You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Ramirez, Mark I. - 3BSA5B. Module 3&4 (AutoRecovered)Document13 pagesRamirez, Mark I. - 3BSA5B. Module 3&4 (AutoRecovered)Mark Ramirez0% (1)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Risk Return Structure of The Credit Card IndustryDocument17 pagesThe Risk Return Structure of The Credit Card IndustryCha-am JamalNo ratings yet
- Employment Public Aid RenewableDocument53 pagesEmployment Public Aid RenewablethierrydebelsNo ratings yet
- Deep Hot Biosphere - DR Thomas Gold-PNASDocument5 pagesDeep Hot Biosphere - DR Thomas Gold-PNASzaroia100% (1)
- The Arbitrage Pricing Model in FinanceDocument5 pagesThe Arbitrage Pricing Model in FinanceCha-am JamalNo ratings yet
- History of The Global Warming Scare. Chapter 2, 1985-1990Document3 pagesHistory of The Global Warming Scare. Chapter 2, 1985-1990Cha-am JamalNo ratings yet
- Gap Management 101Document6 pagesGap Management 101Cha-am JamalNo ratings yet
- Will Global Warming Wipe Out Tibet's Glaciers?Document3 pagesWill Global Warming Wipe Out Tibet's Glaciers?Cha-am JamalNo ratings yet
- Corruption in State Owned UtilitiesDocument8 pagesCorruption in State Owned UtilitiesCha-am JamalNo ratings yet
- History of The Global Warming Scare Chapter 5: 2000-2005Document5 pagesHistory of The Global Warming Scare Chapter 5: 2000-2005Cha-am JamalNo ratings yet
- Portfolio Theory Lecture NotesDocument2 pagesPortfolio Theory Lecture NotesCha-am Jamal100% (1)
- Keynes On InvestmentDocument2 pagesKeynes On InvestmentCha-am JamalNo ratings yet
- History of The Global Warming Scare: Chapter 1: 1980 - 1985Document3 pagesHistory of The Global Warming Scare: Chapter 1: 1980 - 1985Cha-am JamalNo ratings yet
- Corruption Case StudyDocument7 pagesCorruption Case StudyCha-am JamalNo ratings yet
- Enterprise Reform in ChinaDocument3 pagesEnterprise Reform in ChinaCha-am JamalNo ratings yet
- History of The Global Warming Scare: Chapter 4: 1995 - 2000Document6 pagesHistory of The Global Warming Scare: Chapter 4: 1995 - 2000Cha-am JamalNo ratings yet
- Dupont AnalysisDocument4 pagesDupont AnalysisCha-am JamalNo ratings yet
- Database NormalizationDocument2 pagesDatabase NormalizationCha-am JamalNo ratings yet
- Institutional Reforms For Capital Markets in ChinaDocument9 pagesInstitutional Reforms For Capital Markets in ChinaCha-am JamalNo ratings yet
- A Framework For MIS Effectiveness ResearchDocument8 pagesA Framework For MIS Effectiveness ResearchCha-am JamalNo ratings yet
- A Method For Constructing Likert ScalesDocument12 pagesA Method For Constructing Likert ScalesCha-am JamalNo ratings yet
- History of The Global Warming Scare: Chapter 3: 1990-1995Document5 pagesHistory of The Global Warming Scare: Chapter 3: 1990-1995Cha-am Jamal100% (1)
- Stock Exchange AutomationDocument2 pagesStock Exchange AutomationCha-am JamalNo ratings yet
- The Kyoto ProtocolDocument2 pagesThe Kyoto ProtocolCha-am Jamal100% (1)
- The Montreal ProtocolDocument2 pagesThe Montreal ProtocolCha-am JamalNo ratings yet
- The Re-Unification of IndiaDocument2 pagesThe Re-Unification of IndiaCha-am JamalNo ratings yet
- Village Life in BangladeshDocument3 pagesVillage Life in BangladeshCha-am Jamal0% (1)
- Moderate MuslimsDocument1 pageModerate MuslimsCha-am JamalNo ratings yet
- Ozone Hole News Archive: 1987 To 2005Document3 pagesOzone Hole News Archive: 1987 To 2005Cha-am JamalNo ratings yet
- The International Aid BusinessDocument1 pageThe International Aid BusinessCha-am JamalNo ratings yet
- PhysioEx Exercise 5 Activity 1Document3 pagesPhysioEx Exercise 5 Activity 1villanuevaparedesaracely4No ratings yet
- Q-Learning Based Link Adaptation in 5GDocument6 pagesQ-Learning Based Link Adaptation in 5Gkalyank1No ratings yet
- Effect of Attenuation and Distortion in Transmission LineDocument16 pagesEffect of Attenuation and Distortion in Transmission Lineமணி பிரபுNo ratings yet
- Ocr 33987 PP 09 Jan L Gce 2816 01Document12 pagesOcr 33987 PP 09 Jan L Gce 2816 01Philip_830No ratings yet
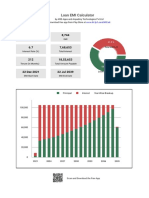
- Loan EMI Calculator: Download Free App From Play Store atDocument9 pagesLoan EMI Calculator: Download Free App From Play Store atkantilal rathodNo ratings yet
- M3 PPT 1 1 Phase Ac CircuitDocument67 pagesM3 PPT 1 1 Phase Ac CircuitUDhayNo ratings yet
- Solution Manual For Advanced Engineering Mathematics 7th Edition Peter OneilDocument35 pagesSolution Manual For Advanced Engineering Mathematics 7th Edition Peter Oneilbraidscanty8unib100% (49)
- ACI SP 309 Structural Integrity and Resilience Sasani Orton 2016Document132 pagesACI SP 309 Structural Integrity and Resilience Sasani Orton 2016Leang UyNo ratings yet
- Jean PiagetDocument23 pagesJean PiagetSachini PonweeraNo ratings yet
- ElectrostaticsDocument79 pagesElectrostaticsHead Department of PhysicsNo ratings yet
- Brownian MotionDocument76 pagesBrownian MotionPraveen KumarNo ratings yet
- PRINCIPLES OF MATHEMATICS CURRICULUM DESIGNDocument3 pagesPRINCIPLES OF MATHEMATICS CURRICULUM DESIGNKhadga Shrestha50% (2)
- Thermal Overload Protection Functional TestDocument1 pageThermal Overload Protection Functional TestMihai BancuNo ratings yet
- Thin Walled Composite BeamsDocument13 pagesThin Walled Composite Beamsrs0004No ratings yet
- Digital Notes: (Department of Computer Applications)Document14 pagesDigital Notes: (Department of Computer Applications)Anuj PrajapatiNo ratings yet
- Ppic MRPDocument6 pagesPpic MRPSandeep SatapathyNo ratings yet
- Stacks and QueuesDocument21 pagesStacks and QueuesDhivya NNo ratings yet
- Design Thinking PortfolioDocument11 pagesDesign Thinking Portfolioapi-246770572No ratings yet
- خطه الدراسةDocument1 pageخطه الدراسةد.مهندس.اسماعيل حميدNo ratings yet
- Trig Formula SheetDocument1 pageTrig Formula SheetNeil BreenNo ratings yet
- Amm 2010 N3Document101 pagesAmm 2010 N31110004No ratings yet
- FiltersDocument41 pagesFiltersAnusha yadavNo ratings yet
- Algebraic Factorization and Remainder TheoremsDocument5 pagesAlgebraic Factorization and Remainder TheoremsNisheli Amani PereraNo ratings yet
- ME Course Content Guide for AY2011/2012 IntakeDocument4 pagesME Course Content Guide for AY2011/2012 IntakedavidwongbxNo ratings yet
- Chapter 04 ISMDocument34 pagesChapter 04 ISMMekuannint DemekeNo ratings yet
- Che 312 Notebook DistillationDocument19 pagesChe 312 Notebook DistillationUGWU MARYANNNo ratings yet
- MINI Wind TurbineDocument14 pagesMINI Wind TurbineahdabmkNo ratings yet
- MAFE208IU-L7 InterpolationDocument35 pagesMAFE208IU-L7 InterpolationThy VũNo ratings yet
- Fake Reviews Detection Based On LDA: Shaohua Jia Xianguo Zhang, Xinyue Wang, Yang LiuDocument4 pagesFake Reviews Detection Based On LDA: Shaohua Jia Xianguo Zhang, Xinyue Wang, Yang LiuVivek AnandNo ratings yet