You might also like
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
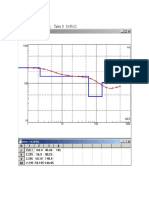
- Levantamento GeofísicoDocument2 pagesLevantamento Geofísicovelkus2013No ratings yet
- Guzmán Ovalle Omar Gpe. Tarea 8 01/05/12Document7 pagesGuzmán Ovalle Omar Gpe. Tarea 8 01/05/12velkus2013No ratings yet
- Gravity and Magnetic InterpretationDocument3 pagesGravity and Magnetic Interpretationvelkus2013No ratings yet
- Notas IncompletasDocument127 pagesNotas Incompletasvelkus2013No ratings yet
- Earthquake Phan Chiang Rai - SACDocument3 pagesEarthquake Phan Chiang Rai - SACvelkus2013No ratings yet
- Some SAC Tips & Macro Examples for SeismologyDocument7 pagesSome SAC Tips & Macro Examples for Seismologyvelkus2013No ratings yet
- Geo PediaDocument2 pagesGeo Pediavelkus2013No ratings yet
- Hydraulic Fracturing's History and Role in Energy DevelopmentDocument4 pagesHydraulic Fracturing's History and Role in Energy Developmentvelkus2013No ratings yet
- The Evolution of Log Analysis Methods Over 130 YearsDocument3 pagesThe Evolution of Log Analysis Methods Over 130 Yearsvelkus2013No ratings yet
- Some SAC Tips & Macro Examples for SeismologyDocument7 pagesSome SAC Tips & Macro Examples for Seismologyvelkus2013No ratings yet
- Appendix Charts TablesDocument17 pagesAppendix Charts Tablesvelkus2013No ratings yet
- SAC Signal Stacking ManualDocument2 pagesSAC Signal Stacking Manualvelkus2013No ratings yet
- Seismic AttributesDocument4 pagesSeismic Attributesvelkus2013No ratings yet
- Appendix Charts TablesDocument17 pagesAppendix Charts Tablesvelkus2013No ratings yet
- SAC2000 TutorialDocument10 pagesSAC2000 Tutorialvelkus2013No ratings yet
- SAC TutorialDocument26 pagesSAC Tutorialvelkus2013100% (1)
- SACTutorial 2Document3 pagesSACTutorial 2velkus2013No ratings yet
- Introduction To Seismic Analysis Code - Zhigang PengDocument7 pagesIntroduction To Seismic Analysis Code - Zhigang Pengvelkus2013No ratings yet
- What Causes EarthquakesDocument6 pagesWhat Causes Earthquakesvelkus2013No ratings yet
- SAC Tutorial 1Document8 pagesSAC Tutorial 1velkus2013No ratings yet
- SAC Tutorial 4Document6 pagesSAC Tutorial 4velkus2013No ratings yet
- SAC Tutorial 5Document4 pagesSAC Tutorial 5velkus2013No ratings yet
- SAC Tutorial 3Document6 pagesSAC Tutorial 3velkus2013No ratings yet
- The Movement of Seismic Waves Through The EarthDocument3 pagesThe Movement of Seismic Waves Through The Earthvelkus2013No ratings yet
- How Do We Measure and Locate EarthquakesDocument5 pagesHow Do We Measure and Locate Earthquakesvelkus2013No ratings yet
- Seismic Study of Earth's InteriorDocument8 pagesSeismic Study of Earth's Interiorvelkus2013No ratings yet
- De Ning The Size of EarthquakesDocument6 pagesDe Ning The Size of Earthquakesvelkus2013No ratings yet
- 3D Electric Prospecting - Vinokurovsky SiteDocument2 pages3D Electric Prospecting - Vinokurovsky Sitevelkus2013No ratings yet
- 3D Electric Prospecting - Works Near Aikhal TownDocument2 pages3D Electric Prospecting - Works Near Aikhal Townvelkus2013No ratings yet
- 3D Electric Prospecting - VECS ProgramsDocument1 page3D Electric Prospecting - VECS Programsvelkus2013No ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- AnovaDocument2 pagesAnovaapplesbyNo ratings yet
- Use The Data in WAGE File To Estimate A Simple Regression Explaining Monthly SalaryDocument4 pagesUse The Data in WAGE File To Estimate A Simple Regression Explaining Monthly SalaryLiza NagpalNo ratings yet
- Session 7-8 - Data Cleaning and Logistic Regression For ClassificationDocument30 pagesSession 7-8 - Data Cleaning and Logistic Regression For ClassificationShishir GuptaNo ratings yet
- DSFDFDGFDGDocument19 pagesDSFDFDGFDGRavindraNo ratings yet
- Demand Management and Forecasting: Mcgraw-Hill/IrwinDocument15 pagesDemand Management and Forecasting: Mcgraw-Hill/Irwinanna regarNo ratings yet
- Data Science Course OverviewDocument13 pagesData Science Course OverviewShahid ShaikhNo ratings yet
- RSMM Divya ProjectDocument84 pagesRSMM Divya ProjectGaurav NarayanNo ratings yet
- 1 Anova Oneway BDocument3 pages1 Anova Oneway BNazia SyedNo ratings yet
- Econometrics exam questions and regression resultsDocument6 pagesEconometrics exam questions and regression resultsLinaNo ratings yet
- Case Study For Reasons of Software Projects Failure: STUDENT NAMES: Ashenafi GadisaDocument21 pagesCase Study For Reasons of Software Projects Failure: STUDENT NAMES: Ashenafi Gadisaeyorica28No ratings yet
- STAT 302 Midterm 1Document10 pagesSTAT 302 Midterm 1Siiroostaiii KoomiaarNo ratings yet
- StatisticsDocument211 pagesStatisticsHasan Hüseyin Çakır100% (6)
- Regression Analysis of Learning Time, IQ, and Academic AchievementDocument4 pagesRegression Analysis of Learning Time, IQ, and Academic AchievementM. FADHILNo ratings yet
- One Way AnovaDocument16 pagesOne Way AnovaChe Macasa SeñoNo ratings yet
- Course Challenge - CourseraDocument1 pageCourse Challenge - CourserahajjeaopaNo ratings yet
- Mis Analyst Job Description - Google SearchDocument1 pageMis Analyst Job Description - Google SearchGina MercadoNo ratings yet
- 06 Writing Data Analysis ReportsDocument2 pages06 Writing Data Analysis ReportsAprameya TNo ratings yet
- Quantitative Analysis For Management Ch04Document71 pagesQuantitative Analysis For Management Ch04Qonita Nazhifa100% (1)
- Regression in Geoda: Briggs Henan University 2010 1Document37 pagesRegression in Geoda: Briggs Henan University 2010 1kimhoaNo ratings yet
- Dunkin Donuts Wait Time TestDocument3 pagesDunkin Donuts Wait Time TestSteve ArgenteNo ratings yet
- A Validation of The Family Involvement Questionnaire-High School VersionDocument14 pagesA Validation of The Family Involvement Questionnaire-High School VersionWalter ManliguezNo ratings yet
- Hailey College of Banking and Finance (HCBF) : Satisfaction and Perceived Productivity When Employees Work From HomeDocument4 pagesHailey College of Banking and Finance (HCBF) : Satisfaction and Perceived Productivity When Employees Work From HomeRana hamzaNo ratings yet
- Himalya ReportDocument46 pagesHimalya Reportujwaljaiswal61% (31)
- DMPM VD1 Assignment Question and Marking CriteriaDocument2 pagesDMPM VD1 Assignment Question and Marking CriteriaJelly Holmes0% (1)
- Predictive Modeling Questions and AnswersDocument32 pagesPredictive Modeling Questions and AnswersAsim Mazin100% (1)
- Estimating Entry Capacity of Roundabouts in NepalDocument57 pagesEstimating Entry Capacity of Roundabouts in NepalBipin GyawaliNo ratings yet
- The Role of Local Food in Maldives Tourism: A Focus On Promotion and Economic DevelopmentDocument209 pagesThe Role of Local Food in Maldives Tourism: A Focus On Promotion and Economic Developmentadriana liunomeNo ratings yet
- DMKDDDocument56 pagesDMKDDEr Nitin Lal ChandaniNo ratings yet
- Task 3: (CITATION Bel18 /L 2057)Document5 pagesTask 3: (CITATION Bel18 /L 2057)Nadia RiazNo ratings yet
- Control Charts For VariablesDocument25 pagesControl Charts For VariablesJassfer AlinaNo ratings yet