You might also like
- Data Storage and Back Up ALBERTO COUTODocument2 pagesData Storage and Back Up ALBERTO COUTOAnanta Abdillah WicaksonoNo ratings yet
- 000-YOUR-FIRSTNAME YOUR-FAMILY-NAME Handout DSTI SemanticWebDocument53 pages000-YOUR-FIRSTNAME YOUR-FAMILY-NAME Handout DSTI SemanticWebMamadou saidou BaldeNo ratings yet
- ER Exercises 20141125Document7 pagesER Exercises 20141125Merve CvdrNo ratings yet
- Hadoop and Pig Overview - Hands-On: Outline of TutorialDocument52 pagesHadoop and Pig Overview - Hands-On: Outline of TutorialKonara KiranNo ratings yet
- Class: CS 237 Distributed Systems Middleware Instructor: Nalini VenkatasubramanianDocument55 pagesClass: CS 237 Distributed Systems Middleware Instructor: Nalini VenkatasubramanianPratheesh KumarNo ratings yet
- Data Mining With Hadoop and Hive Introduction To ArchitectureDocument39 pagesData Mining With Hadoop and Hive Introduction To ArchitectureAshwin AjmeraNo ratings yet
- Apache Hadoop TrainingDocument377 pagesApache Hadoop TrainingRamya VaranasiNo ratings yet
- Uber - Big Data Case StudyDocument17 pagesUber - Big Data Case StudyAlexandro MarcelNo ratings yet
- Apache Hadoop Developer TrainingDocument394 pagesApache Hadoop Developer TrainingAshok Kumar K R100% (1)
- Shortnotes For CloudDocument22 pagesShortnotes For CloudMahi MahiNo ratings yet
- Introduction To: Ma EdDocument42 pagesIntroduction To: Ma EdAditya WijayantoNo ratings yet
- Unit - III Advanced Analytics Technology and ToolsDocument44 pagesUnit - III Advanced Analytics Technology and ToolsDiksha ChhabraNo ratings yet
- Unit 5 - Introduction To HadoopDocument50 pagesUnit 5 - Introduction To HadoopShree ShakNo ratings yet
- Chapter 10Document45 pagesChapter 10Sarita SamalNo ratings yet
- Hadoop EcosystemDocument26 pagesHadoop EcosystemainNo ratings yet
- Unit 5 - Introduction To HadoopDocument50 pagesUnit 5 - Introduction To HadoopShree ShakNo ratings yet
- Hadoop DcsDocument31 pagesHadoop Dcsbt20cse155No ratings yet
- Hadoop Overview: Open Source Framework Processing Large Amounts of Heterogeneous Data Sets Distributed FashionDocument62 pagesHadoop Overview: Open Source Framework Processing Large Amounts of Heterogeneous Data Sets Distributed FashionMousoomi BaruahNo ratings yet
- HA200Document4 pagesHA200Adam OngNo ratings yet
- Big Data Camp Intro HadoopDocument22 pagesBig Data Camp Intro Hadoopindoos2000No ratings yet
- Hadoop and Big DataDocument41 pagesHadoop and Big DataYukti KauraNo ratings yet
- BigData Hadoop Online Training by ExpertsDocument41 pagesBigData Hadoop Online Training by ExpertsHarika583No ratings yet
- Introduction To HANA - Deep DiveDocument106 pagesIntroduction To HANA - Deep DiveJithu ZithendraNo ratings yet
- Big Data Processing, 2014/15: Lecture 8: Pig Latin!Document58 pagesBig Data Processing, 2014/15: Lecture 8: Pig Latin!sridhiyaNo ratings yet
- Apache Hadoop Developer Training PDFDocument394 pagesApache Hadoop Developer Training PDFimankitNo ratings yet
- Spark StreamingDocument99 pagesSpark Streamingmonisha sydamNo ratings yet
- Hadoop Is Good For:: 1. Describe The Core Components of Hadoop and Their PurposeDocument4 pagesHadoop Is Good For:: 1. Describe The Core Components of Hadoop and Their Purposehatem magdyNo ratings yet
- Hadoop - HiveDocument190 pagesHadoop - HiveJhumri TalaiyaNo ratings yet
- Chapter 5 HiveDocument69 pagesChapter 5 HiveKomalNo ratings yet
- Best Hadoop Online TrainingDocument41 pagesBest Hadoop Online TrainingHarika583No ratings yet
- Hadoop Intro - Part1Document45 pagesHadoop Intro - Part1nosopa5904No ratings yet
- Banking Data Analysis On HadoopDocument21 pagesBanking Data Analysis On HadoopShantanuNo ratings yet
- Hadoop EcosystemDocument16 pagesHadoop Ecosystempoojan thakkarNo ratings yet
- ProgrammingHadoop ApacheConUS08Document7 pagesProgrammingHadoop ApacheConUS08jefferyleclercNo ratings yet
- MapReduce Performance PredictionDocument29 pagesMapReduce Performance PredictionEngin SözerNo ratings yet
- Module 2.2Document32 pagesModule 2.2Priyanka BandagaleNo ratings yet
- Big Data - Final ProjectDocument2 pagesBig Data - Final ProjectMohammed Nabil Saeed Abdul TawabNo ratings yet
- OLTP: Numerous Short Transactions. Requires Fast Query Processing andDocument3 pagesOLTP: Numerous Short Transactions. Requires Fast Query Processing andJasmina TachevaNo ratings yet
- Introduction To Hive: Hive Meta Data Engine + Query Engine For HadoopDocument15 pagesIntroduction To Hive: Hive Meta Data Engine + Query Engine For HadoopDheepikaNo ratings yet
- Unit V FRAMEWORKS AND VISUALIZATIONDocument71 pagesUnit V FRAMEWORKS AND VISUALIZATIONYash DeepNo ratings yet
- Fundamentals of SAP HANA The BeginingDocument59 pagesFundamentals of SAP HANA The Beginingsaphari76No ratings yet
- Unit 5 PIG&HIVEDocument115 pagesUnit 5 PIG&HIVEKishore ParimiNo ratings yet
- DefenseDocument28 pagesDefenseherr_jthNo ratings yet
- Chapter 10 Part I - EdDocument15 pagesChapter 10 Part I - Edvenakt2939No ratings yet
- Apache PigDocument21 pagesApache Pigsachin rajputNo ratings yet
- Hadoop DemoDocument14 pagesHadoop DemovishnuNo ratings yet
- Understanding Simple FinanceDocument31 pagesUnderstanding Simple FinanceBinoi JoshiNo ratings yet
- BigData Unit 2Document15 pagesBigData Unit 2Sreedhar ArikatlaNo ratings yet
- Reproducible Quantum Chemistry in Jupyter NotebooksDocument23 pagesReproducible Quantum Chemistry in Jupyter NotebooksHari Madhavan Krishna KumarNo ratings yet
- Google App EngineDocument14 pagesGoogle App Enginepercybhai031No ratings yet
- Clickstream DataDocument38 pagesClickstream DataKartik GuptaNo ratings yet
- Cloudera Msazure Hadoop Deployment GuideDocument39 pagesCloudera Msazure Hadoop Deployment GuideKristofNo ratings yet
- Sen-762 Advanced Big Data Analytics: MapreduceDocument46 pagesSen-762 Advanced Big Data Analytics: MapreduceبالیراجپوتNo ratings yet
- Exploring Bigdata With Hadoop: Dr.A.Bazila Banu Associate Professor Department of CseDocument23 pagesExploring Bigdata With Hadoop: Dr.A.Bazila Banu Associate Professor Department of CseMAMAN MYTHIEN SNo ratings yet
- Parallel Cursor Method in AbapDocument3 pagesParallel Cursor Method in AbapfairwellmdNo ratings yet
- Teradata ArchitectureDocument30 pagesTeradata ArchitectureGyara Prashanth KumarNo ratings yet
- By Christian Mechem and Geoff CrowleyDocument11 pagesBy Christian Mechem and Geoff CrowleyChristian MechemNo ratings yet
- 12c Adaptive OptimizationDocument46 pages12c Adaptive Optimizationtest yyNo ratings yet
- Big Data Hadoop StackDocument52 pagesBig Data Hadoop StackYaser Ali TariqNo ratings yet
- 2012 IBM TWA - SAP Demo IntroductionDocument9 pages2012 IBM TWA - SAP Demo Introductionjay_kasundraNo ratings yet
- Unit 1 Haoop ArchitectureDocument26 pagesUnit 1 Haoop ArchitectureAnirudh PrakashNo ratings yet
- Introduction To DatabaseDocument8 pagesIntroduction To DatabasemalhiavtarsinghNo ratings yet
- BookDocument68 pagesBooksatyasap007No ratings yet
- Merge StatementDocument2 pagesMerge StatementLiem NguyenNo ratings yet
- h15459 WP Powerscale Onefs Storage Efficiency - Pdf.externalDocument15 pagesh15459 WP Powerscale Onefs Storage Efficiency - Pdf.externalqwrr rewqNo ratings yet
- MySQL Security - 2019v2-2Document71 pagesMySQL Security - 2019v2-2abdiel AlveoNo ratings yet
- QuizDocument22 pagesQuizAldo EriandaNo ratings yet
- What Are The Diff Navigators Available in Odi?Document43 pagesWhat Are The Diff Navigators Available in Odi?Anonymous S5fcPaNo ratings yet
- Privacy or Not - That Is The Question: Ivan Cirković Algebra College Icirkov@racunarstvo - HRDocument5 pagesPrivacy or Not - That Is The Question: Ivan Cirković Algebra College Icirkov@racunarstvo - HRIvan CirkovićNo ratings yet
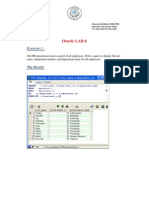
- Oracle LAB 6 SolutionDocument7 pagesOracle LAB 6 SolutionMalini SurianarayananNo ratings yet
- Info Written Exam 20156autumDocument2 pagesInfo Written Exam 20156autumCharles CruzNo ratings yet
- Documentation & Data Dictionary - IMDb and Box Office MojoDocument39 pagesDocumentation & Data Dictionary - IMDb and Box Office MojoBill ChenNo ratings yet
- Question Text: Correct Mark 1.00 Out of 1.00Document12 pagesQuestion Text: Correct Mark 1.00 Out of 1.00DominicOrtegaNo ratings yet
- A BAB Upgrade11i-R12 v1.0Document158 pagesA BAB Upgrade11i-R12 v1.0Mohammed Shoukat AliNo ratings yet
- AWS Certified Cloud PractitionerDocument18 pagesAWS Certified Cloud Practitioner李楚楚No ratings yet
- Hurricane Electric Network MapDocument2 pagesHurricane Electric Network Mapqazdec27No ratings yet
- mySQL DumpDocument16 pagesmySQL DumpLUIGI JAVIER ACUNANo ratings yet
- Cs301 Mid Term Mega FileDocument30 pagesCs301 Mid Term Mega FileUsman Ghani JehanNo ratings yet
- Careers - Data Analytics Training - Internshala Trainings PDFDocument2 pagesCareers - Data Analytics Training - Internshala Trainings PDFAbhilash BhatiNo ratings yet
- Data Warehousing Case Studies .Compressed-1Document8 pagesData Warehousing Case Studies .Compressed-1Zihni ThoriqNo ratings yet
- Assignment - 1: Name: Branch: CSE Uid: Subject: DBMSDocument6 pagesAssignment - 1: Name: Branch: CSE Uid: Subject: DBMSChetan RajNo ratings yet
- MigrationGuide PDFDocument201 pagesMigrationGuide PDFMartin CarrozzoNo ratings yet
- IMK12 InfoVisDocument23 pagesIMK12 InfoVis2IA21Yolenta Alfrida MoreNo ratings yet
- Practical Assignment of DbmsDocument4 pagesPractical Assignment of DbmsAnjali VermaNo ratings yet
- Management Information Systems 13th Edition Laudon Solutions Manual DownloadDocument21 pagesManagement Information Systems 13th Edition Laudon Solutions Manual DownloadPenelope Torres100% (17)
- Oracle Database 11g: SQL Fundamentals I: DurationDocument4 pagesOracle Database 11g: SQL Fundamentals I: DurationabdullaNo ratings yet
- TulleyDocument35 pagesTulleychand1255No ratings yet
- Distributed Database System And: Transaction-ProcessingDocument21 pagesDistributed Database System And: Transaction-ProcessingErmiyas SeifeNo ratings yet