You might also like
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Zed Charts Compare Apples and Oranges: Wheeler's WorkshopDocument4 pagesZed Charts Compare Apples and Oranges: Wheeler's WorkshopEdNo ratings yet
- Survival of The Fittest - The Process Control ImperativeDocument10 pagesSurvival of The Fittest - The Process Control ImperativeEdNo ratings yet
- 0.016 USL Process Is NOT StableDocument5 pages0.016 USL Process Is NOT StableEdNo ratings yet
- Applied Technology: by John J. Flaig, PH.DDocument2 pagesApplied Technology: by John J. Flaig, PH.DEdNo ratings yet
- Quality Human Per ForDocument8 pagesQuality Human Per ForEdNo ratings yet
- Blind IdentDocument6 pagesBlind IdentEdNo ratings yet
- Audit Checklist For ISO 13485Document6 pagesAudit Checklist For ISO 13485EdNo ratings yet
- Entropy: Increasing The Discriminatory Power of DEA Using Shannon's EntropyDocument15 pagesEntropy: Increasing The Discriminatory Power of DEA Using Shannon's EntropyEdNo ratings yet
- A Study of Q Chart For Short Run PDFDocument37 pagesA Study of Q Chart For Short Run PDFEd100% (1)
- Short Run Statistical Process ControlDocument21 pagesShort Run Statistical Process ControlEdNo ratings yet
- Forecasting MethodsDocument30 pagesForecasting MethodsEdNo ratings yet
- Statistical Process Control FundamentalsDocument32 pagesStatistical Process Control FundamentalsEd100% (1)
- Tolerance Design Using Taguchi MethodsDocument30 pagesTolerance Design Using Taguchi MethodsEdNo ratings yet
- Audit Checklist For ISO 13485Document6 pagesAudit Checklist For ISO 13485EdNo ratings yet
- LSS Final - Report - TemplateDocument9 pagesLSS Final - Report - TemplateEdNo ratings yet
- Lean Six Sigma Project Charter: Title: Reduce Scrapped Cookies in NW Region BB/GB: B. ThorntonDocument2 pagesLean Six Sigma Project Charter: Title: Reduce Scrapped Cookies in NW Region BB/GB: B. ThorntonEdNo ratings yet
- Comparison Between Product Verification and TestingDocument1 pageComparison Between Product Verification and TestingEdNo ratings yet
- SPC For Correlated Variables PDFDocument15 pagesSPC For Correlated Variables PDFEdNo ratings yet
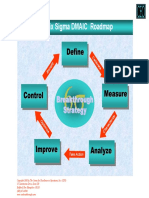
- The Six Sigma DMAIC Roadmap: DefineDocument1 pageThe Six Sigma DMAIC Roadmap: DefineEdNo ratings yet
- ApqpDocument11 pagesApqpEdNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Course Outline ReviewerDocument12 pagesCourse Outline Reviewerjmd.besanaNo ratings yet
- Manual de Partes Dm45-50-lDocument690 pagesManual de Partes Dm45-50-lklausNo ratings yet
- TDS - Total - Carter 68 - Wyh - 202201 - en - IdnDocument1 pageTDS - Total - Carter 68 - Wyh - 202201 - en - IdnAnya J PamungkasNo ratings yet
- Diagrama Electronico EGED 285Document2 pagesDiagrama Electronico EGED 285Carlos Juarez Chunga100% (1)
- 99990353-Wsi4-2 C1D2-7940022562 7950022563 7940022564Document2 pages99990353-Wsi4-2 C1D2-7940022562 7950022563 7940022564alltheloveintheworldNo ratings yet
- Analyzing Sri Lankan Ceramic IndustryDocument18 pagesAnalyzing Sri Lankan Ceramic Industryrasithapradeep50% (4)
- Position PaperDocument9 pagesPosition PaperRoel PalmairaNo ratings yet
- Latest Eassy Writing Topics For PracticeDocument18 pagesLatest Eassy Writing Topics For PracticeAnjani Kumar RaiNo ratings yet
- DX DiagDocument16 pagesDX DiagMihaela AndronacheNo ratings yet
- Engineer Noor Ahmad CVDocument5 pagesEngineer Noor Ahmad CVSayed WafiNo ratings yet
- Social Media Engagement and Feedback CycleDocument10 pagesSocial Media Engagement and Feedback Cyclerichard martinNo ratings yet
- ANSYS 14.0 Fluid Dynamics Update - Dipankar ChoudhuryDocument87 pagesANSYS 14.0 Fluid Dynamics Update - Dipankar Choudhuryj_c_garcia_d100% (1)
- C++ & Object Oriented Programming: Dr. Alekha Kumar MishraDocument23 pagesC++ & Object Oriented Programming: Dr. Alekha Kumar MishraPriyanshu Kumar KeshriNo ratings yet
- BS 7346-6-2005 Specifications For Cable SystemsDocument26 pagesBS 7346-6-2005 Specifications For Cable SystemsFathyNo ratings yet
- 1962 BEECHCRAFT P35 Bonanza - Specifications, Performance, Operating Cost, Valuation, BrokersDocument12 pages1962 BEECHCRAFT P35 Bonanza - Specifications, Performance, Operating Cost, Valuation, BrokersRichard LundNo ratings yet
- Hey Can I Try ThatDocument20 pagesHey Can I Try Thatapi-273078602No ratings yet
- NDA For Consultants Template-1Document4 pagesNDA For Consultants Template-1David Jay Mor100% (1)
- Uncertainty-Based Production Scheduling in Open Pit Mining: R. Dimitrakopoulos and S. RamazanDocument7 pagesUncertainty-Based Production Scheduling in Open Pit Mining: R. Dimitrakopoulos and S. RamazanClaudio AballayNo ratings yet
- Katalog Bonnier BooksDocument45 pagesKatalog Bonnier BooksghitahirataNo ratings yet
- Appraisal: From Theory To Practice: Stefano Stanghellini Pierluigi Morano Marta Bottero Alessandra Oppio EditorsDocument342 pagesAppraisal: From Theory To Practice: Stefano Stanghellini Pierluigi Morano Marta Bottero Alessandra Oppio EditorsMohamed MoussaNo ratings yet
- NATIONAL DEVELOPMENT COMPANY v. CADocument11 pagesNATIONAL DEVELOPMENT COMPANY v. CAAndrei Anne PalomarNo ratings yet
- Bangalore University: Regulations, Scheme and SyllabusDocument40 pagesBangalore University: Regulations, Scheme and SyllabusYashaswiniPrashanthNo ratings yet
- DoctorTecar Brochure MECTRONIC2016 EngDocument16 pagesDoctorTecar Brochure MECTRONIC2016 EngSergio OlivaNo ratings yet
- Cassava Starch Granule Structure-Function Properties - Influence of Time and Conditions at Harvest On Four Cultivars of Cassava StarchDocument10 pagesCassava Starch Granule Structure-Function Properties - Influence of Time and Conditions at Harvest On Four Cultivars of Cassava Starchwahyuthp43No ratings yet
- Affidavit To Use The Surname of The FatherDocument2 pagesAffidavit To Use The Surname of The FatherGlenn Lapitan Carpena100% (1)
- In The High Court of Delhi at New DelhiDocument3 pagesIn The High Court of Delhi at New DelhiSundaram OjhaNo ratings yet
- MockboardexamDocument13 pagesMockboardexamJayke TanNo ratings yet
- Válvula DireccionalDocument30 pagesVálvula DireccionalDiego DuranNo ratings yet
- Feeding Pipe 2'' L 20m: General Plan Al-Sabaeen Pv-Diesel SystemDocument3 pagesFeeding Pipe 2'' L 20m: General Plan Al-Sabaeen Pv-Diesel Systemمحمد الحديNo ratings yet
- IllustratorDocument27 pagesIllustratorVinti MalikNo ratings yet