You might also like
- Disk Performance OptimizationDocument56 pagesDisk Performance OptimizationSenthildevi K.ANo ratings yet
- Topics Covered: Physical Disk Organization Example Disk Scheduling Algorithms Research WorkDocument21 pagesTopics Covered: Physical Disk Organization Example Disk Scheduling Algorithms Research WorkMasooma BashirNo ratings yet
- What Is Round Robin SchedulingDocument5 pagesWhat Is Round Robin Schedulingtridibearth100% (3)
- Round RobinDocument15 pagesRound RobinSohaib AijazNo ratings yet
- Operating SystemDocument30 pagesOperating SystemMichelle AndrewNo ratings yet
- 8.queuing TheoryDocument93 pages8.queuing Theoryঅভিজিৎ বিশ্বাসNo ratings yet
- Practical Lab Session: SQL-server ManualDocument49 pagesPractical Lab Session: SQL-server ManualAbel Mulatu100% (1)
- Introduction To Data Management: Chapter 1, Pratt & AdamskiDocument25 pagesIntroduction To Data Management: Chapter 1, Pratt & Adamskiahmad100% (1)
- Blocking and BufferingDocument5 pagesBlocking and BufferingClarysse GonzalesNo ratings yet
- Chapter-2-Data Structures and Algorithms AnalysisDocument44 pagesChapter-2-Data Structures and Algorithms Analysisbini100% (1)
- Lec 1 - Number Systems and Digital LogicDocument38 pagesLec 1 - Number Systems and Digital LogicSAVILASH A/L RAVINDRANNo ratings yet
- Oracle Final Exam Semester 1Document22 pagesOracle Final Exam Semester 1Cornelia PîrvulescuNo ratings yet
- Ff84602 - CHP - ISM Book Exc SolutionsDocument4 pagesFf84602 - CHP - ISM Book Exc SolutionsRohan KhuranaNo ratings yet
- Data Transfer and Manipulation PDFDocument2 pagesData Transfer and Manipulation PDFVishant ChaudharyNo ratings yet
- Computer Coding SystemDocument8 pagesComputer Coding SystemidivyaankNo ratings yet
- OS Lab ManualDocument71 pagesOS Lab ManualveditttttaNo ratings yet
- 2017 AnswerDocument4 pages2017 AnswerAbraham AlemsegedNo ratings yet
- Data StructureDocument100 pagesData StructureSanthoshNo ratings yet
- 04 - 05-AI-Knowledge and ReasoningDocument61 pages04 - 05-AI-Knowledge and ReasoningderbewNo ratings yet
- Online End Semester Examinations (HCI)Document5 pagesOnline End Semester Examinations (HCI)SyedHassanAhmedNo ratings yet
- Mid Term Exam SQLDocument17 pagesMid Term Exam SQLSebastian Ajesh100% (1)
- Compilers Versus InterpretersDocument11 pagesCompilers Versus InterpretersRohan Fernandes100% (1)
- Viva Question Paper Class 6Document2 pagesViva Question Paper Class 6Gfl• TaneeshTMNo ratings yet
- Network Custody SystemsDocument20 pagesNetwork Custody Systemsapi-3746880100% (1)
- 1.1 - Characteristics of The Distributed SystemsDocument14 pages1.1 - Characteristics of The Distributed SystemsMaryfer RamirezNo ratings yet
- Selected Topics in Computer Science CHDocument24 pagesSelected Topics in Computer Science CHMehari TemesgenNo ratings yet
- 434 HW 3 SolDocument5 pages434 HW 3 SolSweet AliaNo ratings yet
- LAB#05 Objective To Create An Arena Model Using Data Modules and Observe The Results of The Simulation Run Task #1Document8 pagesLAB#05 Objective To Create An Arena Model Using Data Modules and Observe The Results of The Simulation Run Task #1Aisha AnwarNo ratings yet
- 05 - Strategies For Query Processing (Ch18)Document50 pages05 - Strategies For Query Processing (Ch18)محمد فايز سمورNo ratings yet
- 715ECT04 Embedded Systems 2M & 16MDocument32 pages715ECT04 Embedded Systems 2M & 16Msumathi0% (1)
- Unit 1 PDFDocument100 pagesUnit 1 PDFSai KrishnaNo ratings yet
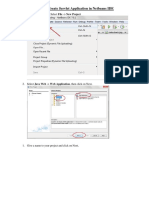
- Steps To Create Servlet Application in Netbeans IDEDocument7 pagesSteps To Create Servlet Application in Netbeans IDEMithila MetriNo ratings yet
- Assignment1 PDFDocument5 pagesAssignment1 PDFpristo sellerNo ratings yet
- Virtualization Enterprise Assignment 2Document2 pagesVirtualization Enterprise Assignment 2Rao Hammad ArshadNo ratings yet
- Simple Sorting and Searching Algorithms 2.1searching: PseudocodeDocument7 pagesSimple Sorting and Searching Algorithms 2.1searching: PseudocodebiniNo ratings yet
- Enterprise Data Integration For The Implementation of An E-Governance SystemDocument77 pagesEnterprise Data Integration For The Implementation of An E-Governance Systemajextope100% (1)
- Pascal NotesDocument50 pagesPascal NotesdnlkabaNo ratings yet
- LabVIEW PPT PresentationDocument27 pagesLabVIEW PPT PresentationRanadeep DeyNo ratings yet
- Non Regular LanguageDocument25 pagesNon Regular LanguageJibran ElahiNo ratings yet
- Microprocessor Lab MANUALDocument139 pagesMicroprocessor Lab MANUALhayumbe08No ratings yet
- Unit-3 PPT NotesDocument67 pagesUnit-3 PPT Notesshivam sharmaNo ratings yet
- Quiz #9 (CH 11) - Siyao GuanDocument7 pagesQuiz #9 (CH 11) - Siyao Guanbalwantsharma1993No ratings yet
- Unit 1 Number SystemsDocument30 pagesUnit 1 Number SystemsAnurag GoelNo ratings yet
- Distributed Systems Assignment 2Document3 pagesDistributed Systems Assignment 2Jěhøvāh Šhāĺøm100% (1)
- Creating A Registration Form Using PHPDocument11 pagesCreating A Registration Form Using PHPGorakhnath MethreNo ratings yet
- Subnetting Basics: Michael D. MannDocument28 pagesSubnetting Basics: Michael D. Mannjames_blankNo ratings yet
- Clearance Management System UpdatedDocument25 pagesClearance Management System UpdatedMilkiyas Mosisa100% (1)
- Chapter 4 Streams and File IODocument44 pagesChapter 4 Streams and File IOGalatom Yadeta100% (1)
- Assignment 3Document3 pagesAssignment 3Kibrom HaftuNo ratings yet
- Shift Register and Its TypesDocument22 pagesShift Register and Its TypeschoprahridyeshNo ratings yet
- Chapter 2 - Query Processing and OptimizationDocument28 pagesChapter 2 - Query Processing and OptimizationDinksraw100% (1)
- Data Transmission - Parallel Vs SerialDocument11 pagesData Transmission - Parallel Vs SerialGetaye Aysheshim100% (2)
- SSDT SQLSat Denver 2015 PDFDocument26 pagesSSDT SQLSat Denver 2015 PDFHajer AhmedNo ratings yet
- 03 Teacher's Guide TemplateDocument27 pages03 Teacher's Guide TemplatemeymunaNo ratings yet
- Microprocessor Question SolveDocument31 pagesMicroprocessor Question SolveAnik DasNo ratings yet
- Overview of Mass-Storage StructureDocument7 pagesOverview of Mass-Storage Structureزهراء كريم غيلانNo ratings yet
- Disk Scheduling AlgorithmsDocument21 pagesDisk Scheduling Algorithmsbca nandhaartsNo ratings yet
- Disk SchedulingDocument9 pagesDisk SchedulingIJASCSENo ratings yet
- Edi 113 Assignment 1Document13 pagesEdi 113 Assignment 1Gebreyohans tesfayNo ratings yet
- Oracle®Solaris ZFSAdministration GuideDocument332 pagesOracle®Solaris ZFSAdministration GuideParashar SinghNo ratings yet
- Unix: System Administration and SecurityDocument33 pagesUnix: System Administration and Securityanoop100% (2)
- S7 Product Notes PDFDocument34 pagesS7 Product Notes PDFHtoo Satt WaiNo ratings yet
- Docu56210 - XtremIO Host Configuration Guide PDFDocument188 pagesDocu56210 - XtremIO Host Configuration Guide PDFSNNo ratings yet
- Tuning ZFS On FreeBSDDocument29 pagesTuning ZFS On FreeBSDi8bitNo ratings yet
- Unit 5Document85 pagesUnit 5Vamsi KrishnaNo ratings yet
- Student Guide Advance Level Solaris 11 System AdministrationDocument306 pagesStudent Guide Advance Level Solaris 11 System AdministrationIki Arif100% (5)
- VXVM Complete Training On SolarisDocument74 pagesVXVM Complete Training On SolarisSubash CtNo ratings yet
- Sun LDAP Admin GuideDocument256 pagesSun LDAP Admin GuideBenjamin SzokoNo ratings yet
- TrueOS HandbookDocument266 pagesTrueOS HandbookLucrécio Ricco AlmeidaNo ratings yet
- Oracle Solaris 11 Puppet Cheat Sheet Solaris Administration Resource TypesDocument9 pagesOracle Solaris 11 Puppet Cheat Sheet Solaris Administration Resource TypesBenedek RakovicsNo ratings yet
- D75915GC10 SG PDFDocument448 pagesD75915GC10 SG PDFHector Perez VilcapazaNo ratings yet
- Oracle Certkiller 1z0-822 140qDocument106 pagesOracle Certkiller 1z0-822 140qDenazareth JesusNo ratings yet
- Solaris 10 For Experienced System Administrators Student GuideDocument434 pagesSolaris 10 For Experienced System Administrators Student GuideKrishna KumarNo ratings yet
- Best Practices For Upgrading The Oracle ZFS Storage ApplianceDocument25 pagesBest Practices For Upgrading The Oracle ZFS Storage ApplianceHieu TranNo ratings yet
- Solaris Troubleshooting and Performance Tuning PDFDocument2 pagesSolaris Troubleshooting and Performance Tuning PDFveerenNo ratings yet
- Solaris 11 Administration Activity GuideDocument204 pagesSolaris 11 Administration Activity GuideakdenizerdemNo ratings yet
- D74942GC40 15947 UsDocument4 pagesD74942GC40 15947 UsWilliam LeeNo ratings yet
- A Brief Tour of RMF Monitor III Version 1.14Document256 pagesA Brief Tour of RMF Monitor III Version 1.14gborja8881331100% (1)
- How To Grow Zpool Using Online LUN ExpansionDocument5 pagesHow To Grow Zpool Using Online LUN ExpansioncresmakNo ratings yet
- BSD Magazine MaioDocument101 pagesBSD Magazine MaioBruno AlvimNo ratings yet
- Oracle Solaris ZfsDocument32 pagesOracle Solaris ZfsN.s. WarghadeNo ratings yet
- D72896GC30 Lesson01Document11 pagesD72896GC30 Lesson01linhniit123No ratings yet
- 820-4490 - Solaris 9 ContainersDocument48 pages820-4490 - Solaris 9 ContainersShahmat DahlanNo ratings yet
- Exadata BackupDocument27 pagesExadata BackupAnabel Reyes100% (1)
- Disk Scheduling Algorithms in OsDocument32 pagesDisk Scheduling Algorithms in OsRaghu NixelNo ratings yet
- Sun Storage 7000 Efficiency BWP 065183Document18 pagesSun Storage 7000 Efficiency BWP 065183venkatakrishna_018No ratings yet
- Docid 1346328.1Document5 pagesDocid 1346328.1Mara OrdinaryNo ratings yet
- Oracle Solaris 11 ZF S AdministrationDocument448 pagesOracle Solaris 11 ZF S AdministrationPablo Javier Fernández100% (2)
- How To Create IPS Repository in Solaris11 - IPS - UnixArenaDocument6 pagesHow To Create IPS Repository in Solaris11 - IPS - UnixArenaSahatma SiallaganNo ratings yet