You might also like
- Embedded Systems Design: Pipelining and Instruction SchedulingDocument48 pagesEmbedded Systems Design: Pipelining and Instruction SchedulingMisbah Sajid ChaudhryNo ratings yet
- Applied Process Design for Chemical and Petrochemical Plants: Volume 1From EverandApplied Process Design for Chemical and Petrochemical Plants: Volume 1Rating: 3.5 out of 5 stars3.5/5 (3)
- The Big Picture: Requirements Algorithms Prog. Lang./Os Isa Uarch Circuit DeviceDocument60 pagesThe Big Picture: Requirements Algorithms Prog. Lang./Os Isa Uarch Circuit DevicevshlvvkNo ratings yet
- Risc in Pipe IneDocument39 pagesRisc in Pipe IneNagarjuna ReddyNo ratings yet
- Chapter4 Pipelining END FA11Document84 pagesChapter4 Pipelining END FA11Aditya GadgilNo ratings yet
- Projects With Microcontrollers And PICCFrom EverandProjects With Microcontrollers And PICCRating: 5 out of 5 stars5/5 (1)
- Lec07 Pipelining ReviewDocument121 pagesLec07 Pipelining ReviewdoomachaleyNo ratings yet
- Appendix ADocument93 pagesAppendix AzeewoxNo ratings yet
- Lec 04 Pipeline D ProcessorDocument106 pagesLec 04 Pipeline D ProcessorMaheshKotaNo ratings yet
- Pipelining Preview: Basics & ChallengesDocument75 pagesPipelining Preview: Basics & ChallengesdoomachaleyNo ratings yet
- Chapter 4 The ProcessorDocument131 pagesChapter 4 The ProcessorRahman AsmadNo ratings yet
- Lec04 Pipelining Intro&hazardsDocument77 pagesLec04 Pipelining Intro&hazardsdoomachaleyNo ratings yet
- Pipeline HazardsDocument94 pagesPipeline HazardsManasa RavelaNo ratings yet
- HRY-312 Computer Organization Introduction To PipeliningDocument30 pagesHRY-312 Computer Organization Introduction To Pipelininggami2No ratings yet
- Chapter4 Pipelining END FA11Document84 pagesChapter4 Pipelining END FA11K SriNo ratings yet
- Lec18 PipelineDocument59 pagesLec18 PipelineAliGhandiNo ratings yet
- Computer Organization and Design Pipeliing-Chapter+4 SlidesDocument131 pagesComputer Organization and Design Pipeliing-Chapter+4 SlidesVishlesh PatelNo ratings yet
- Chapter 04 Computer Organization and Design, Fifth Edition: The Hardware/Software Interface (The Morgan Kaufmann Series in Computer Architecture and Design) 5th EditionDocument137 pagesChapter 04 Computer Organization and Design, Fifth Edition: The Hardware/Software Interface (The Morgan Kaufmann Series in Computer Architecture and Design) 5th EditionPriyanka Meena67% (6)
- Pipe LiningDocument29 pagesPipe LiningAnkitShingalaNo ratings yet
- UNIT-5: Pipeline and Vector ProcessingDocument63 pagesUNIT-5: Pipeline and Vector ProcessingAkash KankariaNo ratings yet
- CAO Pipelining LectureDocument50 pagesCAO Pipelining LectureSabareesh MuralidharanNo ratings yet
- Ca07 2014 PDFDocument56 pagesCa07 2014 PDFPance CvetkovskiNo ratings yet
- 4 20 10 PDFDocument12 pages4 20 10 PDFasifsultanNo ratings yet
- Pipelines - #1 RISC ISA Without PipeDocument9 pagesPipelines - #1 RISC ISA Without PipeHussain HajjarNo ratings yet
- CSC15107: Computer Architecture: Lecture - 13, 14: Pipelined Processor 01, 03 September 2020Document32 pagesCSC15107: Computer Architecture: Lecture - 13, 14: Pipelined Processor 01, 03 September 202018je0140 anshbafnaNo ratings yet
- Module1 UPDDocument72 pagesModule1 UPDZhanzhi LiuNo ratings yet
- Lect5 Pipelining1Document42 pagesLect5 Pipelining1Rida AmjadNo ratings yet
- Chapter 4 Part 2Document50 pagesChapter 4 Part 2gioaminefreiha65No ratings yet
- Chapter6 - PipeliningDocument61 pagesChapter6 - PipeliningNimmy MariamNo ratings yet
- Chapter6 - PipeliningDocument61 pagesChapter6 - PipeliningPrakash SubramanianNo ratings yet
- Content: - Introduction To Pipeline Hazard - Structural Hazard - Data Hazard - Control HazardDocument27 pagesContent: - Introduction To Pipeline Hazard - Structural Hazard - Data Hazard - Control HazardAhmed NabilNo ratings yet
- Pipelining & Riscs: Pipelining Used Key Implementation Technique To Build Fast Processors. ItDocument6 pagesPipelining & Riscs: Pipelining Used Key Implementation Technique To Build Fast Processors. Itfayzee945150No ratings yet
- Computer Organization: An Introduction To RISC Hardware: 6.1 An Overview of PipeliningDocument12 pagesComputer Organization: An Introduction To RISC Hardware: 6.1 An Overview of PipeliningAmrendra Kumar MishraNo ratings yet
- CS 211: Computer Architecture: Instructor: Prof. Bhagi NarahariDocument82 pagesCS 211: Computer Architecture: Instructor: Prof. Bhagi NarahariDuncan KingNo ratings yet
- Co - Unit Ii - IiDocument34 pagesCo - Unit Ii - Iiy22cd125No ratings yet
- Instruction PipelineDocument27 pagesInstruction PipelineEswin AngelNo ratings yet
- What Is PipeliningDocument47 pagesWhat Is PipeliningBijay MishraNo ratings yet
- 3 Introduction PipelineDocument149 pages3 Introduction PipelineIshwar MhtNo ratings yet
- The Processor: The Hardware/Software Interface 5Document149 pagesThe Processor: The Hardware/Software Interface 5ayylmao kekNo ratings yet
- EECS 252 Graduate Computer Architecture Lec 3 - Performance + Pipeline ReviewDocument48 pagesEECS 252 Graduate Computer Architecture Lec 3 - Performance + Pipeline ReviewNemanja LukićNo ratings yet
- ch09 Morris ManoDocument15 pagesch09 Morris ManoYogita Negi RawatNo ratings yet
- Pipelining and Vector ProcessingDocument28 pagesPipelining and Vector ProcessingBinuVargisNo ratings yet
- Pipeline HazardsDocument94 pagesPipeline HazardsdrawthelinemiruNo ratings yet
- Module 4Document12 pagesModule 4Bijay NagNo ratings yet
- Pipeline HazardsDocument39 pagesPipeline HazardsPranidhi RajvanshiNo ratings yet
- Lecture 9: Case Study - MIPS R4000 and Introduction To Advanced PipeliningDocument23 pagesLecture 9: Case Study - MIPS R4000 and Introduction To Advanced PipeliningNithin KumarNo ratings yet
- DPCO Unit 4 2mark Q&ADocument11 pagesDPCO Unit 4 2mark Q&Akanimozhi rajasekarenNo ratings yet
- CS 211: Computer Architecture: Instructor: Prof. Bhagi NarahariDocument82 pagesCS 211: Computer Architecture: Instructor: Prof. Bhagi NarahariElizabeth AliazNo ratings yet
- Basic Pipelining PDFDocument39 pagesBasic Pipelining PDFAhmed Ali AlsubaihNo ratings yet
- CSO Computer ProgrammingDocument73 pagesCSO Computer ProgrammingAjNo ratings yet
- L4 - The Processor-Pipelined2Document47 pagesL4 - The Processor-Pipelined2kates15No ratings yet
- ILP - Appendix C PDFDocument52 pagesILP - Appendix C PDFDhananjay JahagirdarNo ratings yet
- Ca Unit 2.2Document22 pagesCa Unit 2.2GuruKPO100% (2)
- CA Classes-96-100Document5 pagesCA Classes-96-100SrinivasaRaoNo ratings yet
- Chapter 2 Part FourDocument76 pagesChapter 2 Part FoursileNo ratings yet
- Homework 2Document8 pagesHomework 2Deepak BegrajkaNo ratings yet
- ACA Unit 2,7th Sem CSEDocument13 pagesACA Unit 2,7th Sem CSEReshma BJNo ratings yet
- SNUG PaperDocument33 pagesSNUG Paperkumarguptav91No ratings yet
- Mechanical ProjectsDocument21 pagesMechanical ProjectsvenugopalmangaNo ratings yet
- Crosstalk PDFDocument177 pagesCrosstalk PDFKhadar BashaNo ratings yet
- Inherited Connections PDFDocument230 pagesInherited Connections PDFkumarguptav91No ratings yet
- Welding 1 PDFDocument9 pagesWelding 1 PDFkumarguptav91No ratings yet
- Custom Integrated Circuits ConferenceDocument4 pagesCustom Integrated Circuits Conferencekumarguptav91No ratings yet
- CMOS Transistor Layout KungFuDocument39 pagesCMOS Transistor Layout KungFuAyo Iji100% (5)
- Multipurpose Exercise Cycle: Khan Mohd Aqeel Rizvi Sameer AbbasDocument3 pagesMultipurpose Exercise Cycle: Khan Mohd Aqeel Rizvi Sameer Abbaskumarguptav91No ratings yet
- DC DC ConvertorDocument45 pagesDC DC Convertorkumarguptav91No ratings yet
- L16 Multicycle MIPSDocument38 pagesL16 Multicycle MIPSkumarguptav91No ratings yet
- MIPS ImplementationDocument101 pagesMIPS ImplementationdilinoxNo ratings yet
- Report On Evolution of ProcessorDocument24 pagesReport On Evolution of Processorkumarguptav91No ratings yet
- Carry Save AdderDocument4 pagesCarry Save AdderAyush GeraNo ratings yet
- L10Document24 pagesL10Jay PadaliyaNo ratings yet
- Synchronization at MITDocument27 pagesSynchronization at MITkumarguptav91No ratings yet
- Sequential Design Prob at MITDocument2 pagesSequential Design Prob at MITkumarguptav91No ratings yet
- Synchronization Problems With Answers at MITDocument9 pagesSynchronization Problems With Answers at MITkumarguptav91No ratings yet
- L4 - Propagation Delay, Circuit Timing & Adder DesignDocument57 pagesL4 - Propagation Delay, Circuit Timing & Adder DesignRayasam RakhiNo ratings yet
- 1993.05.impact of Signal Transition Time On Path Delay Computation - IEEETransCirSysIIDocument8 pages1993.05.impact of Signal Transition Time On Path Delay Computation - IEEETransCirSysIIkumarguptav91No ratings yet
- Sequential Design Prob With Solutions at MITDocument10 pagesSequential Design Prob With Solutions at MITkumarguptav91No ratings yet
- FSM Problems at MITDocument1 pageFSM Problems at MITkumarguptav91No ratings yet
- Synopsys Class 2 5 1Document67 pagesSynopsys Class 2 5 1prashanth kumarNo ratings yet
- Logic Synthesis at MITDocument8 pagesLogic Synthesis at MITkumarguptav91No ratings yet
- Sequential Logic at MITDocument7 pagesSequential Logic at MITkumarguptav91No ratings yet
- Chapter 18Document10 pagesChapter 18kumarguptav91No ratings yet
- Clock Gating TechniquesDocument9 pagesClock Gating Techniqueskumarguptav91No ratings yet
- Clocking MITDocument16 pagesClocking MITkumarguptav91No ratings yet
- Analysis Design Asynchronous Sequential CircuitsDocument72 pagesAnalysis Design Asynchronous Sequential Circuitskumarguptav9175% (4)
- 12 SeqDesignDocument37 pages12 SeqDesignkumarguptav91No ratings yet
- Bipro - TD7G78M - 10BB - 580 - 600WDocument2 pagesBipro - TD7G78M - 10BB - 580 - 600WcarloscostacarreteroNo ratings yet
- Fire Alarm SystemDocument9 pagesFire Alarm SystemMATE0No ratings yet
- The Quest For Robust Wireless High-Def Video Connections: Voice of The EngineerDocument56 pagesThe Quest For Robust Wireless High-Def Video Connections: Voice of The EngineerJim Redpath100% (2)
- Honeywell Diff P Switch DPSDocument2 pagesHoneywell Diff P Switch DPSFrinaru CiprianNo ratings yet
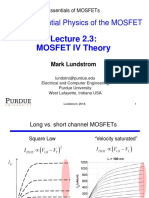
- ECEPurdue MOSFET Lundstrom L2.3v3bDocument22 pagesECEPurdue MOSFET Lundstrom L2.3v3balNo ratings yet
- Connecting Things Chapter 2 Quiz - Attempt ReviewDocument6 pagesConnecting Things Chapter 2 Quiz - Attempt ReviewToeloesNo ratings yet
- Parker Pneumatic Sensors PDFDocument25 pagesParker Pneumatic Sensors PDFyouri59490No ratings yet
- ABPROG User's ManualDocument35 pagesABPROG User's ManualMiguel VegaNo ratings yet
- Accumax: Advanced Digital Radiometer/Photometer KitDocument2 pagesAccumax: Advanced Digital Radiometer/Photometer Kitvignesh seenirajNo ratings yet
- Emerging Technologies of Flexible Pressure SensorsDocument24 pagesEmerging Technologies of Flexible Pressure Sensorsrizky ibnuNo ratings yet
- Calculo de Filtros Armonicos AccusineDocument2 pagesCalculo de Filtros Armonicos AccusineYolandaNo ratings yet
- Higher Voltage Capacitance Becomes Increasingly ImportantDocument2 pagesHigher Voltage Capacitance Becomes Increasingly ImportantdevrajNo ratings yet
- Samsung Sustainability Reports 2014Document69 pagesSamsung Sustainability Reports 2014nicholasdeleoncircaNo ratings yet
- Pumps Catalog enDocument36 pagesPumps Catalog enJoão Paulo FogarolliNo ratings yet
- 3B40ZC5570P1 Fe55av - SpecificationsDocument21 pages3B40ZC5570P1 Fe55av - SpecificationsThanh BarcaNo ratings yet
- Bingo - Marketing EnvironmentDocument4 pagesBingo - Marketing EnvironmentFahad MushtaqNo ratings yet
- InTouch Bed - EnService Manual FL27Document247 pagesInTouch Bed - EnService Manual FL27Juan CarrascoNo ratings yet
- Arena Details: 1. Death RaceDocument6 pagesArena Details: 1. Death Racemanik_chand_patnaikNo ratings yet
- CIE IGCSE Mock Exam Topics 1 To 5, 9, 10Document6 pagesCIE IGCSE Mock Exam Topics 1 To 5, 9, 10Jenkins CK TsangNo ratings yet
- SportDog In-Ground FenceDocument24 pagesSportDog In-Ground Fencesc83No ratings yet
- 2023 - Adv Funct Materials - Frequency Modulation Based LongWave Infrared Detection and Imaging at Room TemperatureDocument9 pages2023 - Adv Funct Materials - Frequency Modulation Based LongWave Infrared Detection and Imaging at Room Temperaturemecoolboy82No ratings yet
- Applied Physics Lab ManualDocument36 pagesApplied Physics Lab Manualاحمد علیNo ratings yet
- Machine Vision - The Past, The Present and The FutureDocument30 pagesMachine Vision - The Past, The Present and The FutureCassiano Kleinert CasagrandeNo ratings yet
- BMI Kenya Telecommunications Report Q4 2014 - 04115036Document97 pagesBMI Kenya Telecommunications Report Q4 2014 - 04115036eugene123No ratings yet
- Analog and Digital Electronics Lab Manual PDFDocument109 pagesAnalog and Digital Electronics Lab Manual PDFShaun ThomasNo ratings yet
- Guide To Low Voltage System Design and SelectivityDocument40 pagesGuide To Low Voltage System Design and SelectivityShung Tak ChanNo ratings yet
- Introduction To Computers and Java: Walter Savitch Frank M. CarranoDocument77 pagesIntroduction To Computers and Java: Walter Savitch Frank M. CarranoBrandon KozakNo ratings yet
- Series: Weighing IndicatorDocument25 pagesSeries: Weighing Indicatorمحمود القمريNo ratings yet
- Component Parts KBDocument12 pagesComponent Parts KBPato PuruncajasNo ratings yet
- Impact of Storage Devices On The EnviromentDocument4 pagesImpact of Storage Devices On The Enviromentalfredsamsele2100% (1)
- Arizona, Utah & New Mexico: A Guide to the State & National ParksFrom EverandArizona, Utah & New Mexico: A Guide to the State & National ParksRating: 4 out of 5 stars4/5 (1)
- Japanese Gardens Revealed and Explained: Things To Know About The Worlds Most Beautiful GardensFrom EverandJapanese Gardens Revealed and Explained: Things To Know About The Worlds Most Beautiful GardensNo ratings yet
- The Bahamas a Taste of the Islands ExcerptFrom EverandThe Bahamas a Taste of the Islands ExcerptRating: 4 out of 5 stars4/5 (1)
- New York & New Jersey: A Guide to the State & National ParksFrom EverandNew York & New Jersey: A Guide to the State & National ParksNo ratings yet
- Naples, Sorrento & the Amalfi Coast Adventure Guide: Capri, Ischia, Pompeii & PositanoFrom EverandNaples, Sorrento & the Amalfi Coast Adventure Guide: Capri, Ischia, Pompeii & PositanoRating: 5 out of 5 stars5/5 (1)
- South Central Alaska a Guide to the Hiking & Canoeing Trails ExcerptFrom EverandSouth Central Alaska a Guide to the Hiking & Canoeing Trails ExcerptRating: 5 out of 5 stars5/5 (1)