You might also like
- Topic 5 - Intro To Random ProcessesDocument64 pagesTopic 5 - Intro To Random ProcessesHamza MahmoodNo ratings yet
- Syh Opc 76 12 2016Document158 pagesSyh Opc 76 12 2016sybaritzNo ratings yet
- The Component Object ModelDocument54 pagesThe Component Object ModelhssarochNo ratings yet
- Com PDFDocument2,063 pagesCom PDFimran hameer0% (1)
- Lecture 5-7 Random ProcessDocument82 pagesLecture 5-7 Random ProcessVara GayathriNo ratings yet
- CorrelationDocument103 pagesCorrelationpdnkiranNo ratings yet
- DCOM Microsoft Distributed Component Object ModelDocument392 pagesDCOM Microsoft Distributed Component Object Modelstevenronald3136No ratings yet
- Basic Kronecker NotesDocument9 pagesBasic Kronecker Notesnisargb100% (1)
- Spectrum EstimationDocument49 pagesSpectrum EstimationzeebetNo ratings yet
- C01 - Course Information V2-1Document12 pagesC01 - Course Information V2-1zvonkomihajlovic4891No ratings yet
- Image Rotation Using Graphical User InterfaceDocument5 pagesImage Rotation Using Graphical User InterfaceUmeshNo ratings yet
- Solutions To Chapter 7 Problems: Problem 7.1Document51 pagesSolutions To Chapter 7 Problems: Problem 7.1Anonymous ZyDssAc7RcNo ratings yet
- FSK Demodulator With PLLDocument5 pagesFSK Demodulator With PLLHema100% (1)
- Volterra SeriesDocument50 pagesVolterra Seriessaleh1978No ratings yet
- Modelado Rotary Pendulum Workbook InstructorDocument60 pagesModelado Rotary Pendulum Workbook Instructorsolid34No ratings yet
- ETHERNET Powerlink: User's ManualDocument98 pagesETHERNET Powerlink: User's ManualHolicsNo ratings yet
- PMC Development Fanuc Ladder-Iii: FeaturesDocument2 pagesPMC Development Fanuc Ladder-Iii: FeaturesLeo VazquezNo ratings yet
- Pole Placement1Document46 pagesPole Placement1masd100% (1)
- Chapter 2 2d TransformationDocument21 pagesChapter 2 2d TransformationManpreet KaurNo ratings yet
- Tutorial Guide: BE A CAE Systems S.ADocument8 pagesTutorial Guide: BE A CAE Systems S.ASantosh KumarNo ratings yet
- QUBE-Servo Inverted Pendulum ModelingDocument4 pagesQUBE-Servo Inverted Pendulum ModelingByron Xavier Lima CedilloNo ratings yet
- MATSIM Simulink For Process ControlDocument10 pagesMATSIM Simulink For Process ControlEslamAbdEl-GhanyNo ratings yet
- Zarchan-Lecture Kalman Filter9Document104 pagesZarchan-Lecture Kalman Filter9larasmoyoNo ratings yet
- PsoDocument17 pagesPsoKanishka SahniNo ratings yet
- Gfk1413C - CIMPLICITY HMI Statistical Process Control Operation ManualDocument100 pagesGfk1413C - CIMPLICITY HMI Statistical Process Control Operation ManualEduardo NascimentoNo ratings yet
- SK-82701-S1 - Airpax DatasheetDocument3 pagesSK-82701-S1 - Airpax DatasheetAnonymous 7t2BOJbNo ratings yet
- Ecodrive-Fgp03 FK02Document428 pagesEcodrive-Fgp03 FK02SomeUser100% (1)
- Nonlinear Zero Dynamics in Control SystemsDocument12 pagesNonlinear Zero Dynamics in Control SystemsAshik AhmedNo ratings yet
- Bangladesh University of Professionals Department of Information and Communication Technology Course No.: Communication Theory Laboratory (ICT 2208)Document2 pagesBangladesh University of Professionals Department of Information and Communication Technology Course No.: Communication Theory Laboratory (ICT 2208)Sadia AfreenNo ratings yet
- ECE 2208 - Lab ManualDocument71 pagesECE 2208 - Lab ManualpythagoraNo ratings yet
- Digital Filter MatlabDocument37 pagesDigital Filter MatlabYahya Muhammad AdamNo ratings yet
- Introduction To Control SystemDocument51 pagesIntroduction To Control SystemNorkarlina Binti Khairul AriffinNo ratings yet
- Instruction ManualDocument245 pagesInstruction ManualOscar Vazquez Espinosa100% (1)
- OpcDocument94 pagesOpcrharihar26597No ratings yet
- Pages From (Monson Hayes) Schaum S Outline of Digital SignalDocument7 pagesPages From (Monson Hayes) Schaum S Outline of Digital SignalMhmdÁbdóNo ratings yet
- Z TransformDocument9 pagesZ TransformKiran Googly JadhavNo ratings yet
- Expt 3 Generation of Continous Signal CañeteDocument4 pagesExpt 3 Generation of Continous Signal CañeteJHUSTINE CAÑETENo ratings yet
- SCL Cheat SheetDocument2 pagesSCL Cheat SheetboegschroefNo ratings yet
- Ecler DPA600 - DPA1000 - DPA1400 - DPA2000 Stereo AmplifierDocument139 pagesEcler DPA600 - DPA1000 - DPA1400 - DPA2000 Stereo AmplifierJUAN CARLOS TARMA CASTILLONo ratings yet
- Wagoappjson: Release 1.1.0.11Document32 pagesWagoappjson: Release 1.1.0.11MarcioWatanabeNo ratings yet
- Ball and Beam DynamicsDocument9 pagesBall and Beam Dynamicssaw2010No ratings yet
- Delta PLC-Program O EN 20130530 PDFDocument754 pagesDelta PLC-Program O EN 20130530 PDFMuhammad IshtiaqNo ratings yet
- 3BDD011932-111 A en Freelance Operation Guide Freelance OperationsDocument351 pages3BDD011932-111 A en Freelance Operation Guide Freelance OperationsMathias MolleNo ratings yet
- MATLAB - Modelling in Time Domain - Norman NiseDocument3 pagesMATLAB - Modelling in Time Domain - Norman Niseichigo325No ratings yet
- 4) Simulink S Function Miniguide Rev06Document15 pages4) Simulink S Function Miniguide Rev06Motasim_mNo ratings yet
- Modeling and Control of An Acrobot Using MATLAB and SimulinkDocument4 pagesModeling and Control of An Acrobot Using MATLAB and SimulinkridhoNo ratings yet
- The Laplace Transform FileDocument42 pagesThe Laplace Transform FilegainchoudharyNo ratings yet
- Mo Phong Matlab Ball and BeamDocument52 pagesMo Phong Matlab Ball and BeamHuong NguyenNo ratings yet
- Cs421 Cheat SheetDocument2 pagesCs421 Cheat SheetJoe McGuckinNo ratings yet
- Eigenfunctions of The Laplace-Beltrami Operator On HyperboloidsDocument5 pagesEigenfunctions of The Laplace-Beltrami Operator On HyperboloidsMarcos BrumNo ratings yet
- Linear Algebra Cheat SheetDocument2 pagesLinear Algebra Cheat SheettraponegroNo ratings yet
- ARMA Autocorrelation FunctionsDocument21 pagesARMA Autocorrelation FunctionsbboyvnNo ratings yet
- The World of Eigenvalues-Eigenfunctions: Eigenfunction EigenvalueDocument9 pagesThe World of Eigenvalues-Eigenfunctions: Eigenfunction EigenvalueRaj KumarNo ratings yet
- MCMC BriefDocument69 pagesMCMC Briefjakub_gramolNo ratings yet
- Shift-Register Synthesis (Modulo M)Document23 pagesShift-Register Synthesis (Modulo M)Shravan KumarNo ratings yet
- Linearna Algebra I Geometrija: Univerzitet U Sarajevu Elektrotehni Ki FakultetDocument12 pagesLinearna Algebra I Geometrija: Univerzitet U Sarajevu Elektrotehni Ki FakultetAnthony GarciaNo ratings yet
- Pade Approximation ProofDocument7 pagesPade Approximation ProofjjtexNo ratings yet
- Paper2 AHP PDFDocument4 pagesPaper2 AHP PDFtusharsinghal94No ratings yet
- The India Startup Story: A Paradigm Shift in The Startup Business ModelDocument2 pagesThe India Startup Story: A Paradigm Shift in The Startup Business Modeltusharsinghal94No ratings yet
- AHPpractice QuestionsDocument3 pagesAHPpractice Questionstusharsinghal940% (1)
- AHPpractice QuestionsDocument3 pagesAHPpractice Questionstusharsinghal940% (1)
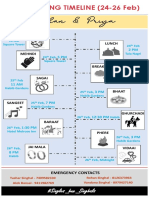
- TheTimeline PDFDocument1 pageTheTimeline PDFtusharsinghal94No ratings yet
- Paper2 AHP PDFDocument4 pagesPaper2 AHP PDFtusharsinghal94No ratings yet
- The TimelineDocument1 pageThe Timelinetusharsinghal94No ratings yet
- GVCs and Their Impact On Effectiveness of Monetary PolicyDocument3 pagesGVCs and Their Impact On Effectiveness of Monetary Policytusharsinghal94No ratings yet
- MIS - Development Process - TutorialspointDocument6 pagesMIS - Development Process - Tutorialspointtusharsinghal94No ratings yet
- GVCs and Their Impact On Effectiveness of Monetary PolicyDocument3 pagesGVCs and Their Impact On Effectiveness of Monetary Policytusharsinghal94No ratings yet
- Adopting Actionable Data-Driven Marketing Strategies - Think With GoogleDocument7 pagesAdopting Actionable Data-Driven Marketing Strategies - Think With Googletusharsinghal94No ratings yet
- ACMA Mckinsey Study 2017 Future MobilityDocument36 pagesACMA Mckinsey Study 2017 Future Mobilitytusharsinghal94No ratings yet
- 6 Billion ShoppersDocument4 pages6 Billion Shopperstusharsinghal94No ratings yet
- 6 Billion ShoppersDocument3 pages6 Billion Shopperstusharsinghal94No ratings yet
- Con Club - Fms Delhi: Online Induction Learning - Batch 2021 - Activity 3Document3 pagesCon Club - Fms Delhi: Online Induction Learning - Batch 2021 - Activity 3tusharsinghal94No ratings yet
- Fly Ash A Billion Dollar ResourceDocument13 pagesFly Ash A Billion Dollar Resourcetusharsinghal94No ratings yet
- Tushar Singhal Task3Document1 pageTushar Singhal Task3tusharsinghal94No ratings yet
- Introduction To Human MovementDocument5 pagesIntroduction To Human MovementNiema Tejano FloroNo ratings yet
- Malaybalay CityDocument28 pagesMalaybalay CityCalvin Wong, Jr.No ratings yet
- Form PersonalizationDocument5 pagesForm PersonalizationSuneelTejNo ratings yet
- Jail Versus Substance Abuse TreatmentDocument5 pagesJail Versus Substance Abuse Treatmentapi-240257564No ratings yet
- By Vaibhav Pandya S R.information Security Consultant M.Tech Solutions (India) PVT - LTDDocument22 pagesBy Vaibhav Pandya S R.information Security Consultant M.Tech Solutions (India) PVT - LTDtsegay.csNo ratings yet
- Industry GeneralDocument24 pagesIndustry GeneralilieoniciucNo ratings yet
- Mars Atlas MOM 8 13Document6 pagesMars Atlas MOM 8 13aldert_pathNo ratings yet
- Basics of Petroleum GeologyDocument23 pagesBasics of Petroleum GeologyShahnawaz MustafaNo ratings yet
- The Story of An Hour QuestionpoolDocument5 pagesThe Story of An Hour QuestionpoolAKM pro player 2019No ratings yet
- Enzymatic Hydrolysis, Analysis of Mucic Acid Crystals and Osazones, and Thin - Layer Chromatography of Carbohydrates From CassavaDocument8 pagesEnzymatic Hydrolysis, Analysis of Mucic Acid Crystals and Osazones, and Thin - Layer Chromatography of Carbohydrates From CassavaKimberly Mae MesinaNo ratings yet
- Facts About The TudorsDocument3 pagesFacts About The TudorsRaluca MuresanNo ratings yet
- James KlotzDocument2 pagesJames KlotzMargaret ElwellNo ratings yet
- Refrigerador de Vacunas Vesfrost MKF 074Document5 pagesRefrigerador de Vacunas Vesfrost MKF 074Brevas CuchoNo ratings yet
- Ethics FinalsDocument22 pagesEthics FinalsEll VNo ratings yet
- GSM Based Prepaid Electricity System With Theft Detection Using Arduino For The Domestic UserDocument13 pagesGSM Based Prepaid Electricity System With Theft Detection Using Arduino For The Domestic UserSanatana RoutNo ratings yet
- Vmware It Academy Program May2016Document26 pagesVmware It Academy Program May2016someoneNo ratings yet
- 8A L31 Phiếu BTDocument7 pages8A L31 Phiếu BTviennhuNo ratings yet
- DOMESDocument23 pagesDOMESMukthesh ErukullaNo ratings yet
- Rfis On Formliners, Cover, and EmbedmentsDocument36 pagesRfis On Formliners, Cover, and Embedmentsali tahaNo ratings yet
- Growth Kinetic Models For Microalgae Cultivation A ReviewDocument16 pagesGrowth Kinetic Models For Microalgae Cultivation A ReviewJesús Eduardo De la CruzNo ratings yet
- Using Ms-Dos 6.22Document1,053 pagesUsing Ms-Dos 6.22lorimer78100% (3)
- CBSE Class 12 Informatics Practices Marking Scheme Term 2 For 2021 22Document6 pagesCBSE Class 12 Informatics Practices Marking Scheme Term 2 For 2021 22Aryan BhardwajNo ratings yet
- The Innovator - S SolutionDocument21 pagesThe Innovator - S SolutionKeijjo Matti100% (1)
- Computer Science HandbookDocument50 pagesComputer Science HandbookdivineamunegaNo ratings yet
- Advantages of The CapmDocument3 pagesAdvantages of The Capmdeeparaghu6No ratings yet
- Enzymes WorksheetDocument5 pagesEnzymes WorksheetgyunimNo ratings yet
- Technology in Society: SciencedirectDocument10 pagesTechnology in Society: SciencedirectVARGAS MEDINA ALEJANDRANo ratings yet
- Integrated Management System 2016Document16 pagesIntegrated Management System 2016Mohamed HamedNo ratings yet
- Chapter 3-CP For Armed Conflict SituationDocument23 pagesChapter 3-CP For Armed Conflict Situationisidro.ganadenNo ratings yet
- Lenovo S340-15iwl Compal LA-H101P SchematicDocument53 pagesLenovo S340-15iwl Compal LA-H101P SchematicYetawa Guaviare100% (4)