You might also like
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5795)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Audit Checklist For ISO 13485Document6 pagesAudit Checklist For ISO 13485EdNo ratings yet
- Audit Checklist For ISO 13485Document6 pagesAudit Checklist For ISO 13485EdNo ratings yet
- Tolerance Design Using Taguchi MethodsDocument30 pagesTolerance Design Using Taguchi MethodsEdNo ratings yet
- Short Run Statistical Process ControlDocument21 pagesShort Run Statistical Process ControlEdNo ratings yet
- Statistical Process Control FundamentalsDocument32 pagesStatistical Process Control FundamentalsEd100% (1)
- A Study of Q Chart For Short Run PDFDocument37 pagesA Study of Q Chart For Short Run PDFEd100% (1)
- Survival of The Fittest - The Process Control ImperativeDocument10 pagesSurvival of The Fittest - The Process Control ImperativeEdNo ratings yet
- Zed Charts Compare Apples and Oranges: Wheeler's WorkshopDocument4 pagesZed Charts Compare Apples and Oranges: Wheeler's WorkshopEdNo ratings yet
- 0.016 USL Process Is NOT StableDocument5 pages0.016 USL Process Is NOT StableEdNo ratings yet
- Applied Technology: by John J. Flaig, PH.DDocument2 pagesApplied Technology: by John J. Flaig, PH.DEdNo ratings yet
- Blind IdentDocument6 pagesBlind IdentEdNo ratings yet
- Quality Human Per ForDocument8 pagesQuality Human Per ForEdNo ratings yet
- Forecasting MethodsDocument30 pagesForecasting MethodsEdNo ratings yet
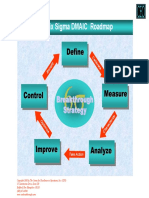
- The Six Sigma DMAIC Roadmap: DefineDocument1 pageThe Six Sigma DMAIC Roadmap: DefineEdNo ratings yet
- Entropy: Increasing The Discriminatory Power of DEA Using Shannon's EntropyDocument15 pagesEntropy: Increasing The Discriminatory Power of DEA Using Shannon's EntropyEdNo ratings yet
- Comparison Between Product Verification and TestingDocument1 pageComparison Between Product Verification and TestingEdNo ratings yet
- Lean Six Sigma Project Charter: Title: Reduce Scrapped Cookies in NW Region BB/GB: B. ThorntonDocument2 pagesLean Six Sigma Project Charter: Title: Reduce Scrapped Cookies in NW Region BB/GB: B. ThorntonEdNo ratings yet
- LSS Final - Report - TemplateDocument9 pagesLSS Final - Report - TemplateEdNo ratings yet
- ApqpDocument11 pagesApqpEdNo ratings yet
- SPC For Correlated Variables PDFDocument15 pagesSPC For Correlated Variables PDFEdNo ratings yet
- Social Dimensions of ComputerisationDocument6 pagesSocial Dimensions of Computerisationgourav rathore100% (1)
- Math Lecture 1Document37 pagesMath Lecture 1Mohamed A. TaherNo ratings yet
- Accurately Solving Postbuckling Composite Stiffened Panels in Marc and MSC Nastran Sol 106Document4 pagesAccurately Solving Postbuckling Composite Stiffened Panels in Marc and MSC Nastran Sol 106IJNo ratings yet
- Sharmila Podder - Cv.newDocument2 pagesSharmila Podder - Cv.newMustafa Hussain100% (3)
- Blueprint - SOP - Target PagesDocument3 pagesBlueprint - SOP - Target PagesKen CarrollNo ratings yet
- Ideapad 330 15intel Platform SpecificationsDocument1 pageIdeapad 330 15intel Platform Specificationslegatus2yahoo.grNo ratings yet
- 01 - Cisco ISE Profiling Reporting - Part 1Document1 page01 - Cisco ISE Profiling Reporting - Part 1Nguyen LeNo ratings yet
- Sag Tension (ACCC Casablanca)Document2 pagesSag Tension (ACCC Casablanca)Subodh SontakkeNo ratings yet
- Service Manual: ChassisDocument66 pagesService Manual: ChassisAsnake TegenawNo ratings yet
- DESI GIShomework 4 ExcDocument7 pagesDESI GIShomework 4 ExcAndrea HuertaNo ratings yet
- ForestDocument2 pagesForestZINEB LAHYANo ratings yet
- Radio Trimble Trimark 3Document2 pagesRadio Trimble Trimark 3Robinson VargasNo ratings yet
- Crisp and ClearDocument5 pagesCrisp and ClearsandeepNo ratings yet
- Front End Performance ChecklistDocument11 pagesFront End Performance ChecklistKevinNo ratings yet
- The Use of Simulation in The Design of Milk-Run Intralogistics SystemsDocument6 pagesThe Use of Simulation in The Design of Milk-Run Intralogistics SystemsSoufiane AbdellaouiNo ratings yet
- BU R&D Form 1 - Detailed R&D Program or Project ProposalDocument2 pagesBU R&D Form 1 - Detailed R&D Program or Project ProposalOween SamsonNo ratings yet
- An Acknowledgement LetterDocument1 pageAn Acknowledgement LetterGovindan PerumalNo ratings yet
- Female Cordset: ADOAH040VAS0002E04Document2 pagesFemale Cordset: ADOAH040VAS0002E04Sujata KulkarniNo ratings yet
- Lic Unit 1 (1) eDocument114 pagesLic Unit 1 (1) eganeshNo ratings yet
- DSJ LicenseDocument7 pagesDSJ LicenseFernando Fernandes NeriNo ratings yet
- FoST 2018 Final-Chapter 2Document39 pagesFoST 2018 Final-Chapter 2Jelena RakicNo ratings yet
- 10b - Crime-Mapping Technology in The Philippines..2-Crime Mapping in The Philippines-2015febDocument5 pages10b - Crime-Mapping Technology in The Philippines..2-Crime Mapping in The Philippines-2015febGesler Pilvan SainNo ratings yet
- Application Form: Full Name ID Card Number Date of Birth Sex Address Phone Number EmailDocument3 pagesApplication Form: Full Name ID Card Number Date of Birth Sex Address Phone Number EmailesadisaNo ratings yet
- BJT Fixed BiasDocument18 pagesBJT Fixed Biasbetteralwz100% (4)
- Agc 150 Designers Handbook 4189341188 UkDocument398 pagesAgc 150 Designers Handbook 4189341188 UkMaicon ZagonelNo ratings yet
- CAPE 3320 & 5330M Advanced/ Reaction Engineering: Executive SummaryDocument19 pagesCAPE 3320 & 5330M Advanced/ Reaction Engineering: Executive SummaryMeireza Ajeng PratiwiNo ratings yet
- Elipar 3m in Healthcare, Lab, and Life Science Equipment Search Result EbayDocument1 pageElipar 3m in Healthcare, Lab, and Life Science Equipment Search Result EbayABRAHAM LEONARDO PAZ GUZMANNo ratings yet
- DELL Latitude D420 COMPAL LA-3071P Rev 1.0 SchematicsDocument59 pagesDELL Latitude D420 COMPAL LA-3071P Rev 1.0 SchematicsviniciusvbfNo ratings yet
- G Codes and M CodesDocument10 pagesG Codes and M CodesHarsh YadavNo ratings yet
- X4029960-301 - Bus Riser+UTX - R01Document15 pagesX4029960-301 - Bus Riser+UTX - R01MUH ILHAM MARZUKINo ratings yet