You might also like
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Note Jun 1, 2022 (2) 2Document7 pagesNote Jun 1, 2022 (2) 2shotorbariNo ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Tutorial Binary Search TreeDocument38 pagesTutorial Binary Search TreeShilpi VirmaniNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- Note Dec 24, 2022Document1 pageNote Dec 24, 2022shotorbariNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Note Jun 1, 2022 (2) 2Document7 pagesNote Jun 1, 2022 (2) 2shotorbariNo ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Is This Why The US Is Delaying Interest Rate RisesDocument5 pagesIs This Why The US Is Delaying Interest Rate RisesshotorbariNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Words - Part 1Document20 pagesWords - Part 1shotorbariNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Adversarial Example Games: Equal Contribution, Order Chosen Via Randomization. Canada CIFAR AI ChairDocument22 pagesAdversarial Example Games: Equal Contribution, Order Chosen Via Randomization. Canada CIFAR AI ChairshotorbariNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Note Jun 1, 2022 (2) 2Document7 pagesNote Jun 1, 2022 (2) 2shotorbariNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Graph Search and Its Applications: A e L (A) 1 L (E) +Document1 pageGraph Search and Its Applications: A e L (A) 1 L (E) +shotorbariNo ratings yet
- 626 Owners ManualDocument15 pages626 Owners ManualshotorbariNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- To-Do List Tasks MemosDocument1 pageTo-Do List Tasks MemosshotorbariNo ratings yet
- 35 Years of The Global Economy in One VideoDocument6 pages35 Years of The Global Economy in One VideoshotorbariNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- 0 - Daily Template PDFDocument1 page0 - Daily Template PDFshotorbariNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- 0 - Weekly Template PDFDocument1 page0 - Weekly Template PDFshotorbariNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- Using Game Theory To Allocate Transmission CostsDocument6 pagesUsing Game Theory To Allocate Transmission CostsshotorbariNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- General Equilibrium Theory Lecture Notes, Bisin PDFDocument76 pagesGeneral Equilibrium Theory Lecture Notes, Bisin PDFshotorbariNo ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Will China Change The World's Financial InstitutionsDocument5 pagesWill China Change The World's Financial InstitutionsshotorbariNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- Stack QueueDocument49 pagesStack QueueBethanyethanNo ratings yet
- How Would You Fare at The Global Negotiating Table - Agenda - The World Economic ForumDocument4 pagesHow Would You Fare at The Global Negotiating Table - Agenda - The World Economic ForumshotorbariNo ratings yet
- Why The West's View of The Saudis Is Shifting - FTDocument4 pagesWhy The West's View of The Saudis Is Shifting - FTshotorbariNo ratings yet
- How Religious Will The World Be in 2050Document6 pagesHow Religious Will The World Be in 2050shotorbariNo ratings yet
- How Much Does Each State Contribute To The US EconomyDocument4 pagesHow Much Does Each State Contribute To The US EconomyshotorbariNo ratings yet
- Shaken and StirredDocument4 pagesShaken and StirredshotorbariNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Could Energy Be 100% Green in 2030 - Agenda - The World Economic ForumDocument5 pagesCould Energy Be 100% Green in 2030 - Agenda - The World Economic ForumshotorbariNo ratings yet
- 5 Ways The World Will Look Dramatically Different in 2100 - Agenda - The World Economic ForumDocument6 pages5 Ways The World Will Look Dramatically Different in 2100 - Agenda - The World Economic ForumshotorbariNo ratings yet
- Brazil's Economy Shrinks by Record 4.5% - FTDocument4 pagesBrazil's Economy Shrinks by Record 4.5% - FTshotorbariNo ratings yet
- 5 Trends For The Future of Economic Growth - Agenda - The World Economic ForumDocument5 pages5 Trends For The Future of Economic Growth - Agenda - The World Economic ForumshotorbariNo ratings yet
- Final Project Report Transient Stability of Power System (Programming Massively Parallel Graphics Multiprocessors Using CUDA)Document5 pagesFinal Project Report Transient Stability of Power System (Programming Massively Parallel Graphics Multiprocessors Using CUDA)shotorbariNo ratings yet
- Using Emtp RVDocument263 pagesUsing Emtp RVshotorbari100% (1)
- Simplex Eg1Document24 pagesSimplex Eg1Ville4everNo ratings yet
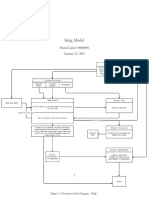
- Ising ModelDocument5 pagesIsing Modeldecerto252No ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Ezy Math Tutoring - Year 9 AnswersDocument144 pagesEzy Math Tutoring - Year 9 AnswersVincents Genesius EvansNo ratings yet
- Math II Tutorial 1Document2 pagesMath II Tutorial 1devang_siNo ratings yet
- IEEE Paper For Image ProcessingDocument32 pagesIEEE Paper For Image Processingsaravanan_dijucsNo ratings yet
- Properties of CompoundsDocument15 pagesProperties of CompoundsPrasad YarraNo ratings yet
- Dual Nature of LightDocument15 pagesDual Nature of LightUriahs Victor75% (4)
- Newtons Law of MotionDocument14 pagesNewtons Law of MotionJohn Irvin M. AbatayNo ratings yet
- 06 Slewing PDFDocument14 pages06 Slewing PDFJuan Alberto Giglio FernándezNo ratings yet
- Meclizine HCLDocument10 pagesMeclizine HCLChEng_No ratings yet
- Numerical Solution of Seepage Problem of Groundwater FlowDocument5 pagesNumerical Solution of Seepage Problem of Groundwater FlowIOSRjournalNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Lucia 1995 Rock-FabricPetrophysical Classification of Carbonate Pore SpaceDocument26 pagesLucia 1995 Rock-FabricPetrophysical Classification of Carbonate Pore SpaceMarcos Antonio Romero Arteaga100% (1)
- Influence of Dirt Accumulation On Performance of PV Panels: SciencedirectDocument7 pagesInfluence of Dirt Accumulation On Performance of PV Panels: SciencedirectEsra AbdulhaleemNo ratings yet
- Simulation of Soil Compaction With Vibratory Rollers PDFDocument13 pagesSimulation of Soil Compaction With Vibratory Rollers PDFSandeep KumarNo ratings yet
- ASTM TablesDocument185 pagesASTM Tableslahiru198367% (3)
- Direct Shear Test ResultsDocument19 pagesDirect Shear Test ResultsAh Gus100% (9)
- CASD 2017. Robust H-Infinity Backstepping Control Design of A Wheeled Inverted Pendulum SystemDocument5 pagesCASD 2017. Robust H-Infinity Backstepping Control Design of A Wheeled Inverted Pendulum SystemNam Hoang ThanhNo ratings yet
- OSHA Confined Space Standards and HazardsDocument93 pagesOSHA Confined Space Standards and HazardsPrimelift Safety Resources LimitedNo ratings yet
- Stepper Motor Driven Solar Tracker SystemDocument4 pagesStepper Motor Driven Solar Tracker SystemFAHMY RINANDA SAPUTRI (066629)No ratings yet
- Computer Graphics and AnimationDocument2 pagesComputer Graphics and AnimationManoj PrasadNo ratings yet
- Lahore University of Management Sciences: EE539 - Radar SystemsDocument3 pagesLahore University of Management Sciences: EE539 - Radar SystemsDr-Raghad Al-FahamNo ratings yet
- Math at Grade 4Document9 pagesMath at Grade 4api-239942675No ratings yet
- Thermo Scientific Pierce Protein Assay Technical HandbookDocument44 pagesThermo Scientific Pierce Protein Assay Technical HandbookAnwar_Madkhali_9172No ratings yet
- Gujarat Technological University: W.E.F. AY 2018-19Document3 pagesGujarat Technological University: W.E.F. AY 2018-19SURAJ NAKUMNo ratings yet
- PMM WordDocument3 pagesPMM WordShrey R DhanawadkarNo ratings yet
- (Architecture Ebook) Alvar Aalto, Alvar Aalto and The Bio-ArchitectureDocument5 pages(Architecture Ebook) Alvar Aalto, Alvar Aalto and The Bio-Architecturepooh86poohNo ratings yet
- Load CalculationsDocument5 pagesLoad Calculationsarif_rubinNo ratings yet
- Experiment #2: Continuous-Time Signal Representation I. ObjectivesDocument14 pagesExperiment #2: Continuous-Time Signal Representation I. ObjectivesMarvin AtienzaNo ratings yet
- CE 3310 Assignment 2Document1 pageCE 3310 Assignment 2SSNo ratings yet
- A AjouterDocument3 pagesA Ajouter00JoNo ratings yet
- Working of Steam Turbines and Its AuxillariesDocument48 pagesWorking of Steam Turbines and Its AuxillariesbalajigandhirajanNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormFrom EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormRating: 5 out of 5 stars5/5 (5)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsFrom EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsRating: 5 out of 5 stars5/5 (2)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeFrom EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeRating: 4 out of 5 stars4/5 (2)