You might also like
- Asus Aio V200ibuk-Bc044mDocument2 pagesAsus Aio V200ibuk-Bc044mAbdi Juragan RusdyantoNo ratings yet
- Jl. Raya Palabuan - Jabong: TimurDocument1 pageJl. Raya Palabuan - Jabong: TimurAbdi Juragan RusdyantoNo ratings yet
- File Exchange - MATLAB CentralDocument2 pagesFile Exchange - MATLAB CentralAbdi Juragan RusdyantoNo ratings yet
- Fuzzy Logic Toolbox Documentation AppDocument1 pageFuzzy Logic Toolbox Documentation AppAbdi Juragan RusdyantoNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Factors: How Time and Interest Affect Money: Solutions To End-Of-Chapter ProblemsDocument12 pagesFactors: How Time and Interest Affect Money: Solutions To End-Of-Chapter ProblemsMusa'b84% (19)
- Set - TheoryDocument2 pagesSet - TheoryAhanna PariNo ratings yet
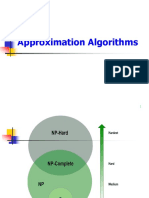
- IT257 DAA Approximation AlgorithmsDocument55 pagesIT257 DAA Approximation AlgorithmsSimhadri SevithaNo ratings yet
- Controltheory PDFDocument45 pagesControltheory PDFFiaz KhanNo ratings yet
- Extracted Pages From 250 Problems in Elementary Number Theory - Sierpinski (1970)Document51 pagesExtracted Pages From 250 Problems in Elementary Number Theory - Sierpinski (1970)Pham Thi Thanh ThuyNo ratings yet
- Digital Control Systems (Elective) : Suggested ReadingDocument1 pageDigital Control Systems (Elective) : Suggested ReadingBebo DiaNo ratings yet
- UCE Book 3Document165 pagesUCE Book 3Anonymous elACfG100% (3)
- V X V Has A Unique Expansion X C V V: DR Scott Morrison (ANU) MATH1014 NotesDocument10 pagesV X V Has A Unique Expansion X C V V: DR Scott Morrison (ANU) MATH1014 NotesKimondo KingNo ratings yet
- 2.8 Notes Rolle's Theorem and The Mean Value Theorem (MVT)Document2 pages2.8 Notes Rolle's Theorem and The Mean Value Theorem (MVT)ratna777No ratings yet
- Nested Radical RecursionsDocument4 pagesNested Radical RecursionsJacob RicheyNo ratings yet
- Periodic Functions 8 PDFDocument12 pagesPeriodic Functions 8 PDFAkashNo ratings yet
- Dijkstra AlgorithmDocument13 pagesDijkstra AlgorithmLucasNo ratings yet
- 12limits NotesDocument17 pages12limits NotesAulia Diva Muthiah YudaNo ratings yet
- 7 Let Number Theory - pdf10Document8 pages7 Let Number Theory - pdf10novey_casioNo ratings yet
- Martin Haenggi - Stochastic Geometry For Wireless Networks PDFDocument332 pagesMartin Haenggi - Stochastic Geometry For Wireless Networks PDFSlaheddineNo ratings yet
- Manual For Instructors: TO Linear Algebra Fifth EditionDocument9 pagesManual For Instructors: TO Linear Algebra Fifth EditioncemreNo ratings yet
- Linear Algebra EB/BE 104: by Dr. Shaimaa Y. AbdelkaderDocument23 pagesLinear Algebra EB/BE 104: by Dr. Shaimaa Y. AbdelkaderAhmed M. RezkNo ratings yet
- C I A (. - 2016/2017) Prof. E. Giunchiglia, A. Tacchella (27 June 2017)Document11 pagesC I A (. - 2016/2017) Prof. E. Giunchiglia, A. Tacchella (27 June 2017)Josep Rueda CollellNo ratings yet
- Amurt Academy, ItahariDocument2 pagesAmurt Academy, ItahariDeepak BhattaraiNo ratings yet
- Gzbclassvi07022024111115 0Document5 pagesGzbclassvi07022024111115 0cyberclub.jsNo ratings yet
- Chapter 4. Sampling of Continuous-Time SignalsDocument66 pagesChapter 4. Sampling of Continuous-Time Signalsmkmkmkmk2No ratings yet
- Cpe111 Ultimate Mother SauceDocument48 pagesCpe111 Ultimate Mother SauceBlank BlankNo ratings yet
- SIM Quadratic Equation by SquareDocument40 pagesSIM Quadratic Equation by SquareRochelle AdlaoNo ratings yet
- Calculator TechniquesDocument23 pagesCalculator TechniquesVilly Joe CamayraNo ratings yet
- Mae 456 Finite Element Analysis EXAM 1 Practice Questions NameDocument13 pagesMae 456 Finite Element Analysis EXAM 1 Practice Questions Namechellamv100% (1)
- Introduction To Graphs: Discrete Structures For Computing On November 24, 2021Document81 pagesIntroduction To Graphs: Discrete Structures For Computing On November 24, 2021Đình ĐứcNo ratings yet
- MT 1112: Calculus: IntegralsDocument23 pagesMT 1112: Calculus: IntegralsJustin WilliamNo ratings yet
- Linear Systems Final Exam Formula SheetDocument4 pagesLinear Systems Final Exam Formula SheetmrdantownsendNo ratings yet
- Bisimilarity and Hennessy-Milner Logic: Luca Aceto ICE-TCS, School of Computer Science, Reykjavik UniversityDocument45 pagesBisimilarity and Hennessy-Milner Logic: Luca Aceto ICE-TCS, School of Computer Science, Reykjavik UniversityEdge123123No ratings yet
- P2 MT (Abr)Document5 pagesP2 MT (Abr)Syawal QadriNo ratings yet