You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- VSR Trans. PPT3Document16 pagesVSR Trans. PPT3VSR TRANSNo ratings yet
- PTN Guide Compilation by EmeraldchowDocument24 pagesPTN Guide Compilation by EmeraldchowMirzaNo ratings yet
- NIELIT Recruitment For Scientist and Technical Assistants 2017 Official NotificationDocument6 pagesNIELIT Recruitment For Scientist and Technical Assistants 2017 Official NotificationKshitija100% (1)
- Capital Budgeting and Capital Budgeting and Risk Analysis Risk AnalysisDocument16 pagesCapital Budgeting and Capital Budgeting and Risk Analysis Risk AnalysisHaris FendiarNo ratings yet
- Barriers of CommunicationDocument5 pagesBarriers of CommunicationIVY YBAÑEZNo ratings yet
- Rivers and Their Origin (Top MCQ)Document24 pagesRivers and Their Origin (Top MCQ)Anil Yadav100% (1)
- Automatic Control ExercisesDocument183 pagesAutomatic Control ExercisesFrancesco Vasturzo100% (1)
- Delonghi Pinguino Water To Air Pac We125 Instruction Manual 715678Document21 pagesDelonghi Pinguino Water To Air Pac We125 Instruction Manual 715678Luis AlbertoAlmeidaSilva100% (1)
- Compressor-Less: Historical ApplicationsDocument70 pagesCompressor-Less: Historical Applicationssuryakantshrotriya100% (1)
- Dimensions and Methodology of Business Studies Dec 2018Document2 pagesDimensions and Methodology of Business Studies Dec 2018Nallavenaaya Unni100% (1)
- 1:100 Scale: SPACE-X "Crew Dragon 2" Demo Mission-1 CapsuleDocument9 pages1:100 Scale: SPACE-X "Crew Dragon 2" Demo Mission-1 CapsuleBearium YTNo ratings yet
- PC-ABS Bayblend FR3010Document4 pagesPC-ABS Bayblend FR3010countzeroaslNo ratings yet
- Contractor Hse Management ProgramDocument12 pagesContractor Hse Management ProgramAhmed IbrahimNo ratings yet
- Summative 1Document4 pagesSummative 1Nean YsabelleNo ratings yet
- Analisa AgriculturalDocument6 pagesAnalisa AgriculturalFEBRINA SARLINDA, STNo ratings yet
- Iit JeeDocument8 pagesIit JeeRNo ratings yet
- Validation For A Login PageDocument2 pagesValidation For A Login PageAmal RajNo ratings yet
- Structure and Operation: 3. Electronic Control Unit Connection DiagramDocument16 pagesStructure and Operation: 3. Electronic Control Unit Connection DiagramAung Hlaing Min MyanmarNo ratings yet
- 01.introduction To Earth ScienceDocument29 pages01.introduction To Earth ScienceIshan Chua100% (1)
- Executive Summary Report Julio13Document8 pagesExecutive Summary Report Julio13exxgineNo ratings yet
- Introduction To Rhetorical Analysis: Week 1Document16 pagesIntroduction To Rhetorical Analysis: Week 1Will KurlinkusNo ratings yet
- UnitPlan (P.E) Grade 6Document13 pagesUnitPlan (P.E) Grade 6Lou At CamellaNo ratings yet
- John Hopkins Evidence Table - Systematic ReviewDocument2 pagesJohn Hopkins Evidence Table - Systematic Reviewsandy ThylsNo ratings yet
- G20 SolutionDocument11 pagesG20 SolutionAbidemi Benjamen AttehNo ratings yet
- 12 ĀnurũpyenaDocument7 pages12 ĀnurũpyenashuklahouseNo ratings yet
- Silenat Berhanu SimaDocument6 pagesSilenat Berhanu SimaSilenat BerhanuNo ratings yet
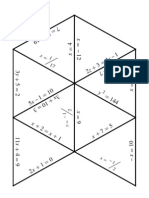
- Algebra1 Review PuzzleDocument3 pagesAlgebra1 Review PuzzleNicholas Yates100% (1)
- Is There Any Way To Download The Whole Package of Asphalt 8 Airborne So That I Can Install It On Any Android Device Without An Internet Connection - QuoraDocument4 pagesIs There Any Way To Download The Whole Package of Asphalt 8 Airborne So That I Can Install It On Any Android Device Without An Internet Connection - QuoraMounir2105No ratings yet
- PP in Ii 001Document15 pagesPP in Ii 001Dav EipNo ratings yet
- The Extension Delivery SystemDocument10 pagesThe Extension Delivery SystemApril Jay Abacial IINo ratings yet