You might also like
- Statistics 116 - Fall 2004 Theory of Probability Practice Final # 2 - SolutionsDocument7 pagesStatistics 116 - Fall 2004 Theory of Probability Practice Final # 2 - SolutionsKrishna Chaitanya SrikantaNo ratings yet
- Random VaribleDocument12 pagesRandom Varibleramesh_jain_kirtikaNo ratings yet
- 2.3 Conditional Distributions and Expectations. 1Document9 pages2.3 Conditional Distributions and Expectations. 1dNo ratings yet
- Homework 3 SolutionsDocument6 pagesHomework 3 SolutionsislayerNo ratings yet
- Solutions to Problems Lecture 1Document19 pagesSolutions to Problems Lecture 1rohitvanNo ratings yet
- hw4 SolDocument5 pageshw4 SolanthalyaNo ratings yet
- STAT 330 Extra Problems - Chapters 1 To 5Document6 pagesSTAT 330 Extra Problems - Chapters 1 To 5Matt WangNo ratings yet
- Solutions 12Document3 pagesSolutions 12mohamedNo ratings yet
- hw3 SolDocument8 pageshw3 SolanthalyaNo ratings yet
- 5.5. Solved ProblemsDocument61 pages5.5. Solved ProblemsPedro Hernandez100% (3)
- Fall 2013 Math 647 Homework 5Document9 pagesFall 2013 Math 647 Homework 5gsmarasigan08No ratings yet
- Understanding the Expectation of a Random VariableDocument15 pagesUnderstanding the Expectation of a Random VariableLibyaFlowerNo ratings yet
- Sol3 PDFDocument9 pagesSol3 PDFjulianli0220No ratings yet
- EE585 Fall2009 Hw3 SolDocument2 pagesEE585 Fall2009 Hw3 Solnoni496No ratings yet
- DX Dy y X F W: IndependentDocument13 pagesDX Dy y X F W: IndependentdNo ratings yet
- Final Exam Solutions and Probability ConceptsDocument5 pagesFinal Exam Solutions and Probability ConceptsShubhsNo ratings yet
- HW 2 SolutionDocument7 pagesHW 2 SolutionAnonymous 9qJCv5mC0No ratings yet
- Final exam solutions for practice problems in mathDocument9 pagesFinal exam solutions for practice problems in mathJames Hyun Wook ParkNo ratings yet
- M5A42 Applied Stochastic Processes Problem Sheet 1 Solutions Term 1 2010-2011Document8 pagesM5A42 Applied Stochastic Processes Problem Sheet 1 Solutions Term 1 2010-2011paradoxNo ratings yet
- hw3 SolnDocument5 pageshw3 SolnIlham SaputraNo ratings yet
- X + y +Z 0 X y Z 0 X 0 y ZDocument32 pagesX + y +Z 0 X y Z 0 X 0 y Zhnaht_dt88No ratings yet
- Eli Maor, e The Story of A Number, Among ReferencesDocument10 pagesEli Maor, e The Story of A Number, Among ReferencesbdfbdfbfgbfNo ratings yet
- Week 2 - SolutionsDocument9 pagesWeek 2 - SolutionsRodney ChenNo ratings yet
- Tut05 SolDocument4 pagesTut05 SollegitlegitburnerNo ratings yet
- Functions of Random Variable Answers PDFDocument12 pagesFunctions of Random Variable Answers PDFdNo ratings yet
- Review1 PDFDocument22 pagesReview1 PDFdNo ratings yet
- Wχ f F FDocument7 pagesWχ f F FKarl Stessy PremierNo ratings yet
- CaaaDocument2 pagesCaaaOrigamiNo ratings yet
- Solution To Practice Problems For Test 2Document6 pagesSolution To Practice Problems For Test 2Kuldeep KushwahaNo ratings yet
- Waterloo STAT 330 Exam 1 QuestionsDocument4 pagesWaterloo STAT 330 Exam 1 QuestionsrqzhuNo ratings yet
- Hw1sol PDFDocument9 pagesHw1sol PDFRohit BhadauriaNo ratings yet
- Chapter 4Document6 pagesChapter 4TrevorNo ratings yet
- 1112 Ma 1 C Prac HW2 SolnDocument3 pages1112 Ma 1 C Prac HW2 SolnRamon ConpeNo ratings yet
- Stat 515 Final Exam Practice Problems + Solution: Z Z Z ZDocument4 pagesStat 515 Final Exam Practice Problems + Solution: Z Z Z ZSaied Aly SalamahNo ratings yet
- Stats 100A Homework 4 Solution Key ConceptsDocument4 pagesStats 100A Homework 4 Solution Key ConceptsBilly BobNo ratings yet
- MA1521 Solution3Document5 pagesMA1521 Solution3Ray TanNo ratings yet
- Solution:: Probability Assignment - I Name: Soumya Dasgupta (BMC202042)Document2 pagesSolution:: Probability Assignment - I Name: Soumya Dasgupta (BMC202042)Soumya Das guptaNo ratings yet
- Tutorial 2 Partial Derivatives Engineering Applications of Partial DerivativesDocument2 pagesTutorial 2 Partial Derivatives Engineering Applications of Partial Derivatives23065609No ratings yet
- Derivative TextDocument3 pagesDerivative TextTyas Te PyNo ratings yet
- 2.first Order and First DegreeDocument13 pages2.first Order and First Degreeshaz333No ratings yet
- International Competition in Mathematics For Universtiy Students in Plovdiv, Bulgaria 1995Document11 pagesInternational Competition in Mathematics For Universtiy Students in Plovdiv, Bulgaria 1995Phúc Hảo ĐỗNo ratings yet
- ECE 534 Random Processes Problem Set 5Document6 pagesECE 534 Random Processes Problem Set 5anthalyaNo ratings yet
- Applied Mathematics Analysis of Fractional Diffusion EquationsDocument1 pageApplied Mathematics Analysis of Fractional Diffusion Equationsjoginder singhNo ratings yet
- Assignment 2 SolDocument3 pagesAssignment 2 Solching chauNo ratings yet
- Assignment #1 solution key conceptsDocument6 pagesAssignment #1 solution key conceptsAdil AliNo ratings yet
- Is1 Class 1 Group 6 Assignment 3Document12 pagesIs1 Class 1 Group 6 Assignment 3denartha randhikaNo ratings yet
- Problem Set 2 - Solution: X, Y 0.5 0 X, YDocument4 pagesProblem Set 2 - Solution: X, Y 0.5 0 X, YdamnedchildNo ratings yet
- Vector Calculus - Solutions 1: 1. in Each Case, S Is The Shaded Region, Excluding Any Hatched Lines/curves. (A) (B)Document7 pagesVector Calculus - Solutions 1: 1. in Each Case, S Is The Shaded Region, Excluding Any Hatched Lines/curves. (A) (B)Zohiab ZafarNo ratings yet
- Multivariable calculus practice problemsDocument5 pagesMultivariable calculus practice problemslieth-4No ratings yet
- SeveralDocument10 pagesSeveralShraboni SinhaNo ratings yet
- Lecture 12Document2 pagesLecture 12Tanu DixitNo ratings yet
- Solutions To Fall 2006 Math 301 Midterm Problems: N M 1 N NDocument4 pagesSolutions To Fall 2006 Math 301 Midterm Problems: N M 1 N NJacky PoNo ratings yet
- M3 Ispitfeb 2013Document5 pagesM3 Ispitfeb 2013Djordje JanjicNo ratings yet
- Semester III BCA3010 Computer Oriented Numerical MethodsDocument12 pagesSemester III BCA3010 Computer Oriented Numerical MethodsRaman VenmarathoorNo ratings yet
- X K U X U X A: N Be A Random Sample From The DistributionDocument13 pagesX K U X U X A: N Be A Random Sample From The DistributiondNo ratings yet
- Problems AnswersDocument15 pagesProblems Answersanand singhNo ratings yet
- 12 International Mathematics Competition For University StudentsDocument4 pages12 International Mathematics Competition For University StudentsMuhammad Al KahfiNo ratings yet
- The Q-Numerical Range of A Certain: 3 × 3 MatrixDocument10 pagesThe Q-Numerical Range of A Certain: 3 × 3 Matrixjulianli0220No ratings yet
- Sanet - ST 3319225685Document149 pagesSanet - ST 3319225685Angel Cuevas MuñozNo ratings yet
- Calc 1141 2Document27 pagesCalc 1141 2BobNo ratings yet
- 10 FM 1 TN 1ppDocument101 pages10 FM 1 TN 1ppBobNo ratings yet
- History of The Actuarial ProfessionDocument3 pagesHistory of The Actuarial ProfessionBobNo ratings yet
- Linear Algebra Done WrongDocument231 pagesLinear Algebra Done WrongS NandaNo ratings yet
- ACTL4001 Lecture 11Document12 pagesACTL4001 Lecture 11BobNo ratings yet
- Linear Algebra Done WrongDocument231 pagesLinear Algebra Done WrongS NandaNo ratings yet
- ch19 3Document40 pagesch19 3BobNo ratings yet
- 01 7.1 Distributions 13-14Document33 pages01 7.1 Distributions 13-14BobNo ratings yet
- 01 7.1 Distributions 13-14-0 PDF Week 7 New VersionDocument21 pages01 7.1 Distributions 13-14-0 PDF Week 7 New VersionBobNo ratings yet
- ch19 5Document6 pagesch19 5BobNo ratings yet
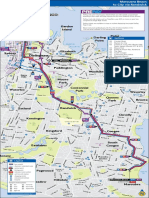
- Maroubra Beach to City via RandwickDocument1 pageMaroubra Beach to City via RandwickBobNo ratings yet
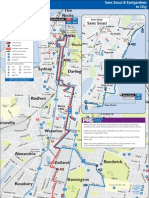
- 301 302 303 X03mapDocument1 page301 302 303 X03mapKyungJun ShinNo ratings yet
- (Carmona R.a.) Interest Rate ModelsDocument58 pages(Carmona R.a.) Interest Rate ModelsBobNo ratings yet
- Maroubra Beach to City via RandwickDocument1 pageMaroubra Beach to City via RandwickBobNo ratings yet
- 301 302 303 X03mapDocument1 page301 302 303 X03mapKyungJun ShinNo ratings yet
- Maroubra Beach to City bus timetable via RandwickDocument19 pagesMaroubra Beach to City bus timetable via RandwickBobNo ratings yet
- Maroubra Beach to City bus timetable via RandwickDocument19 pagesMaroubra Beach to City bus timetable via RandwickBobNo ratings yet
- International: 2020 VisionDocument5 pagesInternational: 2020 VisionBobNo ratings yet
- It's Time To Abolish Retirement (And Here's How To Do It) .: Work, Learn and Play Till You DropDocument47 pagesIt's Time To Abolish Retirement (And Here's How To Do It) .: Work, Learn and Play Till You DropBobNo ratings yet
- Global Financial Crisis Actuary PerspectiveDocument3 pagesGlobal Financial Crisis Actuary PerspectiveBobNo ratings yet
- Signs of Ageing: HealthcareDocument2 pagesSigns of Ageing: HealthcareBobNo ratings yet
- Takaful: An Islamic Alternative To Conventional Insurance Sees Phenomenal GrowthDocument3 pagesTakaful: An Islamic Alternative To Conventional Insurance Sees Phenomenal GrowthBobNo ratings yet
- Is Insurance A Luxury?Document3 pagesIs Insurance A Luxury?BobNo ratings yet
- ch4 1Document42 pagesch4 1BobNo ratings yet
- Chapter 4 Exercise Solutions SpreadsheetDocument5 pagesChapter 4 Exercise Solutions SpreadsheetBobNo ratings yet
- ch4 5Document37 pagesch4 5BobNo ratings yet
- Pension Benefit Design: Flexibility and The Integration of Insurance Over The Life CycleDocument43 pagesPension Benefit Design: Flexibility and The Integration of Insurance Over The Life CycleBobNo ratings yet
- DRAFT STANDARDS FOR DEVELOPING SPREADSHEETSDocument5 pagesDRAFT STANDARDS FOR DEVELOPING SPREADSHEETSBobNo ratings yet
- RVSP NotesDocument123 pagesRVSP NotesSatish Kumar89% (9)
- Binomialdistribution 190124111432 PDFDocument26 pagesBinomialdistribution 190124111432 PDFPremjit SenguptaNo ratings yet
- CE DispersionDocument4 pagesCE DispersionFirmanHidayatNo ratings yet
- Stat 101 - Measures of Dispersion, Skewness, and KurtosisDocument2 pagesStat 101 - Measures of Dispersion, Skewness, and KurtosisAbbey La FortezaNo ratings yet
- Strategic Practice and Homework 5Document14 pagesStrategic Practice and Homework 5yip90100% (1)
- Statistics Economics - Probability DistributionDocument19 pagesStatistics Economics - Probability DistributionsamirNo ratings yet
- Week5 BAMDocument48 pagesWeek5 BAMrajaayyappan317No ratings yet
- The Hyper Geometric DistributionDocument79 pagesThe Hyper Geometric DistributionZhiqiang XuNo ratings yet
- Data 1 Histogram Data 2 Histogram: Data 1 Cumulative Distributions Data 2 Cumulative DistributionsDocument2 pagesData 1 Histogram Data 2 Histogram: Data 1 Cumulative Distributions Data 2 Cumulative DistributionsKhalil KhdourNo ratings yet
- Probability Distribution PDFDocument44 pagesProbability Distribution PDFSimon KarkiNo ratings yet
- Learning Discrete Random VariablesDocument15 pagesLearning Discrete Random VariablesNikitasNo ratings yet
- Republic of The Philippines BED DepartmentDocument4 pagesRepublic of The Philippines BED DepartmentEmyren ApuyaNo ratings yet
- Some Common Probability DistributionsDocument92 pagesSome Common Probability DistributionsAnonymous KS0gHXNo ratings yet
- Simulation and Modelling - Cat TwoDocument3 pagesSimulation and Modelling - Cat TwoKennedy KamauNo ratings yet
- Statistics 427-SP 2011 Midterm II - Solution: Question 1 (6x2.5 Points)Document7 pagesStatistics 427-SP 2011 Midterm II - Solution: Question 1 (6x2.5 Points)Shahin AgahzadehNo ratings yet
- Normal Distribution Ws & MsDocument3 pagesNormal Distribution Ws & MsKoteswararao PNo ratings yet
- STA301 My Student Quiz-3 by Vu Topper RMDocument9 pagesSTA301 My Student Quiz-3 by Vu Topper RMHamza ButtNo ratings yet
- Probability and Statistical Analysis: Chapter FiveDocument25 pagesProbability and Statistical Analysis: Chapter Fiveyusuf yuyuNo ratings yet
- Hint - Area Under The Must Be 1Document16 pagesHint - Area Under The Must Be 1JASHWIN GAUTAMNo ratings yet
- ActuarDocument142 pagesActuarjose zepedaNo ratings yet
- Fundamentals of Data Analytics (FDA) CourseDocument3 pagesFundamentals of Data Analytics (FDA) Courseswaroop666No ratings yet
- Lecture 4 Disc R Prob F 2016Document35 pagesLecture 4 Disc R Prob F 2016Mobasher Messi0% (1)
- Doubtnut Today: Baap of All Formula ListsDocument4 pagesDoubtnut Today: Baap of All Formula ListsMichael CrichtonNo ratings yet
- Exponential Family GLMDocument5 pagesExponential Family GLMSJNo ratings yet
- Poisson Distribution & ProblemsDocument2 pagesPoisson Distribution & ProblemsEunnicePanaliganNo ratings yet
- Problem 1. The Number of Pages in A PDF Document You Create Has A Discrete UniformDocument3 pagesProblem 1. The Number of Pages in A PDF Document You Create Has A Discrete Uniform김영휘No ratings yet
- Probability and Statistics Course FileDocument72 pagesProbability and Statistics Course FileAkash BahugunaNo ratings yet
- Mumbai University - FYBSc - Syllabus - 4.60 Statistics PDFDocument7 pagesMumbai University - FYBSc - Syllabus - 4.60 Statistics PDFreshmarautNo ratings yet
- Some Discrete Probability DistributionsDocument41 pagesSome Discrete Probability Distributionsمؤيد العتيبيNo ratings yet
- Uji Kecocokan Data Hidrologi Terhadap Distribusi KemungkinanDocument63 pagesUji Kecocokan Data Hidrologi Terhadap Distribusi KemungkinanKartika SukmaNo ratings yet