You might also like
- Laksman2019 Article TheStochasticOpportunisticReplDocument23 pagesLaksman2019 Article TheStochasticOpportunisticReplJai PandeyNo ratings yet
- Integrating CDU, FCC and Product Blending Models Into Refinery Planning PDFDocument19 pagesIntegrating CDU, FCC and Product Blending Models Into Refinery Planning PDFahmed1581973No ratings yet
- Assisted History Matching For Petroleum Reservoirs in The Social Computing EraDocument16 pagesAssisted History Matching For Petroleum Reservoirs in The Social Computing ErashowravNo ratings yet
- Practical aspects of optimized ERT survey designDocument13 pagesPractical aspects of optimized ERT survey designPablo MarrNo ratings yet
- CASE STUDY 2Document5 pagesCASE STUDY 2vandanavenkat325No ratings yet
- Energies: A Holistic Review On Biomass Gasification Modified Equilibrium ModelsDocument31 pagesEnergies: A Holistic Review On Biomass Gasification Modified Equilibrium Modelsalaa haithamNo ratings yet
- Model Reduction High DimensionDocument20 pagesModel Reduction High DimensionLei TuNo ratings yet
- 1 s2.0 S0307904X11003520 Main PDFDocument12 pages1 s2.0 S0307904X11003520 Main PDFomarNo ratings yet
- PID Parameters Optimization Research For Hydro TurDocument17 pagesPID Parameters Optimization Research For Hydro TurLê Trung DũngNo ratings yet
- Assessment of WWTP Design and Upgrade Options: Balancing Costs and Risks of Standards' ExceedanceDocument8 pagesAssessment of WWTP Design and Upgrade Options: Balancing Costs and Risks of Standards' ExceedanceshamoojeeNo ratings yet
- Franschescini e Macchieto 2007Document13 pagesFranschescini e Macchieto 2007André Luís AlbertonNo ratings yet
- Entropy: Increasing The Discriminatory Power of DEA Using Shannon's EntropyDocument15 pagesEntropy: Increasing The Discriminatory Power of DEA Using Shannon's EntropyEdNo ratings yet
- SPE 164824 An Adaptive Evolutionary Algorithm For History-MatchingDocument13 pagesSPE 164824 An Adaptive Evolutionary Algorithm For History-MatchingAditya FauzanNo ratings yet
- Catalysts: Process Simulation For The Design and Scale Up of Heterogeneous Catalytic Process: Kinetic Modelling IssuesDocument33 pagesCatalysts: Process Simulation For The Design and Scale Up of Heterogeneous Catalytic Process: Kinetic Modelling Issuesjesus de jesusNo ratings yet
- Strategy Gas TransmDocument15 pagesStrategy Gas TransmPGPNo ratings yet
- The Optimal Design of Pressure Swing Adsorption SystemsDocument27 pagesThe Optimal Design of Pressure Swing Adsorption SystemsEljon OrillosaNo ratings yet
- The Optimal Design of Pressure Swing Adsorption SystemsDocument27 pagesThe Optimal Design of Pressure Swing Adsorption SystemsBich Lien PhamNo ratings yet
- Modelling of High-Pressure Dense Diesel Sprays With Adaptive Local Grid RefinementDocument22 pagesModelling of High-Pressure Dense Diesel Sprays With Adaptive Local Grid Refinementdr_s_m_afzali8662No ratings yet
- Deterministic Global Superstructure-Based Optimization of An Organic Rankine CycleDocument11 pagesDeterministic Global Superstructure-Based Optimization of An Organic Rankine Cyclenejmiddin boughattasNo ratings yet
- Invited Paper: A A B ADocument12 pagesInvited Paper: A A B AherlinafitrianingsihNo ratings yet
- 2009 Murray Smith DSCDocument143 pages2009 Murray Smith DSCminhtrieudoddtNo ratings yet
- Greyling Et Al. - 2022 - An Energy Graph Eigendecomposition Approach To FauDocument12 pagesGreyling Et Al. - 2022 - An Energy Graph Eigendecomposition Approach To FaujacobiekarlscribdNo ratings yet
- A Novel Approach To Assist History Matching Using Artificial IntelligenceDocument8 pagesA Novel Approach To Assist History Matching Using Artificial IntelligenceoksanaNo ratings yet
- Identification of Catalytic Converter Kinetic Model Using A Genetic Algorithm ApproachDocument35 pagesIdentification of Catalytic Converter Kinetic Model Using A Genetic Algorithm ApproachKoteswara RaoNo ratings yet
- Waterflooding Optimization For ImprovedDocument169 pagesWaterflooding Optimization For ImprovedHECTOR FLORESNo ratings yet
- Estimation of Multiple Petrophysical Parameters For Hydrocarbon Reservoirs With The Ensemble-Based TechniqueDocument17 pagesEstimation of Multiple Petrophysical Parameters For Hydrocarbon Reservoirs With The Ensemble-Based Techniquegerardo_gonza8118No ratings yet
- Topic7 ContactStressesAndDeformationsDocument15 pagesTopic7 ContactStressesAndDeformationsnikhil tiwariNo ratings yet
- A Strategic Planning... IRAN e USA - Kabirian e Hemmati PDFDocument15 pagesA Strategic Planning... IRAN e USA - Kabirian e Hemmati PDFmarcianunesmcgnsNo ratings yet
- GGGGG KKKDocument32 pagesGGGGG KKKaliNo ratings yet
- trailing armDocument21 pagestrailing armCarla AnflorNo ratings yet
- Results and Conclusions: 9.1 Summary of The ResultsDocument8 pagesResults and Conclusions: 9.1 Summary of The ResultsNova MejisienNo ratings yet
- 07 A Toolkit For The Development and Application of Parsimonious Hydrological ModelsDocument34 pages07 A Toolkit For The Development and Application of Parsimonious Hydrological ModelsGaBy CondorNo ratings yet
- Equifinality, Data Assimilation, and Uncertainty Estimation in Mechanistic Modelling of Complex Environmental Systems Using The GLUE MethodologyDocument19 pagesEquifinality, Data Assimilation, and Uncertainty Estimation in Mechanistic Modelling of Complex Environmental Systems Using The GLUE MethodologyJuan Felipe Zambrano BustilloNo ratings yet
- Nutron Transport EquationDocument41 pagesNutron Transport Equationmuti_khan20006003No ratings yet
- Finite Element Model For Modal Analysis of Engine-Transmission Unit: Numerical and Experimental..Document13 pagesFinite Element Model For Modal Analysis of Engine-Transmission Unit: Numerical and Experimental..Jai SharmaNo ratings yet
- 24 Ratnayake Melaaen DattaDocument6 pages24 Ratnayake Melaaen DattaSen VanNo ratings yet
- A New Concept for Tuning Design Weights in Survey Sampling: Jackknifing in Theory and PracticeFrom EverandA New Concept for Tuning Design Weights in Survey Sampling: Jackknifing in Theory and PracticeNo ratings yet
- 1 s2.0 S1364815221002772 MainDocument14 pages1 s2.0 S1364815221002772 MainSecretSanta HYDR 2021No ratings yet
- Global Optimization of Building Energy ModelsDocument19 pagesGlobal Optimization of Building Energy ModelsBv BcNo ratings yet
- A Framework For Portfolio Management of Renewable Hybrid Energy SourcesDocument8 pagesA Framework For Portfolio Management of Renewable Hybrid Energy Sourcesardavanli538No ratings yet
- Computers and Chemical Engineering: J. Steimel, S. EngellDocument18 pagesComputers and Chemical Engineering: J. Steimel, S. EngellAbubakr KhanNo ratings yet
- Analysis of Heat Transfer, Friction Factor and Exergy Loss in Plate Heat Exchanger Using FluentDocument8 pagesAnalysis of Heat Transfer, Friction Factor and Exergy Loss in Plate Heat Exchanger Using FluentFadi YasinNo ratings yet
- Cost minimization of paper mill washing unit using artificial bee colonyDocument12 pagesCost minimization of paper mill washing unit using artificial bee colonyapis21No ratings yet
- Konz 2016Document38 pagesKonz 2016Auro SinghNo ratings yet
- Towards Realizable, Low-Cost Broadcast Systems For Dynamic EnvironmentsDocument10 pagesTowards Realizable, Low-Cost Broadcast Systems For Dynamic EnvironmentsramyaarumugamNo ratings yet
- Vidmar 2011Document4 pagesVidmar 2011BubNo ratings yet
- Tunability: Importance of Hyperparameters of Machine Learning AlgorithmsDocument32 pagesTunability: Importance of Hyperparameters of Machine Learning AlgorithmsinoddyNo ratings yet
- A Method Integrating Taguchi, RSM and MOPSO To CNC Machining Parameters Optimization For Energy SavingDocument13 pagesA Method Integrating Taguchi, RSM and MOPSO To CNC Machining Parameters Optimization For Energy SavingoktovaNo ratings yet
- Gas Turbine Transient PerformanceDocument14 pagesGas Turbine Transient PerformanceAndrew MicallefNo ratings yet
- Formulation and Application of SMUDocument31 pagesFormulation and Application of SMUAndrea GennaroNo ratings yet
- Gunay and HinisliogluDocument10 pagesGunay and HinisliogluZriNo ratings yet
- Single-Step Deep Reinforcement Learning For Two-And Three-Dimensional Optimal Shape DesignDocument22 pagesSingle-Step Deep Reinforcement Learning For Two-And Three-Dimensional Optimal Shape DesignbuntarNo ratings yet
- Archive of SID: Novel Fusion Approaches For The Dissolved Gas Analysis of Insulating OilDocument12 pagesArchive of SID: Novel Fusion Approaches For The Dissolved Gas Analysis of Insulating OilelshamikNo ratings yet
- Inverse Analysis of Deep Excavation Using Differential Evolution AlgorithmDocument20 pagesInverse Analysis of Deep Excavation Using Differential Evolution AlgorithmNorick CahyaNo ratings yet
- Review of Related LiteratureDocument3 pagesReview of Related LiteratureSpencer DariusNo ratings yet
- Willans Line ArticleDocument8 pagesWillans Line Articlealiscribd46100% (1)
- 1 s2.0 S0375650516000092 MainDocument12 pages1 s2.0 S0375650516000092 MainHebaNo ratings yet
- Javid Rad 2017Document82 pagesJavid Rad 2017Chakib BenmhamedNo ratings yet
- Spatial Analysis Using Big Data: Methods and Urban ApplicationsFrom EverandSpatial Analysis Using Big Data: Methods and Urban ApplicationsYoshiki YamagataRating: 5 out of 5 stars5/5 (1)
- Modern Anti-windup Synthesis: Control Augmentation for Actuator SaturationFrom EverandModern Anti-windup Synthesis: Control Augmentation for Actuator SaturationRating: 5 out of 5 stars5/5 (1)
- 29 April 2015: PTD - Since 2007Document19 pages29 April 2015: PTD - Since 2007Khairatun NisaNo ratings yet
- Ohsas18001 160122133208 PDFDocument16 pagesOhsas18001 160122133208 PDFKhairatun NisaNo ratings yet
- Biofuels aspenONE Engineering PDFDocument4 pagesBiofuels aspenONE Engineering PDFKhairatun NisaNo ratings yet
- POME TreatmentDocument12 pagesPOME Treatmentaxgani100% (1)
- Dialnet HazardAnalysisAndCriticalControlPointsHACCPInPalmO 4277729Document4 pagesDialnet HazardAnalysisAndCriticalControlPointsHACCPInPalmO 4277729Sabar HutahaeanNo ratings yet
- POME TreatmentDocument12 pagesPOME Treatmentaxgani100% (1)
- System FactorDocument3 pagesSystem FactorKhairatun NisaNo ratings yet
- Fulltext Ajpt v3 Id1068Document7 pagesFulltext Ajpt v3 Id1068Khairatun NisaNo ratings yet
- Safety and Health - Fact Sheet - Oil Palm - 2004 03 PDFDocument2 pagesSafety and Health - Fact Sheet - Oil Palm - 2004 03 PDFKhairatun NisaNo ratings yet
- 304morais PDFDocument6 pages304morais PDFKhairatun NisaNo ratings yet
- 4383 9554 1 SM PDFDocument6 pages4383 9554 1 SM PDFKhairatun NisaNo ratings yet
- Brochure PDFDocument10 pagesBrochure PDFKhairatun NisaNo ratings yet
- POME TreatmentDocument12 pagesPOME Treatmentaxgani100% (1)
- Unusual Solvatochromic Absorbance Probe Behaviour Within Mixtures PDFDocument10 pagesUnusual Solvatochromic Absorbance Probe Behaviour Within Mixtures PDFKhairatun NisaNo ratings yet
- 02 Dasar2 Perancangan Chp1 FoglerDocument14 pages02 Dasar2 Perancangan Chp1 FoglerAdun DudunNo ratings yet
- Call For Papers and Posters: Connect2SeaDocument3 pagesCall For Papers and Posters: Connect2SeaKhairatun NisaNo ratings yet
- Aspen DMCplus Training-CAPC PDFDocument11 pagesAspen DMCplus Training-CAPC PDFKhairatun Nisa0% (1)
- Lec 24Document35 pagesLec 24Khairatun NisaNo ratings yet
- ARIN 011 LNG18 Registration Brochure 8PP - 23 - LAYOUT - AC13 PDFDocument5 pagesARIN 011 LNG18 Registration Brochure 8PP - 23 - LAYOUT - AC13 PDFKhairatun NisaNo ratings yet
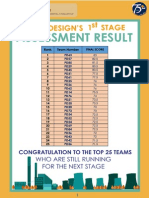
- IChEC 2016 Plant Design 1st Stage Result PDFDocument3 pagesIChEC 2016 Plant Design 1st Stage Result PDFKhairatun NisaNo ratings yet
- Model Development for Catalytic Converter OptimizationDocument10 pagesModel Development for Catalytic Converter OptimizationKhairatun NisaNo ratings yet
- Kesetimbangan Uap-Cair Dan Cair-Cair Sistem Etanol (1) + Air (2) + Ionic Liquids (3) Dalam Pemurnian BioetanolDocument11 pagesKesetimbangan Uap-Cair Dan Cair-Cair Sistem Etanol (1) + Air (2) + Ionic Liquids (3) Dalam Pemurnian BioetanoldhiyaulNo ratings yet
- Detailed Surface Reaction of TWC PDFDocument14 pagesDetailed Surface Reaction of TWC PDFKhairatun NisaNo ratings yet
- SubseaUK News NOV14 ISSUU 2 PDFDocument32 pagesSubseaUK News NOV14 ISSUU 2 PDFKhairatun NisaNo ratings yet
- Property 20package 20descriptionsDocument23 pagesProperty 20package 20descriptionsGonnartNo ratings yet
- Catalytic Converter (Theory, Operation, and Modelling) PDFDocument24 pagesCatalytic Converter (Theory, Operation, and Modelling) PDFKhairatun NisaNo ratings yet
- Matrix OperationsDocument21 pagesMatrix Operationspoojaguptaindia1No ratings yet
- Block DiagramDocument12 pagesBlock DiagramKhairatun NisaNo ratings yet
- Chapter 10 HandoutDocument18 pagesChapter 10 HandoutChad FerninNo ratings yet
- Jolly Phonics Teaching Reading and WritingDocument6 pagesJolly Phonics Teaching Reading and Writingmarcela33j5086100% (1)
- 6 - English-How I Taught My Grandmother To Read and Grammar-Notes&VLDocument11 pages6 - English-How I Taught My Grandmother To Read and Grammar-Notes&VLManav100% (2)
- Chapter 9 MafinDocument36 pagesChapter 9 MafinReymilyn SanchezNo ratings yet
- Functional Appliances 2018Document45 pagesFunctional Appliances 2018tonhanrhmNo ratings yet
- Connectors/Conjunctions: Intermediate English GrammarDocument9 pagesConnectors/Conjunctions: Intermediate English GrammarExe Nif EnsteinNo ratings yet
- Summary Basis For Regulatory Action TemplateDocument23 pagesSummary Basis For Regulatory Action TemplateAviseka AcharyaNo ratings yet
- Culture of BMWDocument6 pagesCulture of BMWhk246100% (1)
- Henderson - Historical Documents of The Middle AgesDocument536 pagesHenderson - Historical Documents of The Middle AgesVlad VieriuNo ratings yet
- Twin-Field Quantum Key Distribution Without Optical Frequency DisseminationDocument8 pagesTwin-Field Quantum Key Distribution Without Optical Frequency DisseminationHareesh PanakkalNo ratings yet
- Modelling of Induction Motor PDFDocument42 pagesModelling of Induction Motor PDFsureshNo ratings yet
- Science of Happiness Paper 1Document5 pagesScience of Happiness Paper 1Palak PatelNo ratings yet
- Dreams and Destiny Adventure HookDocument5 pagesDreams and Destiny Adventure HookgravediggeresNo ratings yet
- Comparative Ethnographies: State and Its MarginsDocument31 pagesComparative Ethnographies: State and Its MarginsJuan ManuelNo ratings yet
- The Pantheon of Greek Gods and GoddessesDocument2 pagesThe Pantheon of Greek Gods and Goddessesapi-226457456No ratings yet
- Chapter 1. Introduction To TCPIP NetworkingDocument15 pagesChapter 1. Introduction To TCPIP NetworkingPoojitha NagarajaNo ratings yet
- Contemporary Philippine Arts From The RegionsDocument29 pagesContemporary Philippine Arts From The RegionsDina Ilagan50% (2)
- VDA ChinaDocument72 pagesVDA Chinatuananh1010No ratings yet
- Javier Couso, Alexandra Huneeus, Rachel Sieder Cultures of Legality Judicialization and Political Activism in Latin America Cambridge Studies in Law and SocietyDocument290 pagesJavier Couso, Alexandra Huneeus, Rachel Sieder Cultures of Legality Judicialization and Political Activism in Latin America Cambridge Studies in Law and SocietyLívia de SouzaNo ratings yet
- ET's and Aliens: Problems of Exopolitics - Dec 2009Document8 pagesET's and Aliens: Problems of Exopolitics - Dec 2009Alex KochkinNo ratings yet
- Mr. Honey's Large Business DictionaryEnglish-German by Honig, WinfriedDocument538 pagesMr. Honey's Large Business DictionaryEnglish-German by Honig, WinfriedGutenberg.orgNo ratings yet
- Literature ReviewDocument4 pagesLiterature Reviewapi-549241187No ratings yet
- PallavaDocument24 pagesPallavaAzeez FathulNo ratings yet
- New Text DocumentDocument8 pagesNew Text DocumentDhaniNo ratings yet
- TOS and CID FORM-TLE 8 ANIMATIONDocument80 pagesTOS and CID FORM-TLE 8 ANIMATIONAriel AntaboNo ratings yet
- We Don't Eat Our: ClassmatesDocument35 pagesWe Don't Eat Our: ClassmatesChelle Denise Gumban Huyaban85% (20)
- Banking & Finance Awareness 2016 (Jan-Nov) by AffairsCloudDocument167 pagesBanking & Finance Awareness 2016 (Jan-Nov) by AffairsCloudkaushikyNo ratings yet
- St. Louis ChemicalDocument8 pagesSt. Louis ChemicalNaomi Alberg-BlijdNo ratings yet
- Operations Management 2Document15 pagesOperations Management 2karunakar vNo ratings yet
- Verbs Followed by GerundsDocument10 pagesVerbs Followed by GerundsJhan MartinezNo ratings yet