You might also like
- Face Recognition Using Pca On Matlab: A Synopsis Report ONDocument8 pagesFace Recognition Using Pca On Matlab: A Synopsis Report ONArpit SharmaNo ratings yet
- A Face Recognition Scheme Based On Principle Component Analysis and Wavelet DecompositionDocument5 pagesA Face Recognition Scheme Based On Principle Component Analysis and Wavelet DecompositionInternational Organization of Scientific Research (IOSR)No ratings yet
- A Novel Approach For Content Retrieval From Recognition AlgorithmDocument5 pagesA Novel Approach For Content Retrieval From Recognition AlgorithmInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Study On Advancement in Face Recognition Technology: Arpit Arora, Abhishek KR - Rai, DR - Leena AryaDocument4 pagesStudy On Advancement in Face Recognition Technology: Arpit Arora, Abhishek KR - Rai, DR - Leena AryaRavindra KumarNo ratings yet
- Face Recognition Using Eigen Faces and Artificial Neural NetworkDocument6 pagesFace Recognition Using Eigen Faces and Artificial Neural Networkmnry414No ratings yet
- Face Recognition Using Linear Discriminant Analysis: Manju Bala, Priti Singh, Mahendra Singh MeenaDocument8 pagesFace Recognition Using Linear Discriminant Analysis: Manju Bala, Priti Singh, Mahendra Singh MeenaAbid BadshahNo ratings yet
- Manisha Satone 2014Document14 pagesManisha Satone 2014Neeraj KannaugiyaNo ratings yet
- Face Recognition Techniques: A Review: Rajeshwar Dass, Ritu Rani, Dharmender KumarDocument9 pagesFace Recognition Techniques: A Review: Rajeshwar Dass, Ritu Rani, Dharmender KumarIJERDNo ratings yet
- Comparative Analysis of PCA and 2DPCA in Face RecognitionDocument7 pagesComparative Analysis of PCA and 2DPCA in Face RecognitionDinh Khai LaiNo ratings yet
- Image ProcessingDocument33 pagesImage ProcessingTejaswini ReddyNo ratings yet
- Capstone Project ReportDocument46 pagesCapstone Project ReportNavdeep Singh ButterNo ratings yet
- Ieee Conference Paper TemplateDocument4 pagesIeee Conference Paper TemplateMati ur rahman khanNo ratings yet
- Chapter 1Document20 pagesChapter 1AmanNo ratings yet
- New Approaches to Image Processing based Failure Analysis of Nano-Scale ULSI DevicesFrom EverandNew Approaches to Image Processing based Failure Analysis of Nano-Scale ULSI DevicesRating: 5 out of 5 stars5/5 (1)
- An Effective Approach in Face Recognition Using Image Processing ConceptsDocument5 pagesAn Effective Approach in Face Recognition Using Image Processing ConceptsInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Face Recognization: A Review: International Journal of Application or Innovation in Engineering & Management (IJAIEM)Document3 pagesFace Recognization: A Review: International Journal of Application or Innovation in Engineering & Management (IJAIEM)International Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Redundancy in Face Image RecognitionDocument4 pagesRedundancy in Face Image RecognitionIJAERS JOURNALNo ratings yet
- Image-Based Face Detection and Recognition Using MATLABDocument4 pagesImage-Based Face Detection and Recognition Using MATLABIjcemJournal100% (1)
- Face RecognitionDocument8 pagesFace RecognitionDivya VarshaaNo ratings yet
- Irjet V4i5112 PDFDocument5 pagesIrjet V4i5112 PDFAnonymous plQ7aHUNo ratings yet
- Image Classification Techniques-A SurveyDocument4 pagesImage Classification Techniques-A SurveyInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Low Resolution Face Recognition Using Mixture of ExpertsDocument5 pagesLow Resolution Face Recognition Using Mixture of ExpertsTALLA_LOKESHNo ratings yet
- Thesis On Face Recognition Using PcaDocument8 pagesThesis On Face Recognition Using Pcabsqbr7px100% (2)
- Face Detection & Face Recognition Using Open Computer Vision ClassifiesDocument19 pagesFace Detection & Face Recognition Using Open Computer Vision ClassifiesAnand0% (1)
- Facial Landmark Detection With Sentiment RecognitionDocument7 pagesFacial Landmark Detection With Sentiment RecognitionIJRASETPublicationsNo ratings yet
- Face Recognition Report 1Document26 pagesFace Recognition Report 1Binny DaraNo ratings yet
- Applications of Linear Algebra in Facial RecognitionDocument3 pagesApplications of Linear Algebra in Facial RecognitionRAJ JAISWALNo ratings yet
- IJAREEIE Paper TemplateDocument8 pagesIJAREEIE Paper TemplateAntriksh BorkarNo ratings yet
- Micropaterns On ImageryDocument19 pagesMicropaterns On ImageryAntonio RamírezNo ratings yet
- Seminar Project - Face - RecognitionDocument58 pagesSeminar Project - Face - RecognitionItaliya BhaktiNo ratings yet
- Face Detection Using Open CV Machine Learning: Software Engineering ProjectDocument14 pagesFace Detection Using Open CV Machine Learning: Software Engineering ProjectAbdulmajid NiazaiNo ratings yet
- Face Recognition Techniques: ECE533 - Image Processing ProjectDocument15 pagesFace Recognition Techniques: ECE533 - Image Processing ProjectsrulakshNo ratings yet
- Facial Expression Recognition Using Constructive Feedforward Neural Networks 01298906Document8 pagesFacial Expression Recognition Using Constructive Feedforward Neural Networks 01298906Mitul RawatNo ratings yet
- A Literature Survey On Face Recognition TechniquesDocument6 pagesA Literature Survey On Face Recognition TechniquesseventhsensegroupNo ratings yet
- Representations of Human Faces: Max-Planck-Institut Für Biologische Kybernetik Spemannstr. 38, D-72076 Tübingen, GermanyDocument17 pagesRepresentations of Human Faces: Max-Planck-Institut Für Biologische Kybernetik Spemannstr. 38, D-72076 Tübingen, GermanyNiko TrojeNo ratings yet
- Recognitionand Solutionfor Handwritten Equation Using Convolutional Neural NetworkDocument7 pagesRecognitionand Solutionfor Handwritten Equation Using Convolutional Neural NetworkSanjana DevadhiaNo ratings yet
- Imageclassifier DocumentationDocument29 pagesImageclassifier DocumentationVasavi DaramNo ratings yet
- Mixture Models and ApplicationsFrom EverandMixture Models and ApplicationsNizar BouguilaNo ratings yet
- Face RecognitionDocument570 pagesFace RecognitionThomas Kudel0% (2)
- Human Face Detection and Identification of Facial Expressions Using MATLABDocument8 pagesHuman Face Detection and Identification of Facial Expressions Using MATLABNIET Journal of Engineering & Technology(NIETJET)No ratings yet
- (IJET-V1I6P15) Authors: Sadhana Raut, Poonam Rohani, Sumera Shaikh, Tehesin Shikilkar, Mrs. G. J. ChhajedDocument7 pages(IJET-V1I6P15) Authors: Sadhana Raut, Poonam Rohani, Sumera Shaikh, Tehesin Shikilkar, Mrs. G. J. ChhajedInternational Journal of Engineering and TechniquesNo ratings yet
- Effect of Distance Measures in Pca Based Face: RecognitionDocument15 pagesEffect of Distance Measures in Pca Based Face: Recognitionadmin2146No ratings yet
- Review of Face Detection System Using Neural NetworkDocument5 pagesReview of Face Detection System Using Neural NetworkVIVA-TECH IJRINo ratings yet
- Face Recognition PaperDocument7 pagesFace Recognition PaperPuja RoyNo ratings yet
- Pattern Recognition - A Statistical ApproachDocument6 pagesPattern Recognition - A Statistical ApproachSimmi JoshiNo ratings yet
- Quotient Space Based Problem Solving: A Theoretical Foundation of Granular ComputingFrom EverandQuotient Space Based Problem Solving: A Theoretical Foundation of Granular ComputingNo ratings yet
- Implementation of Hardware Based Real-Time Face Recognition Method Using Reconfigurable Network of Memristive Threshold Logic CellsDocument10 pagesImplementation of Hardware Based Real-Time Face Recognition Method Using Reconfigurable Network of Memristive Threshold Logic CellsIAEME PublicationNo ratings yet
- Face Detection by Means of Skin Detection: September 2008Document12 pagesFace Detection by Means of Skin Detection: September 2008shahadNo ratings yet
- Openface: A General-Purpose Face Recognition Library With Mobile ApplicationsDocument20 pagesOpenface: A General-Purpose Face Recognition Library With Mobile Applications『ẨBŃ』 YEMENNo ratings yet
- A Comparative Analysis of Face Recognition Models On Masked FacesDocument4 pagesA Comparative Analysis of Face Recognition Models On Masked FacesSiddharth KoliparaNo ratings yet
- System Requirement Specification For Face Recognition SystemDocument18 pagesSystem Requirement Specification For Face Recognition Systemrohanrj350% (6)
- CH01Document12 pagesCH01Latta SakthyyNo ratings yet
- Face Recognition Using Discrete Cosine Transform Plus Linear Discriminant AnalysisDocument4 pagesFace Recognition Using Discrete Cosine Transform Plus Linear Discriminant AnalysisSalwa Khaled YounesNo ratings yet
- Application of Soft Computing To Face RecognitionDocument68 pagesApplication of Soft Computing To Face RecognitionAbdullah GubbiNo ratings yet
- Intelligent Facial Recognition and Retrieval From Facial Image DatabasesDocument6 pagesIntelligent Facial Recognition and Retrieval From Facial Image DatabasesTJPRC PublicationsNo ratings yet
- Face Recognition System Using Self Organizing Feature Map and Appearance Based ApproachDocument6 pagesFace Recognition System Using Self Organizing Feature Map and Appearance Based ApproachEditor IJTSRDNo ratings yet
- Victim Detection With Infrared Camera in A "Rescue Robot": Saeed MoradiDocument7 pagesVictim Detection With Infrared Camera in A "Rescue Robot": Saeed MoradiKucIng HijAuNo ratings yet
- Brahma ShutraDocument2 pagesBrahma ShutraArpit SharmaNo ratings yet
- Naresh Kumar Sharma: ST THDocument2 pagesNaresh Kumar Sharma: ST THArpit SharmaNo ratings yet
- Back TrackDocument5 pagesBack TrackArpit SharmaNo ratings yet
- Cover LetterDocument2 pagesCover LetterArpit SharmaNo ratings yet
- Sbi Po Invoice 4441048026Document1 pageSbi Po Invoice 4441048026Arpit SharmaNo ratings yet
- ADBMS Lab ManualDocument33 pagesADBMS Lab ManualArpit SharmaNo ratings yet
- Viva QuestionsDocument12 pagesViva QuestionsArpit SharmaNo ratings yet
- Dak Edsn & Pull-Out Rate Card Wef 15th Jan. 2014Document1 pageDak Edsn & Pull-Out Rate Card Wef 15th Jan. 2014Arpit SharmaNo ratings yet
- Enhanced Table Maintenance With Automatic Change Recording - My Experiments With ABAPDocument6 pagesEnhanced Table Maintenance With Automatic Change Recording - My Experiments With ABAPpraneeth abapNo ratings yet
- WINK Whitepaper ZH CNDocument38 pagesWINK Whitepaper ZH CNDennis tangNo ratings yet
- MDM 103HF1 BusinessEntityServicesGuide enDocument193 pagesMDM 103HF1 BusinessEntityServicesGuide enjeremy depazNo ratings yet
- Tensor Flow 101Document58 pagesTensor Flow 101Narasimhaiah Narahari100% (7)
- Localizacao Brasil Servicos PDFDocument68 pagesLocalizacao Brasil Servicos PDFMarcelo MestiNo ratings yet
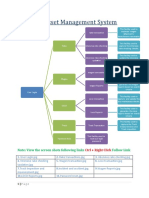
- Rail Asset Management System: Follow LinkDocument4 pagesRail Asset Management System: Follow LinkAbhiroop AwasthiNo ratings yet
- Logcat Prev CSC LogDocument278 pagesLogcat Prev CSC LogValentina GarcíaNo ratings yet
- SSIS Package CreationDocument648 pagesSSIS Package CreationShanmuga VadivelNo ratings yet
- Pagano Et Al. - 2023 - A Survey On LoRa For Smart Agriculture Current TRDocument16 pagesPagano Et Al. - 2023 - A Survey On LoRa For Smart Agriculture Current TRIndra RosadiNo ratings yet
- SafariDocument3 pagesSafariAntony MervinNo ratings yet
- First Analysis of Site After SWAPDocument23 pagesFirst Analysis of Site After SWAPRaviNo ratings yet
- Resumen SW NewDocument20 pagesResumen SW NewcurzNo ratings yet
- Duxbury ManualDocument173 pagesDuxbury ManualZulfiquar AliNo ratings yet
- Systems Analysis and Design: Alan Dennis, Barbara Haley Wixom, and Roberta Roth John Wiley & Sons, IncDocument42 pagesSystems Analysis and Design: Alan Dennis, Barbara Haley Wixom, and Roberta Roth John Wiley & Sons, IncCCIE CCIENo ratings yet
- ICt Test PDFDocument8 pagesICt Test PDFHenryPDTNo ratings yet
- Configuration Managent Plan AS9100 & AS9006 ChecklistDocument6 pagesConfiguration Managent Plan AS9100 & AS9006 Checklistahmed AwadNo ratings yet
- Spectec Amos MaintenanceDocument2 pagesSpectec Amos Maintenanceswapneel_kulkarniNo ratings yet
- Sap Integrated Business Planning Ibp Sap Integrated Business Planning Ibp 3Document7 pagesSap Integrated Business Planning Ibp Sap Integrated Business Planning Ibp 3Narasimha Prasad BhatNo ratings yet
- New Microsoft Word DocumentDocument23 pagesNew Microsoft Word DocumentHitesh BhatnagarNo ratings yet
- Exercise 2: 2. Data Storage: Digitizing and Data StructureDocument13 pagesExercise 2: 2. Data Storage: Digitizing and Data StructurebirukNo ratings yet
- Prashant (1) .Shrivastava Resume (System Admin)Document2 pagesPrashant (1) .Shrivastava Resume (System Admin)Sapna MathurNo ratings yet
- F21 Lite User ManualDocument85 pagesF21 Lite User ManualIT MANAGERNo ratings yet
- DRS 2018 Simeone Et Al. FinalDocument13 pagesDRS 2018 Simeone Et Al. FinalLuca SimeoneNo ratings yet
- Prisma Certified Cloud Security Engineer (PCCSE) BlueprintDocument4 pagesPrisma Certified Cloud Security Engineer (PCCSE) BlueprintJohn LinNo ratings yet
- Java AssignmentDocument55 pagesJava AssignmentAnanya BhagatNo ratings yet
- Sap SD TablesDocument4 pagesSap SD TablesLokesh DoraNo ratings yet
- Introduction To AlgorithmsDocument6 pagesIntroduction To Algorithmsavi05raj0% (1)
- What Is Unicast and Multicast Object?Document5 pagesWhat Is Unicast and Multicast Object?Raghu TejaNo ratings yet
- NetBeans Platform 6.5 BookDocument3 pagesNetBeans Platform 6.5 BookChristianEnriquePortillaPauca50% (2)
- Contoso Sample DAX FormulasDocument19 pagesContoso Sample DAX FormulasKirk100% (1)