 pagesDatastage Interview Questions - Answers - 0516rachitNo ratings yet
- Datastage: Datastage Interview Questions/AnswersDocument28 pagesDatastage: Datastage Interview Questions/Answersashok7374No ratings yet
- Practice Questions for Tableau Desktop Specialist Certification Case BasedFrom EverandPractice Questions for Tableau Desktop Specialist Certification Case BasedRating: 5 out of 5 stars5/5 (1)
- Insert, Update Ordering in InformaticaDocument6 pagesInsert, Update Ordering in InformaticaUr's GopinathNo ratings yet
- Informatica Interview QuestionsDocument5 pagesInformatica Interview QuestionsPreethaNo ratings yet
- ETL Design Challenges and Solutions Through InformaticaDocument12 pagesETL Design Challenges and Solutions Through InformaticaTanuj GautamNo ratings yet
- Re: How Can We Run Workflow With PMCMD?: - You - Work - Directly - by - Using - Remote - Connections - HTMDocument3 pagesRe: How Can We Run Workflow With PMCMD?: - You - Work - Directly - by - Using - Remote - Connections - HTMdavankumarNo ratings yet
- Chan Chun Yew Tp057374 (Pfda)Document25 pagesChan Chun Yew Tp057374 (Pfda)yew chunNo ratings yet
- Whitepaper Bi TD Temporalv4 1585592Document20 pagesWhitepaper Bi TD Temporalv4 1585592prakashNo ratings yet
- Tableau Training Manual 9.0 Basic Version: This Via Tableau Training Manual Was Created for Both New and IntermediateFrom EverandTableau Training Manual 9.0 Basic Version: This Via Tableau Training Manual Was Created for Both New and IntermediateRating: 3 out of 5 stars3/5 (1)
- Excersize DataStructureDocument161 pagesExcersize DataStructureLukman IskanderiaNo ratings yet
- Sap BPCDocument8 pagesSap BPCAqueel MohammedaliNo ratings yet
- 101 Problems and Reports in Webi Report With SolutionsDocument17 pages101 Problems and Reports in Webi Report With SolutionsSree RamNo ratings yet
- Dynamics AX 2009 Reporting To EXCELDocument9 pagesDynamics AX 2009 Reporting To EXCELwonderful12No ratings yet
- Informatica SenariosDocument9 pagesInformatica Senariosypraju100% (3)
- Tableau Your Data!: Fast and Easy Visual Analysis with Tableau SoftwareFrom EverandTableau Your Data!: Fast and Easy Visual Analysis with Tableau SoftwareRating: 4.5 out of 5 stars4.5/5 (4)
- Computer Graphics Assignment Questions ExplainedDocument0 pagesComputer Graphics Assignment Questions Explainedclick2jitNo ratings yet
- Data Sementics QuestionsDocument6 pagesData Sementics QuestionsShivu PatilNo ratings yet
- Informatica: Process Control / Audit of Workflows in InformaticaDocument7 pagesInformatica: Process Control / Audit of Workflows in Informaticaraj meNo ratings yet
- Sap BW FaqDocument89 pagesSap BW Faqgopal_v8021No ratings yet
- SrikanthDocument7 pagesSrikanth2srikanthNo ratings yet
- Most Repeated Questions With AnswersDocument8 pagesMost Repeated Questions With AnswersDeepak Simhadri100% (1)
- SLT For CARDocument8 pagesSLT For CARMichaelNo ratings yet
- HW 8Document2 pagesHW 8Huy NguyenNo ratings yet
- How To Develop A Performance Reporting Tool with MS Excel and MS SharePointFrom EverandHow To Develop A Performance Reporting Tool with MS Excel and MS SharePointNo ratings yet
- Data Interpretation Guide For All Competitive and Admission ExamsFrom EverandData Interpretation Guide For All Competitive and Admission ExamsRating: 2.5 out of 5 stars2.5/5 (6)
- Advanced C++ Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandAdvanced C++ Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo ratings yet
- Pivot Tables for everyone. From simple tables to Power-Pivot: Useful guide for creating Pivot Tables in ExcelFrom EverandPivot Tables for everyone. From simple tables to Power-Pivot: Useful guide for creating Pivot Tables in ExcelNo ratings yet
- SAP interface programming with RFC and VBA: Edit SAP data with MS AccessFrom EverandSAP interface programming with RFC and VBA: Edit SAP data with MS AccessNo ratings yet
- SAS Programming Guidelines Interview Questions You'll Most Likely Be AskedFrom EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be AskedNo ratings yet
- Blue Prism Developer Certification Case Based Practice Question - Latest 2023From EverandBlue Prism Developer Certification Case Based Practice Question - Latest 2023No ratings yet
- Modeling and Simulation of Logistics Flows 2: Dashboards, Traffic Planning and ManagementFrom EverandModeling and Simulation of Logistics Flows 2: Dashboards, Traffic Planning and ManagementNo ratings yet
- The Informed Company: How to Build Modern Agile Data Stacks that Drive Winning InsightsFrom EverandThe Informed Company: How to Build Modern Agile Data Stacks that Drive Winning InsightsNo ratings yet
- AP Computer Science Principles: Student-Crafted Practice Tests For ExcellenceFrom EverandAP Computer Science Principles: Student-Crafted Practice Tests For ExcellenceNo ratings yet
- Excel for Beginners: A Quick Reference and Step-by-Step Guide to Mastering Excel's Fundamentals, Formulas, Functions, Charts, Tables, and More with Practical ExamplesFrom EverandExcel for Beginners: A Quick Reference and Step-by-Step Guide to Mastering Excel's Fundamentals, Formulas, Functions, Charts, Tables, and More with Practical ExamplesNo ratings yet
- Data Smart: Using Data Science to Transform Information into InsightFrom EverandData Smart: Using Data Science to Transform Information into InsightRating: 4 out of 5 stars4/5 (16)
- Beverages PDFDocument16 pagesBeverages PDFBenjaminNo ratings yet
- Mantra LunchDocument1 pageMantra LunchBenjaminNo ratings yet
- Italian: Italian Recipe Competition Judging DayDocument5 pagesItalian: Italian Recipe Competition Judging DayBenjaminNo ratings yet
- Multi Lin 8756 BookDocument41 pagesMulti Lin 8756 BookBenjaminNo ratings yet
- Commun It GlishDocument1 pageCommun It GlishBenjaminNo ratings yet
- Sinh 57686 I PesDocument6 pagesSinh 57686 I PesBenjaminNo ratings yet
- Samoan: Samoan Recipe Competition Judging DayDocument6 pagesSamoan: Samoan Recipe Competition Judging DayBenjaminNo ratings yet
- Measles Out BreaDocument1 pageMeasles Out BreaBenjaminNo ratings yet
- Filipino Recipes 1Document6 pagesFilipino Recipes 1pilapil_j100% (1)
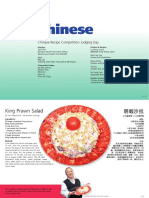
- Chinese: Chinese Recipe Competition Judging DayDocument6 pagesChinese: Chinese Recipe Competition Judging DayBenjaminNo ratings yet
- Client and Projecct DescDocument2 pagesClient and Projecct DescBenjaminNo ratings yet
- Percakapan Bhs Inggris 7 HRDocument18 pagesPercakapan Bhs Inggris 7 HRraden hilmi100% (1)
- Evaluating Apache Hadoop Software For Big Data Etl Functions PaperDocument7 pagesEvaluating Apache Hadoop Software For Big Data Etl Functions PaperBenjaminNo ratings yet
- Autosys Cheatsheet: Autosys: Unix ./autosys - Ksh.Machine" After Installing Autosys, First Make Sure That The DB Is Up andDocument11 pagesAutosys Cheatsheet: Autosys: Unix ./autosys - Ksh.Machine" After Installing Autosys, First Make Sure That The DB Is Up andSandip BanerjeeNo ratings yet
- How to trace discarded rows when loading data from Informatica to targetDocument1 pageHow to trace discarded rows when loading data from Informatica to targetBenjaminNo ratings yet
- Computer Lab - Practical Question BankDocument8 pagesComputer Lab - Practical Question BankSaif UddinNo ratings yet
- MDM 1954197Document4 pagesMDM 1954197BenjaminNo ratings yet
- Informatica - Q & ADocument27 pagesInformatica - Q & ABenjaminNo ratings yet
- Informatica v9 Performance Tuning GuideDocument70 pagesInformatica v9 Performance Tuning GuideUdita LahotiNo ratings yet
- Informatica Power Center 9.0.1: Informatica Reporting and Object Migration Part I Lab#36Document23 pagesInformatica Power Center 9.0.1: Informatica Reporting and Object Migration Part I Lab#36Amit Sharma100% (1)
- Informatica Training Chat Log 2015Document1 pageInformatica Training Chat Log 2015BenjaminNo ratings yet
- A Interview Questions-2Document33 pagesA Interview Questions-2rajesh_443No ratings yet
- 4 Article GrowthGroupDocument3 pages4 Article GrowthGroupDmitri PachenkoNo ratings yet
- Q2W7 English 2Document38 pagesQ2W7 English 2francisNo ratings yet
- A Detailed Lesson Plan For Grade-8 English Direct and Indirect SpeechDocument14 pagesA Detailed Lesson Plan For Grade-8 English Direct and Indirect SpeechsabinaNo ratings yet
- Free IELTS General Training Writing Test - Task 1Document5 pagesFree IELTS General Training Writing Test - Task 1kunta_kNo ratings yet
- ٣ نماذج امتحانات جزئية … الشهادة الاعداديةDocument6 pages٣ نماذج امتحانات جزئية … الشهادة الاعداديةIbrahim SolimanNo ratings yet
- Applied Linguistics: The Twentieth CenturyDocument12 pagesApplied Linguistics: The Twentieth CenturyHaifa-mohdNo ratings yet
- Tato Laviera - AnthologyDocument5 pagesTato Laviera - AnthologyElidio La Torre LagaresNo ratings yet
- Lesson 4 Part of The Body and Health ProblemDocument17 pagesLesson 4 Part of The Body and Health ProblemAlienda Puspita PutriNo ratings yet
- A Provider-Friendly Serverless Framework For Latency-Critical ApplicationsDocument4 pagesA Provider-Friendly Serverless Framework For Latency-Critical ApplicationsJexiaNo ratings yet
- SAT Prep FlexBook Questions With Answer ExplanationsDocument22 pagesSAT Prep FlexBook Questions With Answer ExplanationsJoann LeeNo ratings yet
- Commu I ReviewedDocument45 pagesCommu I ReviewedCabdirisaaq CabdisalanNo ratings yet
- Development and Implementation of TrainingDocument27 pagesDevelopment and Implementation of TrainingKashfia RehnumaNo ratings yet
- English 4 Diagnostic/Achievement Test Table of Specifications Learning Competency NO. OF Items Placement PercentageDocument5 pagesEnglish 4 Diagnostic/Achievement Test Table of Specifications Learning Competency NO. OF Items Placement PercentageAnnabelle PulidoNo ratings yet
- Comparing English pronouns in a tableDocument1 pageComparing English pronouns in a tableCarmen Fernández100% (1)
- SOLUTION-Spot The Error 17 FebDocument3 pagesSOLUTION-Spot The Error 17 FebAjay KambleNo ratings yet
- WCSC 2018 Programme ScheduleDocument4 pagesWCSC 2018 Programme ScheduleJayaraman KamarajNo ratings yet
- Week14EdLing 102ProcessingtheMatterDocument5 pagesWeek14EdLing 102ProcessingtheMatterKevin BlasurcaNo ratings yet
- Liotar Lectures D'enfance TranslationDocument42 pagesLiotar Lectures D'enfance TranslationvladaalisterNo ratings yet
- Features of Human Language by HockettDocument14 pagesFeatures of Human Language by HockettDeborah Jane SantiagoNo ratings yet
- en Improving Students Writing Skill Using ADocument15 pagesen Improving Students Writing Skill Using AfatinfiqahNo ratings yet
- Student DCF - 2023 - Colour - New FieldsDocument8 pagesStudent DCF - 2023 - Colour - New FieldsPunarbasuNo ratings yet
- Devi Rahasyam Agama PDFDocument12 pagesDevi Rahasyam Agama PDFkingsuryaNo ratings yet
- DLL-3rd Q Day 1Document4 pagesDLL-3rd Q Day 1KèlǐsītǎnKǎPángNo ratings yet
- Linux Systems Administration Shell Scripting Basics Mike Jager Network Startup Resource Center Mike - Jager@synack - Co.nzDocument15 pagesLinux Systems Administration Shell Scripting Basics Mike Jager Network Startup Resource Center Mike - Jager@synack - Co.nzRicky LynsonNo ratings yet
- Adverbs: What Is Are Adverbs?Document27 pagesAdverbs: What Is Are Adverbs?Jevon PalisocNo ratings yet
- SwahiliDocument9 pagesSwahilibetula_betulicaNo ratings yet
- MD ApDocument20 pagesMD ApSundaresan MunuswamyNo ratings yet
- VERBSDocument1 pageVERBSEs Jey NanolaNo ratings yet
- Marketing SemioticsDocument13 pagesMarketing SemioticsMalvinNo ratings yet
- Ainu Bear Festival PDFDocument62 pagesAinu Bear Festival PDFAndoskinNo ratings yet