You might also like
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5795)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1091)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Motion To Revoke Detention OrderDocument21 pagesMotion To Revoke Detention OrderStephen LoiaconiNo ratings yet
- Objectives: A. Identify The Reasons For Keeping Business Records and B. Perform Key Bookkeeping TaskDocument11 pagesObjectives: A. Identify The Reasons For Keeping Business Records and B. Perform Key Bookkeeping TaskMarife CulabaNo ratings yet
- B1 Adjectives Ending in - ED and - ING AD006: Worksheets - English-Grammar - atDocument2 pagesB1 Adjectives Ending in - ED and - ING AD006: Worksheets - English-Grammar - atLucía Di CarloNo ratings yet
- Reading Exercise 2Document2 pagesReading Exercise 2Park Hanna100% (1)
- How Common Indian People Take Investment Decisions Exploring Aspects of Behavioral Economics in IndiaDocument3 pagesHow Common Indian People Take Investment Decisions Exploring Aspects of Behavioral Economics in IndiaInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Ayurveda Secrets of Healing Maya Tiwari.07172 2seasonal CleansingDocument5 pagesAyurveda Secrets of Healing Maya Tiwari.07172 2seasonal CleansingkidiyoorNo ratings yet
- Curriculum Implementation & EvaluationDocument121 pagesCurriculum Implementation & Evaluationwaseem555100% (2)
- Baartiya Saucanaa P'Aovaoigaki Samsqaana, (Laahabaad: Indian Institute of Information Technology, AllahabadDocument1 pageBaartiya Saucanaa P'Aovaoigaki Samsqaana, (Laahabaad: Indian Institute of Information Technology, AllahabadshivanshuNo ratings yet
- Natural Response of An RC CircuitDocument2 pagesNatural Response of An RC CircuitshivanshuNo ratings yet
- Home Assignment-10: Electromagnetic Theory (EE340)Document1 pageHome Assignment-10: Electromagnetic Theory (EE340)shivanshu100% (1)
- Capacitors in Series and ParallelDocument2 pagesCapacitors in Series and ParallelshivanshuNo ratings yet
- Introduction To Phasors 2: The MethodDocument1 pageIntroduction To Phasors 2: The MethodshivanshuNo ratings yet
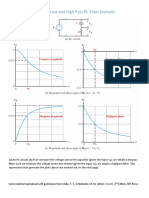
- 1 Order Low and High Pass RC Filter ExampleDocument2 pages1 Order Low and High Pass RC Filter ExampleshivanshuNo ratings yet
- Z R + JX: ImpedanceDocument1 pageZ R + JX: ImpedanceshivanshuNo ratings yet
- Introduction To Phasors 1: Sinusoidal SignalsDocument2 pagesIntroduction To Phasors 1: Sinusoidal SignalsshivanshuNo ratings yet
- Measuring Voltages and CurrentsDocument1 pageMeasuring Voltages and CurrentsshivanshuNo ratings yet
- PM Plan Template For PresentationDocument3 pagesPM Plan Template For Presentationjamal123456No ratings yet
- Tool - Single Double Triple Loop LearningDocument2 pagesTool - Single Double Triple Loop LearningDwiAryantiNo ratings yet
- Quality MagazineDocument80 pagesQuality MagazineFlavius ArdeleanNo ratings yet
- ST Learning Task 10Document6 pagesST Learning Task 10Jermaine DoloritoNo ratings yet
- Headache PAINDocument1 pageHeadache PAINOmarNo ratings yet
- Seven Years WarDocument55 pagesSeven Years WarKismat Dhaliwal100% (1)
- Dacera Vs Dela SernaDocument2 pagesDacera Vs Dela SernaDarlo HernandezNo ratings yet
- Art App Finals OutputDocument3 pagesArt App Finals OutputChariz Kate DungogNo ratings yet
- BergsonDocument17 pagesBergsonAnonymous p3lyFYNo ratings yet
- Attitude On The Job PerformanceDocument11 pagesAttitude On The Job PerformanceMarry Belle VidalNo ratings yet
- Itm University, Raipur (Chhattisgarh) IndiaDocument5 pagesItm University, Raipur (Chhattisgarh) Indiajassi7nishadNo ratings yet
- Shaft KeywayDocument8 pagesShaft KeywayturboconchNo ratings yet
- Unit 11 Writing Task: Write An Email To A Friend Worksheet 1: PRE-WRITINGDocument3 pagesUnit 11 Writing Task: Write An Email To A Friend Worksheet 1: PRE-WRITINGKhaled Ben SalmeenNo ratings yet
- Giving Counsel PDFDocument42 pagesGiving Counsel PDFPaul ChungNo ratings yet
- 00 FA17 ENG 2070 SyllabusDocument9 pages00 FA17 ENG 2070 SyllabusLauren SalisburyNo ratings yet
- LLCE CoursDocument18 pagesLLCE CoursDaphné ScetbunNo ratings yet
- Mechanics of Materials Lab 1-Zip Tie Tensile TestingDocument7 pagesMechanics of Materials Lab 1-Zip Tie Tensile TestingcoolshavaNo ratings yet
- Transparency IIDocument25 pagesTransparency IIKatyanne ToppingNo ratings yet
- Seng2011 - Assignment 5Document11 pagesSeng2011 - Assignment 5yajnas1996No ratings yet
- GR 148311-2005-In The Matter of The Adoption of StephanieDocument8 pagesGR 148311-2005-In The Matter of The Adoption of StephanieBogart CalderonNo ratings yet
- Mobilization Plan 18 19Document1 pageMobilization Plan 18 19John Rusty Figuracion100% (1)
- What Is Talent AcquisitionDocument6 pagesWhat Is Talent AcquisitionMJ KuhneNo ratings yet
- CaseLaw RundownDocument1 pageCaseLaw RundownTrent WallaceNo ratings yet