You might also like
- Advanced SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandAdvanced SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo ratings yet
- Performance Tuning OverviewDocument33 pagesPerformance Tuning Overviewmagi9999No ratings yet
- Base SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandBase SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo ratings yet
- Databricks DbutilsDocument34 pagesDatabricks DbutilsTarun SinghNo ratings yet
- SSIS Best PracticesDocument14 pagesSSIS Best PracticesmailtopvvkNo ratings yet
- SSIS FrameworkDocument53 pagesSSIS FrameworkMurali0% (1)
- ADF Blob To DataLake ConnectorDocument13 pagesADF Blob To DataLake ConnectorMaheswar ReddyNo ratings yet
- Ssis Data Type Cheat SheetDocument1 pageSsis Data Type Cheat SheetebtrainNo ratings yet
- SSISDocument7 pagesSSISSatish KumarNo ratings yet
- Understanding Business Intelligence:: ETL and Data Mart Best PracticesDocument20 pagesUnderstanding Business Intelligence:: ETL and Data Mart Best PracticesurspandsNo ratings yet
- Performance TunningDocument23 pagesPerformance TunningJanardhan kengarNo ratings yet
- Vinaytech DWH FaqsDocument22 pagesVinaytech DWH FaqsPrabhakar PrabhuNo ratings yet
- PySpark NotesDocument29 pagesPySpark Notesabhishekanand20073509No ratings yet
- Presented By: Dr. Michel Mitri James Madison UniverisityDocument127 pagesPresented By: Dr. Michel Mitri James Madison UniverisityeduardomanriquezNo ratings yet
- Complete Reference To Informatica PDFDocument52 pagesComplete Reference To Informatica PDFpankaj311983100% (3)
- SSIS Best PracticesDocument13 pagesSSIS Best Practicesrvijaysubs_764835048No ratings yet
- Learn More About SQL Interview Questions-Ii: The Expert'S Voice in SQL ServerDocument12 pagesLearn More About SQL Interview Questions-Ii: The Expert'S Voice in SQL ServerShivam ..........No ratings yet
- Datastage-Job ParametersDocument4 pagesDatastage-Job Parametersmgangadhar_143No ratings yet
- Notes On Dimension and FactsDocument32 pagesNotes On Dimension and FactsVamsi KarthikNo ratings yet
- Data StageDocument5 pagesData StagebabjeereddyNo ratings yet
- General Questions of SQL SERVERDocument34 pagesGeneral Questions of SQL SERVERpuku90No ratings yet
- Cheat Sheet: SSAS BasicsDocument1 pageCheat Sheet: SSAS BasicsSatishNo ratings yet
- DS Special Characters For ScribeDocument10 pagesDS Special Characters For ScribedatastageresourceNo ratings yet
- SQL and PLSQLDocument189 pagesSQL and PLSQLAKASH JAISWALNo ratings yet
- What Is RDBMS (Relational Database Management System) ?Document54 pagesWhat Is RDBMS (Relational Database Management System) ?sreenivaasreddy4197No ratings yet
- Getting Started With SSISDocument60 pagesGetting Started With SSIScpaz_navarroNo ratings yet
- EDB High Availability Scalability v1.0Document23 pagesEDB High Availability Scalability v1.0Paohua ChuangNo ratings yet
- INFORMATICA-Performance TuningDocument21 pagesINFORMATICA-Performance Tuningsvprasad.t100% (9)
- SAS DI Interview QuestionsDocument3 pagesSAS DI Interview Questionsanujsydney50% (2)
- SAS Macro Workshop NotesDocument17 pagesSAS Macro Workshop NotesShanmukh PrashanthNo ratings yet
- Joe Sack Performance Troubleshooting With Wait StatsDocument56 pagesJoe Sack Performance Troubleshooting With Wait StatsAamöd ThakürNo ratings yet
- SSIS 2005 Hands On Training LabDocument53 pagesSSIS 2005 Hands On Training Labshanu_123No ratings yet
- Informatica ETL Beginner's Guide Informatica Tutorial EdurekaDocument40 pagesInformatica ETL Beginner's Guide Informatica Tutorial EdurekaAbhishek RaghuvanshiNo ratings yet
- Main - Page Integration Services (SSIS) : Transformation Description Examples of When Transformation Would Be UsedDocument5 pagesMain - Page Integration Services (SSIS) : Transformation Description Examples of When Transformation Would Be UsedSujit PatelNo ratings yet
- Data Lake AzureDocument290 pagesData Lake Azurelegionario15No ratings yet
- SQL 2008 DbaDocument314 pagesSQL 2008 Dbavaddesuresh100% (1)
- Basics On Creating SSIS PackagesDocument19 pagesBasics On Creating SSIS PackagesSatish BeuraNo ratings yet
- Create: Create, Alter, Truncate, Drop Rename Grant Revoke Select, Insert, Delete UpdateDocument11 pagesCreate: Create, Alter, Truncate, Drop Rename Grant Revoke Select, Insert, Delete UpdateAlexandrina LikovaNo ratings yet
- Teradata Basics Exam - Sample Question Set 1 (Answers in Italic Font)Document5 pagesTeradata Basics Exam - Sample Question Set 1 (Answers in Italic Font)Vishal GuptaNo ratings yet
- Oracle PLSQL ExamplesDocument33 pagesOracle PLSQL Examplesleninapps33No ratings yet
- Error Handling - Informatica B2B Data TransformationDocument14 pagesError Handling - Informatica B2B Data TransformationKuti Gopisetty100% (1)
- Informatica 9.x Course CurriculumDocument8 pagesInformatica 9.x Course CurriculumshilpadassNo ratings yet
- SQL Server Performance TuningDocument25 pagesSQL Server Performance TuningBang TrinhNo ratings yet
- PGSQL SQLsDocument9 pagesPGSQL SQLskishore_m_kNo ratings yet
- (SSIS) Expressions (PDFDrive)Document166 pages(SSIS) Expressions (PDFDrive)SsNo ratings yet
- Synapse Project DeckDocument196 pagesSynapse Project Deckmysites220No ratings yet
- SQL DBA MirroringDocument3 pagesSQL DBA MirroringRavi KumarNo ratings yet
- Teradata CVDocument4 pagesTeradata CVkavitha221No ratings yet
- SQLDocument77 pagesSQLVeera ReddyNo ratings yet
- DB12c Tuning New Features Alex Zaballa PDFDocument82 pagesDB12c Tuning New Features Alex Zaballa PDFGanesh KaralkarNo ratings yet
- Base SAS Interview QuestionsDocument14 pagesBase SAS Interview QuestionsDev NathNo ratings yet
- 70-765 ExamDocs PDFDocument235 pages70-765 ExamDocs PDFJuan Carlos Montoya MurilloNo ratings yet
- SSIS DeploymentDocument6 pagesSSIS DeploymentAditya JanardhanNo ratings yet
- Ssis Interview QuestionsDocument114 pagesSsis Interview Questionsmachi418No ratings yet
- Stored Procedure Transformation OverviewDocument21 pagesStored Procedure Transformation Overviewypraju100% (1)
- TeradataDocument7 pagesTeradatakamalmse066072No ratings yet
- JAIM InstructionsDocument11 pagesJAIM InstructionsAlphaRaj Mekapogu100% (1)
- A Science Lesson Plan Analysis Instrument For Formative and Summative Program Evaluation of A Teacher Education ProgramDocument31 pagesA Science Lesson Plan Analysis Instrument For Formative and Summative Program Evaluation of A Teacher Education ProgramTiara Kurnia KhoerunnisaNo ratings yet
- Normality in The Residual - Hossain Academy NoteDocument2 pagesNormality in The Residual - Hossain Academy NoteAbdullah KhatibNo ratings yet
- Role of Wickability On The Critical Heat Flux of Structured Superhydrophilic SurfacesDocument10 pagesRole of Wickability On The Critical Heat Flux of Structured Superhydrophilic Surfacesavi0341No ratings yet
- A Tribute To Fernando L. L. B. Carneiro (1913 - 2001)Document2 pagesA Tribute To Fernando L. L. B. Carneiro (1913 - 2001)Roberto Urrutia100% (1)
- AFDD 1-1 (2006) - Leadership and Force DevelopmentDocument82 pagesAFDD 1-1 (2006) - Leadership and Force Developmentncore_scribd100% (1)
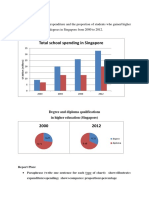
- Total School Spending in Singapore: Task 1 020219Document6 pagesTotal School Spending in Singapore: Task 1 020219viper_4554No ratings yet
- Career Tree EssayDocument2 pagesCareer Tree Essayapi-437674439No ratings yet
- My Home, My School: Meet and GreetDocument2 pagesMy Home, My School: Meet and GreetAcebuque Arby Immanuel GopeteoNo ratings yet
- Manufacturing Technology - Metrology: Dr.B.Ramamoorthy Professor Manufacturing Engg. Section Iitmadras 600 036Document22 pagesManufacturing Technology - Metrology: Dr.B.Ramamoorthy Professor Manufacturing Engg. Section Iitmadras 600 036Ramasubramanian KannanNo ratings yet
- Morning Report: Supervisor: Dr. H. Doddy Ak., Spog (K)Document10 pagesMorning Report: Supervisor: Dr. H. Doddy Ak., Spog (K)vika handayaniNo ratings yet
- D027B OmronDocument141 pagesD027B OmronirfanWPKNo ratings yet
- Fuzzy Ideals and Fuzzy Quasi-Ideals in Ternary Semirings: J. Kavikumar and Azme Bin KhamisDocument5 pagesFuzzy Ideals and Fuzzy Quasi-Ideals in Ternary Semirings: J. Kavikumar and Azme Bin KhamismsmramansrimathiNo ratings yet
- Kolkata City Accident Report - 2018Document48 pagesKolkata City Accident Report - 2018anon_109699702No ratings yet
- Raglio 2015 Effects of Music and Music Therapy On Mood in Neurological Patients PDFDocument12 pagesRaglio 2015 Effects of Music and Music Therapy On Mood in Neurological Patients PDFsimaso0% (1)
- DSpace Configuration PDFDocument1 pageDSpace Configuration PDFArshad SanwalNo ratings yet
- HCI Accross Border PaperDocument5 pagesHCI Accross Border PaperWaleed RiazNo ratings yet
- VGB-R 105 e ContentDocument7 pagesVGB-R 105 e Contentramnadh8031810% (2)
- OS Lab ManualDocument47 pagesOS Lab ManualNivedhithaVNo ratings yet
- EC861Document10 pagesEC861damaiNo ratings yet
- Specification of SGP InterlayerDocument3 pagesSpecification of SGP InterlayerHAN HANNo ratings yet
- EgoismDocument3 pagesEgoism123014stephenNo ratings yet
- Sop For RetailDocument13 pagesSop For Retailkarthika suresh100% (6)
- Affective DomainDocument3 pagesAffective DomainJm Enriquez Dela Cruz50% (2)
- Đề Thi Tham Khảo (Đề thi có 5 trang) : 6: The flood victims 7: Many 8Document7 pagesĐề Thi Tham Khảo (Đề thi có 5 trang) : 6: The flood victims 7: Many 8Quang Đặng HồngNo ratings yet
- Gpcdoc Gtds Shell Gadus s3 v460xd 2 (En) TdsDocument2 pagesGpcdoc Gtds Shell Gadus s3 v460xd 2 (En) TdsRoger ObregonNo ratings yet
- Mutants & Masterminds 1st Ed Character Generater (Xls Spreadsheet)Document89 pagesMutants & Masterminds 1st Ed Character Generater (Xls Spreadsheet)WesleyNo ratings yet
- Chapter 12 My Nursing Test BanksDocument10 pagesChapter 12 My Nursing Test Banksنمر نصار100% (1)
- PERFORM Toolkit 3 1 Release Notes 1.0 OnlinePDFDocument18 pagesPERFORM Toolkit 3 1 Release Notes 1.0 OnlinePDFJose HugoNo ratings yet
- The Saga of Flying Objects - La Saga de Los Objetos VoladoresDocument15 pagesThe Saga of Flying Objects - La Saga de Los Objetos VoladoresCiborgSeptiembreNo ratings yet