You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- A Literature-Based Guide To The Conservative and Surgical Management of CharcotDocument13 pagesA Literature-Based Guide To The Conservative and Surgical Management of Charcotroxyal04No ratings yet
- 1 s2.0 S1984006315000607 MainDocument10 pages1 s2.0 S1984006315000607 Mainroxyal04No ratings yet
- AACE Diabetes Algorithm Executive 2016Document30 pagesAACE Diabetes Algorithm Executive 2016Luis Andres Carrero TovarNo ratings yet
- Anexa Evaluare 2014-2015 RalucaDocument9 pagesAnexa Evaluare 2014-2015 Ralucaroxyal04No ratings yet
- Development and Validity of A Questionnaire To Test The Knowledge of Primary Care Personnel Regarding Nutrition in Obese AdolescentsDocument10 pagesDevelopment and Validity of A Questionnaire To Test The Knowledge of Primary Care Personnel Regarding Nutrition in Obese Adolescentsroxyal04No ratings yet
- Biostats305 MultinomialDocument11 pagesBiostats305 Multinomialroxyal04No ratings yet
- Alina Delia Popa - Determinants of Inadequate Weight Gain in PregancyDocument7 pagesAlina Delia Popa - Determinants of Inadequate Weight Gain in Pregancyroxyal04No ratings yet
- Nutritional Knowledge Sa AdolescentsDocument2 pagesNutritional Knowledge Sa Adolescentsroxyal04No ratings yet
- Bukenya SNEB 2015Document1 pageBukenya SNEB 2015roxyal04No ratings yet
- Articol RMCDocument7 pagesArticol RMCroxyal04No ratings yet
- Biostatistics 202: Logistic Regression Analysis: YhchanDocument5 pagesBiostatistics 202: Logistic Regression Analysis: Yhchanroxyal04No ratings yet
- R02 - Turner 1976 - The Real Self ...Document4 pagesR02 - Turner 1976 - The Real Self ...roxyal04100% (1)
- 102 Combinatorial ProblemsDocument149 pages102 Combinatorial Problemsroxyal04No ratings yet
- Basmul PopularDocument3 pagesBasmul Popularroxyal04No ratings yet
- Ghid DZ Ada EasdDocument16 pagesGhid DZ Ada Easdpanchoss2001No ratings yet
- Final 12 Popa Alina Mip AoDocument7 pagesFinal 12 Popa Alina Mip Aoroxyal04No ratings yet
- HP Mar02 ErrorDocument5 pagesHP Mar02 Errorroxyal04No ratings yet
- 6 Brunet SabistonDocument7 pages6 Brunet Sabistonroxyal04No ratings yet
- Retinopati DiabetikDocument147 pagesRetinopati DiabetikAlexa's StuffNo ratings yet
- SandbaggingDocument12 pagesSandbaggingroxyal04No ratings yet
- 003 SMBG Guideline HSC August 2011 - 355KBDocument8 pages003 SMBG Guideline HSC August 2011 - 355KBroxyal04No ratings yet
- More Mentoring Needed? A Cross-Sectional Study of Mentoring Programs For Medical Students in GermanyDocument11 pagesMore Mentoring Needed? A Cross-Sectional Study of Mentoring Programs For Medical Students in Germanyroxyal04No ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Internship Report of AryanDocument30 pagesInternship Report of AryanVaibhav MawalNo ratings yet
- Sample Size and Optimal Design For Logistic Regression With Binary Interaction - Eugene DemidenkoDocument11 pagesSample Size and Optimal Design For Logistic Regression With Binary Interaction - Eugene DemidenkodbmestNo ratings yet
- Investors Awareness and Perception Towards Mutual Fund Investment:an Exploratory StudyDocument11 pagesInvestors Awareness and Perception Towards Mutual Fund Investment:an Exploratory StudyIJAR JOURNALNo ratings yet
- IJEMR - April 2016 - Vol 6 Issue 04 - Online - ISSN 2249-2585 Print - ISSN 2249-8672Document16 pagesIJEMR - April 2016 - Vol 6 Issue 04 - Online - ISSN 2249-2585 Print - ISSN 2249-8672archerselevatorsNo ratings yet
- Analisis Univariat - Bivariat, Ci 95% Case ControlDocument16 pagesAnalisis Univariat - Bivariat, Ci 95% Case ControlathyNo ratings yet
- LampiranDocument6 pagesLampiraniis midiawatiNo ratings yet
- Maximum Likelihood Programming in Stata: January 2003Document18 pagesMaximum Likelihood Programming in Stata: January 2003nachersNo ratings yet
- RMP - Folder 6 - Audio and Other Records (Inmarsat) - NihonmamaDocument82 pagesRMP - Folder 6 - Audio and Other Records (Inmarsat) - NihonmamaNam Khánh NguyễnNo ratings yet
- SPSS Binary Logistic Regression Demo 1 TerminateDocument22 pagesSPSS Binary Logistic Regression Demo 1 Terminatefahadraja78No ratings yet
- Chapter 3. Panel Threshold Regression ModelsDocument86 pagesChapter 3. Panel Threshold Regression ModelsdorinNo ratings yet
- Tugas Crosstab Pengantar Statistik: Hubungan Antara Bidang Kerja Terhadap Tingkat Penghasilan Dan StatusDocument3 pagesTugas Crosstab Pengantar Statistik: Hubungan Antara Bidang Kerja Terhadap Tingkat Penghasilan Dan StatusIcha LawiNo ratings yet
- Cluster Analysis Chap8Document42 pagesCluster Analysis Chap8manoj manishNo ratings yet
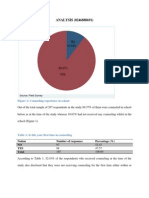
- ANALYSIS (0246888691) : Figure 1: Counseling Experience in SchoolDocument8 pagesANALYSIS (0246888691) : Figure 1: Counseling Experience in SchoolApam BenjaminNo ratings yet
- Evaluation of Employment Outcomes of Project Search UKDocument27 pagesEvaluation of Employment Outcomes of Project Search UKThe Centre for Welfare ReformNo ratings yet
- A R S C P T M-C: Esearch To Tudy The Onsumer Erception Owards OmmerceDocument43 pagesA R S C P T M-C: Esearch To Tudy The Onsumer Erception Owards OmmerceSaransh AggarwalNo ratings yet
- Generalized Linear Models-1Document29 pagesGeneralized Linear Models-1Ann BaisaNo ratings yet
- Logistic Regression TutorialDocument25 pagesLogistic Regression TutorialDaphneNo ratings yet
- Likelihood-Ratio TestDocument5 pagesLikelihood-Ratio Testdev414No ratings yet
- STAT 2006 II SyllabusDocument2 pagesSTAT 2006 II SyllabusHoi Yee Karis LauNo ratings yet
- Lecture 4 Day 3 Stochastic Frontier AnalysisDocument45 pagesLecture 4 Day 3 Stochastic Frontier Analysistrpitono100% (1)
- Solutions Odd For CategoricalDocument28 pagesSolutions Odd For CategoricalShi LijiaNo ratings yet
- Statistical Analysis On Accident RateDocument30 pagesStatistical Analysis On Accident RateOladosu muritala100% (1)
- Trends in Residential Market in BangalorDocument9 pagesTrends in Residential Market in BangalorAritra NandyNo ratings yet
- Morrison - Distinguishing Between Forensic Science and Forensic PseudoscienceDocument12 pagesMorrison - Distinguishing Between Forensic Science and Forensic PseudoscienceSara Valencia SánchezNo ratings yet
- A Study On Consumer Satisfaction Towards Indian OilDocument12 pagesA Study On Consumer Satisfaction Towards Indian Oilarthiloosu421No ratings yet
- Paytm ProjectpdfDocument28 pagesPaytm ProjectpdfKishan100% (1)
- "Customers Satistfaction Towards Promotional Strategies of D-Mart in Jalgaon City" A Project Work Submitted To Moolji Jaitha College, JalgaonDocument36 pages"Customers Satistfaction Towards Promotional Strategies of D-Mart in Jalgaon City" A Project Work Submitted To Moolji Jaitha College, JalgaonAnkita BhamreNo ratings yet
- Home Lesson 15: Logistic, Poisson & Nonlinear RegressionDocument32 pagesHome Lesson 15: Logistic, Poisson & Nonlinear RegressionShubham TewariNo ratings yet
- FE NotesDocument189 pagesFE NotesRajib SarkarNo ratings yet
- Project Report - Shubham MehtaDocument48 pagesProject Report - Shubham Mehtaefc3wNo ratings yet