You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- T-Clock Advanced Clock Configuration Options: Date Options Day of WeekDocument6 pagesT-Clock Advanced Clock Configuration Options: Date Options Day of WeekJohnny WatermelonseedNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- GoodnessDocument1 pageGoodnessJohnny WatermelonseedNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- JoDocument2 pagesJoJohnny WatermelonseedNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Hinge Pivot Assembly: Check and Guide Channel AssemblyDocument1 pageHinge Pivot Assembly: Check and Guide Channel AssemblyJohnny WatermelonseedNo ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Changelog For Patch (30 August 2016)Document1 pageChangelog For Patch (30 August 2016)Johnny WatermelonseedNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Meteor Shower: by Steve MartinDocument8 pagesMeteor Shower: by Steve MartinJohnny Watermelonseed50% (2)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Racial Bias in Judgments of Physical Size and Formidability: From Size To ThreatDocument23 pagesRacial Bias in Judgments of Physical Size and Formidability: From Size To ThreatDamon K JonesNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- NicebrahDocument4 pagesNicebrahJohnny WatermelonseedNo ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Order of InstallDocument1 pageOrder of InstallJohnny WatermelonseedNo ratings yet
- Kangaroo 230 Release NotesDocument9 pagesKangaroo 230 Release NotesmolaNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- q2 Spec Power Stainless Steel Narrow Stile Concealed Shaft Stanley PowernowDocument8 pagesq2 Spec Power Stainless Steel Narrow Stile Concealed Shaft Stanley PowernowJohnny WatermelonseedNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- FastRawViewer ManualDocument186 pagesFastRawViewer ManualJohnny WatermelonseedNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- EulaDocument8 pagesEulaJohnny WatermelonseedNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- HolymolyDocument8 pagesHolymolyJohnny WatermelonseedNo ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
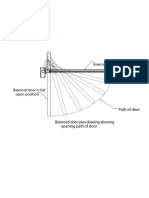
- Ellisonbrobalanceddoorplan Balanced Door PlanDocument1 pageEllisonbrobalanceddoorplan Balanced Door PlanJohnny WatermelonseedNo ratings yet
- Thesis Summer 2011 Rock Star Arena Elena Manferdini Me, Myself, and IDocument10 pagesThesis Summer 2011 Rock Star Arena Elena Manferdini Me, Myself, and IJohnny WatermelonseedNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Effects of Humidity On Material & ProcessesDocument7 pagesEffects of Humidity On Material & ProcessesSenthil_K100% (1)
- Standard EULADocument4 pagesStandard EULAFrancisco Javier CantorNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- UTA Issue008Document158 pagesUTA Issue008Johnny WatermelonseedNo ratings yet
- Penn IP Briefing BookdfdfDocument202 pagesPenn IP Briefing BookdfdfJohnny WatermelonseedNo ratings yet
- Hair LondonDocument2 pagesHair LondonJohnny WatermelonseedNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Adventures of Huckleberry Finn by Mark TwainDocument289 pagesThe Adventures of Huckleberry Finn by Mark TwainBooks100% (5)
- WhoobydoobuDocument30 pagesWhoobydoobuJohnny WatermelonseedNo ratings yet
- Institutional Other Facility Application PDFDocument22 pagesInstitutional Other Facility Application PDFJohnny WatermelonseedNo ratings yet
- The Senior Artist Colony: Meta Housing Corporation Unit 1ADocument1 pageThe Senior Artist Colony: Meta Housing Corporation Unit 1AJohnny WatermelonseedNo ratings yet
- University Campus Sets High Standard For Exterior Wall ConstructionDocument1 pageUniversity Campus Sets High Standard For Exterior Wall ConstructionJohnny WatermelonseedNo ratings yet
- 2DoManual PDFDocument95 pages2DoManual PDFAraceli GuerreroNo ratings yet
- Image CaptioningDocument14 pagesImage CaptioningSaginala SharonNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Cycle of LiberationDocument11 pagesCycle of Liberationapi-280182260100% (1)
- ALS English ModuleDocument19 pagesALS English ModuleJizelle SinfuegoNo ratings yet
- HR Interview QuestionsDocument22 pagesHR Interview QuestionsShamshu ShaikNo ratings yet
- SVEC - 10 Regulations (EIE) PDFDocument227 pagesSVEC - 10 Regulations (EIE) PDFJAYA CHANDRA AKULANo ratings yet
- Annotated BibliographyDocument4 pagesAnnotated Bibliographyphamviv100% (1)
- Attention and ComprehensionDocument22 pagesAttention and ComprehensionAhmadd FadlyNo ratings yet
- Lesson Plan Arts 8 I. Objectives: at The End of The Lesson The Students Are Expected ToDocument3 pagesLesson Plan Arts 8 I. Objectives: at The End of The Lesson The Students Are Expected ToBeaMaeAntoniNo ratings yet
- Ecom 3 PART2 CHAP 4Document41 pagesEcom 3 PART2 CHAP 4Ulfat Raza KhanNo ratings yet
- 1.yontef, G. (1993) .Awareness, Dialogueandprocess - Essaysongestalttherapy - NY - TheGestaltJournal Press. Chapter6 - Gestalt Therapy - Clinical Phenomenology pp181-201.Document12 pages1.yontef, G. (1993) .Awareness, Dialogueandprocess - Essaysongestalttherapy - NY - TheGestaltJournal Press. Chapter6 - Gestalt Therapy - Clinical Phenomenology pp181-201.nikos kasiktsisNo ratings yet
- Employee Testing, Interviewing and Selection: Chapter 6-1Document41 pagesEmployee Testing, Interviewing and Selection: Chapter 6-1Ss ArNo ratings yet
- HCI Introduction and Psychology of Usable Things: Usman AhmadDocument14 pagesHCI Introduction and Psychology of Usable Things: Usman Ahmadblack smith100% (1)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- 2009-10-07 015349 Five StepDocument1 page2009-10-07 015349 Five StepAndrew PiwonskiNo ratings yet
- My Resume - Snehal Bhatkar - PDF UpdatedDocument4 pagesMy Resume - Snehal Bhatkar - PDF UpdatedSnehal BhatkarNo ratings yet
- Facilitate Learning Session: Prepared By: Wilmer J. DirectoDocument31 pagesFacilitate Learning Session: Prepared By: Wilmer J. DirectoJohn Wilner DirectoNo ratings yet
- Worksheet Q1 Week 3 Developing Stages in Middle and Late AdolescenceDocument3 pagesWorksheet Q1 Week 3 Developing Stages in Middle and Late AdolescenceKent PesidasNo ratings yet
- Qlik Nprinting Training Brochure Qlik Nprinting Training BrochureDocument2 pagesQlik Nprinting Training Brochure Qlik Nprinting Training BrochureCarlo RossiNo ratings yet
- Cabadbaran City Sanggunian ResolutionDocument2 pagesCabadbaran City Sanggunian ResolutionAlbert CongNo ratings yet
- CTU Public Administration Thoughts and InstitutionDocument3 pagesCTU Public Administration Thoughts and InstitutionCatherine Adlawan-SanchezNo ratings yet
- The Study Skills of First Year Education Students and Their Academic Performance Maria Nancy Quinco-Cadosales, PHDDocument13 pagesThe Study Skills of First Year Education Students and Their Academic Performance Maria Nancy Quinco-Cadosales, PHDRey AlegriaNo ratings yet
- Arusha Technical CollegeDocument4 pagesArusha Technical CollegeNamwangala Rashid NatinduNo ratings yet
- Anterior Knee PainDocument11 pagesAnterior Knee PainViswanathNo ratings yet
- Cambridge International AS & A Level: Design & Technology 9705/12Document12 pagesCambridge International AS & A Level: Design & Technology 9705/12Maya PopoNo ratings yet
- Adina Lundquist ResumeDocument2 pagesAdina Lundquist Resumeapi-252114142No ratings yet
- CCW331 BA IAT 1 Set 1 & Set 2 QuestionsDocument19 pagesCCW331 BA IAT 1 Set 1 & Set 2 Questionsmnishanth2184No ratings yet
- ArticleDocument9 pagesArticleThushara TNo ratings yet
- Rashid Fundamental Positions of The Arms and FeetDocument9 pagesRashid Fundamental Positions of The Arms and FeetMARIA LALAINE ACAINNo ratings yet
- Lessonn Plan Accounting Class 11 Week 2Document4 pagesLessonn Plan Accounting Class 11 Week 2SyedMaazAliNo ratings yet
- Speech About LoveDocument2 pagesSpeech About LoveGelli TabiraraNo ratings yet
- Peer Assesment 1 Sheet - RagDocument3 pagesPeer Assesment 1 Sheet - Ragapi-569743488No ratings yet
- Fusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureFrom EverandFusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureNo ratings yet
- Grokking Algorithms: An illustrated guide for programmers and other curious peopleFrom EverandGrokking Algorithms: An illustrated guide for programmers and other curious peopleRating: 4 out of 5 stars4/5 (16)
- Dark Data: Why What You Don’t Know MattersFrom EverandDark Data: Why What You Don’t Know MattersRating: 4.5 out of 5 stars4.5/5 (3)
- Blockchain Basics: A Non-Technical Introduction in 25 StepsFrom EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsRating: 4.5 out of 5 stars4.5/5 (24)