You might also like
- Objetivo GeneralDocument6 pagesObjetivo GeneralElizabeth Cristina Guerrero BrachoNo ratings yet
- Epistemología Tulio URBEDocument10 pagesEpistemología Tulio URBEElizabeth Cristina Guerrero BrachoNo ratings yet
- Tesis de Posgrado Yelitza AguilarDocument59 pagesTesis de Posgrado Yelitza AguilarElizabeth Cristina Guerrero BrachoNo ratings yet
- Tecnicas de GrupoDocument31 pagesTecnicas de Grupocazuquiro100% (1)
- Perspectivas de La InvestigaciónDocument9 pagesPerspectivas de La InvestigaciónElizabeth Cristina Guerrero BrachoNo ratings yet
- IHUHIHIDocument199 pagesIHUHIHILuis Gustavo Tuesta LambruschiniNo ratings yet
- Pensamiento CreativoDocument3 pagesPensamiento CreativoElizabeth Cristina Guerrero BrachoNo ratings yet
- Objetivo GeneralDocument6 pagesObjetivo GeneralElizabeth Cristina Guerrero BrachoNo ratings yet
- Matriz de CategorizaciónDocument1 pageMatriz de CategorizaciónElizabeth Cristina Guerrero BrachoNo ratings yet
- La AsertividadDocument15 pagesLa AsertividadElizabeth Cristina Guerrero BrachoNo ratings yet
- Tarea2herramientascolaborativas 131022180141 Phpapp02Document16 pagesTarea2herramientascolaborativas 131022180141 Phpapp02Elizabeth Cristina Guerrero BrachoNo ratings yet
- Impacto humano en la naturaleza y cambio climáticoDocument10 pagesImpacto humano en la naturaleza y cambio climáticoElizabeth Cristina Guerrero BrachoNo ratings yet
- PRESENTACION TESIS DOCTORAL 2 (Autoguardado)Document41 pagesPRESENTACION TESIS DOCTORAL 2 (Autoguardado)Elizabeth Cristina Guerrero BrachoNo ratings yet
- IHUHIHIDocument199 pagesIHUHIHILuis Gustavo Tuesta LambruschiniNo ratings yet
- Pedagogía Social LIPSDocument1 pagePedagogía Social LIPSElizabeth Cristina Guerrero BrachoNo ratings yet
- Para Encontrar El Reloj HolográficoDocument6 pagesPara Encontrar El Reloj HolográficoElizabeth Cristina Guerrero BrachoNo ratings yet
- 25 Aspectos Axiologicos Sobresalientes en La Practica DocenteDocument15 pages25 Aspectos Axiologicos Sobresalientes en La Practica DocenteElizabeth Cristina Guerrero BrachoNo ratings yet
- Valores sociales y participación ciudadanaDocument18 pagesValores sociales y participación ciudadanaElizabeth Cristina Guerrero BrachoNo ratings yet
- Tesis LiderazgoDocument111 pagesTesis LiderazgoAndrés ChávezNo ratings yet
- Alternancia Metodológica Hermenéutica-Heurística en La Construcción Curricular OkDocument119 pagesAlternancia Metodológica Hermenéutica-Heurística en La Construcción Curricular OkElizabeth Cristina Guerrero BrachoNo ratings yet
- Enfoque Holístico Por CompetenciasDocument125 pagesEnfoque Holístico Por CompetenciasElizabeth Cristina Guerrero BrachoNo ratings yet
- Discapacidad, Integración y Participación SocialDocument3 pagesDiscapacidad, Integración y Participación SocialElizabeth Cristina Guerrero BrachoNo ratings yet
- El Caracter AxiologicoDocument17 pagesEl Caracter AxiologicoElizabeth Cristina Guerrero BrachoNo ratings yet
- Congreso MaracaiboDocument8 pagesCongreso MaracaiboElizabeth Cristina Guerrero BrachoNo ratings yet
- Desafíos de La Administración Estratégica de Recursos Humanos y Gestión Del Talento Humano Por Competencias en MéxicoDocument24 pagesDesafíos de La Administración Estratégica de Recursos Humanos y Gestión Del Talento Humano Por Competencias en MéxicoElizabeth Cristina Guerrero BrachoNo ratings yet
- LiderazgoDocument7 pagesLiderazgoDiego PalaciosNo ratings yet
- Tesis LiderazgoDocument111 pagesTesis LiderazgoAndrés ChávezNo ratings yet
- Sistema Educativos en El MundoDocument18 pagesSistema Educativos en El MundoDavidAntonioNo ratings yet
- Motivación y SatisfacciónDocument208 pagesMotivación y SatisfacciónElizabeth Cristina Guerrero BrachoNo ratings yet
- Animarse A: Políticas Curriculares, Retórica Reformista y ResponsabilizaciónDocument19 pagesAnimarse A: Políticas Curriculares, Retórica Reformista y ResponsabilizaciónSilvia GrinbergNo ratings yet
- Nota Resumen Anuario de Estadisticas Deportivas 2023Document10 pagesNota Resumen Anuario de Estadisticas Deportivas 2023wolf 682No ratings yet
- Guia de Estimación de Parámetros Con MinitabDocument9 pagesGuia de Estimación de Parámetros Con MinitabcristhandartNo ratings yet
- Diseño Razonado de MuestrasDocument355 pagesDiseño Razonado de MuestrasJOAQUIN PEDRENo ratings yet
- Ejercicios de Distribucion NormalDocument7 pagesEjercicios de Distribucion NormalMartin Pingo Lopez100% (1)
- InterpretacióI-de-Cuadros-EstadisticosDocument5 pagesInterpretacióI-de-Cuadros-EstadisticosOscar Rujel LiderandoNo ratings yet
- Unidad 2 Distribuciones de FrecuenciasDocument13 pagesUnidad 2 Distribuciones de Frecuenciasdairelys100% (2)
- Informe Final SeminarioDocument11 pagesInforme Final Seminariomarlon diazNo ratings yet
- Apuntes Teoria de Muestreo Grupo 7a.Document16 pagesApuntes Teoria de Muestreo Grupo 7a.Anita VGNo ratings yet
- Lineamientos Elaboracion y Tramitacion Tesis Maestria o Doctorado Universidad GuadalajaraDocument66 pagesLineamientos Elaboracion y Tramitacion Tesis Maestria o Doctorado Universidad GuadalajaraMiguel Carrillo NavarroNo ratings yet
- Proporcion Aurea1Document18 pagesProporcion Aurea1qhalincha sumaqNo ratings yet
- Taller1 EstadisticasDocument4 pagesTaller1 Estadisticasjuliocesargomez60% (5)
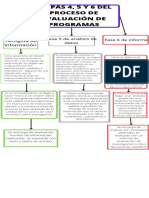
- Etapas 4, 5 y 6 Del Proceso de Evaluación de ProgramasDocument1 pageEtapas 4, 5 y 6 Del Proceso de Evaluación de ProgramasFELIPE REYES GARCIA NEYOYNo ratings yet
- Investigación PsicologíaDocument13 pagesInvestigación PsicologíaPsicol BrenNo ratings yet
- Métodos de muestreo para seleccionar una muestra representativaDocument2 pagesMétodos de muestreo para seleccionar una muestra representativaJIMENA MARIA DE LOS SANTOS CRUZNo ratings yet
- Principios de Experimentación y Causi-ExperimentaciónDocument20 pagesPrincipios de Experimentación y Causi-ExperimentaciónAbbyd AdamesNo ratings yet
- Apuntes de Econometría IDocument201 pagesApuntes de Econometría ILaura Patricia Sánchez100% (5)
- Examen Final - Estadistica II - (Grupo11)Document9 pagesExamen Final - Estadistica II - (Grupo11)cristianNo ratings yet
- ModuloResilienteSueloGranularDocument17 pagesModuloResilienteSueloGranularIleim AbernathyNo ratings yet
- Estudios R&R para evaluar calibrador vernierDocument6 pagesEstudios R&R para evaluar calibrador vernierHugo SalazarNo ratings yet
- Econometria Objeto Estudio Utilidades Principales PDFDocument7 pagesEconometria Objeto Estudio Utilidades Principales PDFricardoarmando.gonzalez2714No ratings yet
- Tarea 5. Semana 10. Introducción Del Ensayo y Metodología Del AIDocument4 pagesTarea 5. Semana 10. Introducción Del Ensayo y Metodología Del AIKaren Flores BartoloNo ratings yet
- Perfil Proyecto Residencia de Larga Estadia PDFDocument15 pagesPerfil Proyecto Residencia de Larga Estadia PDFLonoNo ratings yet
- Caracterización de Los Residuos SólidosDocument3 pagesCaracterización de Los Residuos SólidosCatalina EscobarNo ratings yet
- Introduccion A La Metodologia de La InvestigacionDocument4 pagesIntroduccion A La Metodologia de La InvestigacionLeFührer Zabdiel PazaranNo ratings yet
- Distribuciones Continuas NotablesDocument3 pagesDistribuciones Continuas Notablesmultifandom trashNo ratings yet
- DiplomadoDocument11 pagesDiplomadoLaura Alejandra Vergara CarrilloNo ratings yet
- Felipe Martinez Rizo - La Evaluacion en MexicoDocument33 pagesFelipe Martinez Rizo - La Evaluacion en MexicoRollin KentNo ratings yet
- Cuaderno de ActividadesDocument32 pagesCuaderno de ActividadesSH AbrilNo ratings yet
- Teoría de opciones y análisis de proyectos de inversiónDocument7 pagesTeoría de opciones y análisis de proyectos de inversiónCríspulo Lobo FNo ratings yet
- m3 y m4 Investigacion de MercadosDocument14 pagesm3 y m4 Investigacion de MercadosGaby GomezNo ratings yet