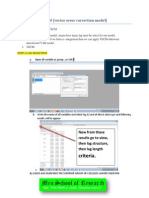
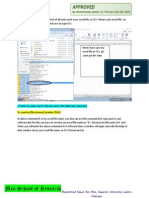
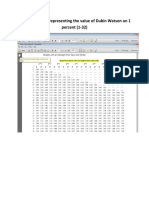
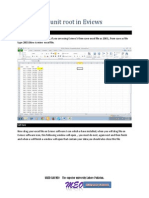
You might also like
- Modeling Panel Data EffectsDocument13 pagesModeling Panel Data EffectsAzime Hassen100% (1)
- Johanson Cointegration Test and ECMDocument7 pagesJohanson Cointegration Test and ECMsaeed meo100% (6)
- Stata Ts Introduction To Time-Series CommandsDocument6 pagesStata Ts Introduction To Time-Series CommandsngocmimiNo ratings yet
- VECMDocument9 pagesVECMsaeed meo100% (3)
- Panel Data AnalysisDocument8 pagesPanel Data AnalysisAditya Kumar SinghNo ratings yet
- Panel Data Analysis Sunita AroraDocument28 pagesPanel Data Analysis Sunita Aroralukgv,h100% (1)
- Panel Vs Pooled DataDocument9 pagesPanel Vs Pooled DataFesboekii FesboekiNo ratings yet
- 3 Multiple Linear Regression: Estimation and Properties: Ezequiel Uriel Universidad de Valencia Version: 09-2013Document37 pages3 Multiple Linear Regression: Estimation and Properties: Ezequiel Uriel Universidad de Valencia Version: 09-2013penyia100% (1)
- Panel Data 1Document6 pagesPanel Data 1Abdul AzizNo ratings yet
- Econometrics EnglishDocument62 pagesEconometrics EnglishATHANASIA MASOURANo ratings yet
- Useful Stata CommandsDocument48 pagesUseful Stata CommandsumerfaridNo ratings yet
- Lec06 - Panel DataDocument160 pagesLec06 - Panel DataTung NguyenNo ratings yet
- Application of VAR Model AnalysisDocument22 pagesApplication of VAR Model AnalysisEason SaintNo ratings yet
- Panel Data Lecture NotesDocument38 pagesPanel Data Lecture NotesSanam KhanNo ratings yet
- Time Series With EViews PDFDocument37 pagesTime Series With EViews PDFashishankurNo ratings yet
- GSEMModellingusingStata PDFDocument97 pagesGSEMModellingusingStata PDFmarikum74No ratings yet
- DevStat8e - 01 - 02 03 04 and 4.6 FCDocument20 pagesDevStat8e - 01 - 02 03 04 and 4.6 FCchemicaly12No ratings yet
- MacKinnon Critical Values For Cointegration Tests Qed WP 1227Document19 pagesMacKinnon Critical Values For Cointegration Tests Qed WP 1227henry amielNo ratings yet
- Introduction To Econometrics With RDocument400 pagesIntroduction To Econometrics With RHervé DakpoNo ratings yet
- Linear Regression Models For Panel Data Using SAS, STATA, LIMDEP and SPSSDocument67 pagesLinear Regression Models For Panel Data Using SAS, STATA, LIMDEP and SPSSLuísa Martins100% (2)
- Time Series - Practical ExercisesDocument9 pagesTime Series - Practical ExercisesJobayer Islam TunanNo ratings yet
- DOLS ModelDocument8 pagesDOLS Modelsaeed meo100% (2)
- Ordinary Least Square EstimationDocument30 pagesOrdinary Least Square Estimationthrphys1940No ratings yet
- Omitted Variables - Monte Carlo StataDocument12 pagesOmitted Variables - Monte Carlo StataGian SoaveNo ratings yet
- Univariate Time SeriesDocument83 pagesUnivariate Time SeriesShashank Gupta100% (1)
- Difference Between Logit and Probit ModelsDocument7 pagesDifference Between Logit and Probit Modelswinkhaing100% (1)
- Econometrics Books: Books On-Line Books / NotesDocument8 pagesEconometrics Books: Books On-Line Books / Notesaftab20100% (1)
- Dummy Variable Regression Models 9.1:, Gujarati and PorterDocument18 pagesDummy Variable Regression Models 9.1:, Gujarati and PorterTân DươngNo ratings yet
- EC310K: Effect of US Food Aid on ConflictDocument2 pagesEC310K: Effect of US Food Aid on ConflictRO BWNNo ratings yet
- Between Within Stata AnalysisDocument3 pagesBetween Within Stata AnalysisMaria PappaNo ratings yet
- Stock Watson 3U ExerciseSolutions Chapter9 InstructorsDocument16 pagesStock Watson 3U ExerciseSolutions Chapter9 Instructorsvivo15100% (4)
- Lahore University of Management Sciences ECON 330 - EconometricsDocument3 pagesLahore University of Management Sciences ECON 330 - EconometricsshyasirNo ratings yet
- ARDL Model - Hossain Academy Note PDFDocument5 pagesARDL Model - Hossain Academy Note PDFabdulraufhcc100% (1)
- Wooldridge 2010Document42 pagesWooldridge 2010iamsbikasNo ratings yet
- Bowerman CH15 APPT FinalDocument38 pagesBowerman CH15 APPT FinalMuktesh Singh100% (1)
- Structure Project Topics For Projects 2016Document4 pagesStructure Project Topics For Projects 2016Mariu VornicuNo ratings yet
- GMM estimation in Stata 11 for generalized method of moments modelsDocument27 pagesGMM estimation in Stata 11 for generalized method of moments modelsMao CardenasNo ratings yet
- Course Manual Statistics 1718Document72 pagesCourse Manual Statistics 1718Wayne DorsonNo ratings yet
- Econometrics of Panel Data ModelsDocument34 pagesEconometrics of Panel Data Modelsarmailgm100% (1)
- Microeconometrics Lecture NotesDocument407 pagesMicroeconometrics Lecture NotesburgguNo ratings yet
- Econometrics Ch6 ApplicationsDocument49 pagesEconometrics Ch6 ApplicationsMihaela SirițanuNo ratings yet
- Time Series AnalysisDocument3 pagesTime Series AnalysisKamil Mehdi AbbasNo ratings yet
- Bayesian ModelDocument71 pagesBayesian ModelkNo ratings yet
- Panel Data Regression Methods GuideDocument19 pagesPanel Data Regression Methods GuideHassanMubasherNo ratings yet
- Introduction to Regression Models for Panel Data Analysis WorkshopDocument42 pagesIntroduction to Regression Models for Panel Data Analysis WorkshopAnonymous 0sxQqwAIMBNo ratings yet
- MSO S04 - Exponential Smoothing With SolutionsDocument33 pagesMSO S04 - Exponential Smoothing With SolutionsdurdanekocacobanNo ratings yet
- Arch Model and Time-Varying VolatilityDocument17 pagesArch Model and Time-Varying VolatilityJorge Vega RodríguezNo ratings yet
- FMOLS ModelDocument8 pagesFMOLS Modelsaeed meoNo ratings yet
- Markov Chain Monte CarloDocument9 pagesMarkov Chain Monte CarloHardways MediaNo ratings yet
- Introduction To Multiple Linear RegressionDocument49 pagesIntroduction To Multiple Linear RegressionRennate MariaNo ratings yet
- r5210501 Probability and StatisticsDocument1 pager5210501 Probability and StatisticssivabharathamurthyNo ratings yet
- STATA Data PanelDocument11 pagesSTATA Data PanelalbertolossNo ratings yet
- StataDocument30 pagesStatagarryduff100% (3)
- VAR Models ExplainedDocument8 pagesVAR Models Explainedv4nhuy3nNo ratings yet
- Lecture 7 VARDocument34 pagesLecture 7 VAREason SaintNo ratings yet
- Econometric S Lecture 43Document36 pagesEconometric S Lecture 43Khurram AzizNo ratings yet
- Applied Nonlinear Analysis: Proceedings of an International Conference on Applied Nonlinear Analysis, Held at the University of Texas at Arlington, Arlington, Texas, April 20–22, 1978From EverandApplied Nonlinear Analysis: Proceedings of an International Conference on Applied Nonlinear Analysis, Held at the University of Texas at Arlington, Arlington, Texas, April 20–22, 1978No ratings yet
- The Economics of Inaction: Stochastic Control Models with Fixed CostsFrom EverandThe Economics of Inaction: Stochastic Control Models with Fixed CostsNo ratings yet
- Time Sereis Analysis Using StataDocument26 pagesTime Sereis Analysis Using Statasaeed meo100% (6)
- Panel DataDocument5 pagesPanel Datasaeed meo100% (2)
- Formatting of ThesisDocument42 pagesFormatting of Thesissaeed meo100% (1)
- MediationDocument5 pagesMediationsaeed meo100% (1)
- Specific Facinating Words For Literature ReviewDocument1 pageSpecific Facinating Words For Literature Reviewsaeed meo100% (1)
- Best Paper To Learn About ArdlDocument27 pagesBest Paper To Learn About Ardlsaeed meo100% (7)
- Mediation If We Have More Then One Mediating VariableDocument39 pagesMediation If We Have More Then One Mediating Variablesaeed meo100% (3)
- How To Arrange Panel Data For Eviews Into MSDocument2 pagesHow To Arrange Panel Data For Eviews Into MSsaeed meoNo ratings yet
- FMOLS ModelDocument8 pagesFMOLS Modelsaeed meoNo ratings yet
- Granger CusalityDocument4 pagesGranger Cusalitysaeed meoNo ratings yet
- Cronbach's AlphaDocument5 pagesCronbach's Alphasaeed meoNo ratings yet
- Importing Data Into R.Document3 pagesImporting Data Into R.saeed meoNo ratings yet
- Business Research MathodDocument95 pagesBusiness Research Mathodsaeed meo100% (2)
- Many Way of Serial Correlation CheckingDocument5 pagesMany Way of Serial Correlation Checkingsaeed meo100% (2)
- Quantative TechniqesDocument155 pagesQuantative Techniqessaeed meo100% (2)
- DOLS ModelDocument8 pagesDOLS Modelsaeed meo100% (2)
- DW Values TableDocument8 pagesDW Values Tablesaeed meoNo ratings yet
- Unit Root Using EviewDocument9 pagesUnit Root Using Eviewsaeed meo75% (4)
- List of Impact Factor JournalsDocument3 pagesList of Impact Factor Journalssaeed meoNo ratings yet
- Improve ARDLDocument7 pagesImprove ARDLsaeed meo100% (5)
- Traditional Granger Causality (1969 1972) VS Toda and Yamamoto (1995)Document9 pagesTraditional Granger Causality (1969 1972) VS Toda and Yamamoto (1995)saeed meo100% (6)
- Regression Results ElementsDocument4 pagesRegression Results Elementssaeed meo100% (1)
- Stability Diognostic Through CUSUMDocument8 pagesStability Diognostic Through CUSUMsaeed meo100% (1)
- Primary Data and Secondary Data: Reliability Test?Document15 pagesPrimary Data and Secondary Data: Reliability Test?saeed meo100% (3)
- AutocorrelationDocument6 pagesAutocorrelationsaeed meo100% (1)
- CV For Teaching SaeedDocument4 pagesCV For Teaching Saeedsaeed meoNo ratings yet
- Improve ARDLDocument7 pagesImprove ARDLsaeed meo100% (5)
- Journal Homepage: - : Manuscript HistoryDocument8 pagesJournal Homepage: - : Manuscript HistoryIJAR JOURNALNo ratings yet
- Estimating Paint in CansDocument4 pagesEstimating Paint in CansPeng GuinNo ratings yet
- UntitledDocument13 pagesUntitledIzabelle KallyNo ratings yet
- MR MLMDocument13 pagesMR MLMMarcio BalestriNo ratings yet
- STA5328 Ramin Shamshiri HW3Document6 pagesSTA5328 Ramin Shamshiri HW3Redmond R. ShamshiriNo ratings yet
- Unit-4 Hypothesis - TestingDocument17 pagesUnit-4 Hypothesis - TestingA2 MotivationNo ratings yet
- MAT2377 C Midterm Test-Solution Key Statistics ConceptsDocument9 pagesMAT2377 C Midterm Test-Solution Key Statistics ConceptsNizar MohammadNo ratings yet
- HANDOUTSdocxDocument4 pagesHANDOUTSdocxsofiaNo ratings yet
- What Is The Sign Test?: Step 1Document10 pagesWhat Is The Sign Test?: Step 1Erica Andrea CacaoNo ratings yet
- Forecast Pro Event ModelsDocument18 pagesForecast Pro Event ModelsYinghui LiuNo ratings yet
- Case Study - Classification of Patients With Abnormal Blood Pressure (N 2000)Document2 pagesCase Study - Classification of Patients With Abnormal Blood Pressure (N 2000)Deepak GuptaNo ratings yet
- The Four Main Research Approaches SummarizedDocument6 pagesThe Four Main Research Approaches SummarizedKarabo SelepeNo ratings yet
- PHCL 612: Logistic Regression Course NotesDocument23 pagesPHCL 612: Logistic Regression Course NotesHOD ODNo ratings yet
- 44 - 1994 WinterDocument74 pages44 - 1994 WinterLinda ZwaneNo ratings yet
- Sartor Concept MisinformationDocument22 pagesSartor Concept MisinformationhealinghumanityNo ratings yet
- 20210620103833D6305 - (1) Defining and Collecting DataDocument33 pages20210620103833D6305 - (1) Defining and Collecting DataDevan LucianNo ratings yet
- US3 Performance Stability Tips Tricks and UnderscoresDocument167 pagesUS3 Performance Stability Tips Tricks and UnderscoreslocutoNo ratings yet
- WstyophDocument28 pagesWstyophjskskkNo ratings yet
- Regression Analysis 2022Document92 pagesRegression Analysis 2022Sai Teja MekalaNo ratings yet
- Annual Education Statistics 2009Document165 pagesAnnual Education Statistics 2009dochula7745No ratings yet
- Hubungan Perawatan Luka Perineum, Pola Makan dan Kepatuhan Minum Obat dengan Penyembuhan Luka PerineumDocument6 pagesHubungan Perawatan Luka Perineum, Pola Makan dan Kepatuhan Minum Obat dengan Penyembuhan Luka PerineumSyella Elnida Depari 1911110487No ratings yet
- SOC CourseDesc WEBDocument14 pagesSOC CourseDesc WEBAlmeda AsuncionNo ratings yet
- 1.08 Example: 1 Exploring DataDocument2 pages1.08 Example: 1 Exploring DataAisha ChohanNo ratings yet
- Alford - The Craft of InquiryDocument12 pagesAlford - The Craft of InquiryAnonymous 2Dl0cn7No ratings yet
- Occupational Stress Among Women Teachers in Purba Medinipur District of West Bengal A StudyDocument5 pagesOccupational Stress Among Women Teachers in Purba Medinipur District of West Bengal A StudyEditor IJTSRDNo ratings yet
- Effect SizesDocument32 pagesEffect SizesdashNo ratings yet
- Dani Reser NewDocument94 pagesDani Reser NewDani TubeNo ratings yet
- Data Collection Methods and TechniquesDocument55 pagesData Collection Methods and Techniquesway2arun100% (1)
- Interpretive Social Science Methods Beyond Qualitative vs QuantitativeDocument21 pagesInterpretive Social Science Methods Beyond Qualitative vs QuantitativeGiulio PalmaNo ratings yet
- zARA & PROJECT DESIGNDocument7 pageszARA & PROJECT DESIGNAmisha SinghNo ratings yet