You might also like
- NumPY ArrayDocument8 pagesNumPY ArrayerivaldomnNo ratings yet
- The NumPy Array - A Structure For Efficient Numerical ComputationDocument9 pagesThe NumPy Array - A Structure For Efficient Numerical ComputationDaniel Camarena PerezNo ratings yet
- DS Unit 3 Part 1Document27 pagesDS Unit 3 Part 1mounika narraNo ratings yet
- NumPy NotesDocument13 pagesNumPy Notessiddhant bhandariNo ratings yet
- FDS Unit 4Document66 pagesFDS Unit 4shaliniboddu521No ratings yet
- Cs3361 Data Science LaboratoryDocument139 pagesCs3361 Data Science LaboratorykarthickamsecNo ratings yet
- Ch14.A Simple Guide To MatplotlibDocument16 pagesCh14.A Simple Guide To MatplotlibsamiluNo ratings yet
- NumpyDocument10 pagesNumpyXY ZWNo ratings yet
- CS204-lec01 - Intro, Array, Array ListDocument21 pagesCS204-lec01 - Intro, Array, Array Listanasmajeed2627No ratings yet
- Lab-3 AIDocument21 pagesLab-3 AIprincezaid2013No ratings yet
- Articulo 1 - The NumPyDocument9 pagesArticulo 1 - The NumPyRenato MartinezNo ratings yet
- NumpyDocument44 pagesNumpySaif JuttNo ratings yet
- Data Structures: Steven SkienaDocument25 pagesData Structures: Steven SkienaPusat Tuisyen Bestari IlmuNo ratings yet
- Python Solve CAT2Document17 pagesPython Solve CAT2Er Sachin ShandilyaNo ratings yet
- HUAWEI - 04 Third-Party LibrariesDocument59 pagesHUAWEI - 04 Third-Party LibrariesPierpaolo VergatiNo ratings yet
- Experiment 4: University of Engineering and Technology, TaxilaDocument5 pagesExperiment 4: University of Engineering and Technology, TaxilaAfras AhmadNo ratings yet
- Numpy NotesDocument170 pagesNumpy NotesCayden James100% (1)
- Re Sizable ArraysDocument12 pagesRe Sizable ArraysSeraphina NixNo ratings yet
- Python DataStructure QuestionDocument12 pagesPython DataStructure QuestionAarav HarithasNo ratings yet
- GNU Octave - Matrix ManipulationDocument7 pagesGNU Octave - Matrix ManipulationpratibhahegdeNo ratings yet
- Cs3353 Fds Unit 4 Notes EduenggDocument44 pagesCs3353 Fds Unit 4 Notes EduenggGanesh KumarNo ratings yet
- Experiment 4: University of Engineering and Technology, TaxilaDocument5 pagesExperiment 4: University of Engineering and Technology, TaxilaEza MughalNo ratings yet
- How Do I Install Numpy?: Numpy Array: Numpy Array Is A Powerful N-Dimensional Array Object Which Is in The Form of RowsDocument3 pagesHow Do I Install Numpy?: Numpy Array: Numpy Array Is A Powerful N-Dimensional Array Object Which Is in The Form of RowsNishanthNo ratings yet
- Computer Programming For Engineering ApplicationsDocument34 pagesComputer Programming For Engineering Applicationsvincent xuNo ratings yet
- Assignment DSDocument34 pagesAssignment DSPrasadaRaoNo ratings yet
- Better External Memory Suffix Array Construction: Roman Dementiev, Juha K Arkk Ainen, Jens Mehnert, Peter SandersDocument12 pagesBetter External Memory Suffix Array Construction: Roman Dementiev, Juha K Arkk Ainen, Jens Mehnert, Peter Sandersmanuelq9No ratings yet
- Lec 02-04 Ch2 Numpy Part 1Document66 pagesLec 02-04 Ch2 Numpy Part 1MAryam KhanNo ratings yet
- SHS DataStruct Module ICT-12-ReviewerDocument5 pagesSHS DataStruct Module ICT-12-ReviewerJair Valdez - ICT Programming 12No ratings yet
- NumPy & PandasDocument27 pagesNumPy & PandasPavan DevaNo ratings yet
- Two Dimensoinal ArrayDocument10 pagesTwo Dimensoinal Arraybenmajed82No ratings yet
- A Visual Intro To Numpy and Data RepresentationDocument16 pagesA Visual Intro To Numpy and Data RepresentationPallab PuriNo ratings yet
- NumpyDocument50 pagesNumpysailushaNo ratings yet
- 01 02 04 NITK Python TutorialDocument47 pages01 02 04 NITK Python TutorialmedsinofficialNo ratings yet
- Math10282 Ex03 - An R SessionDocument10 pagesMath10282 Ex03 - An R SessiondeimanteNo ratings yet
- 1D, 2D and Multi-Dimensional Arrays - ComputerSC PDFDocument49 pages1D, 2D and Multi-Dimensional Arrays - ComputerSC PDFParamartha BanerjeeNo ratings yet
- What Is A Data Structure?: Data Structures in Data ScienceDocument24 pagesWhat Is A Data Structure?: Data Structures in Data ScienceMeghna ChoudharyNo ratings yet
- Chunking of Large Multidimensional ArraysDocument19 pagesChunking of Large Multidimensional ArraysvksunitaNo ratings yet
- Arrays: Matrix and Array OperationsDocument5 pagesArrays: Matrix and Array Operationsdivine iyawaNo ratings yet
- Machine Learning LibrariesDocument38 pagesMachine Learning LibrariesHemraj Patel BhuriNo ratings yet
- Python AbstractDocument7 pagesPython AbstractShambhavi BiradarNo ratings yet
- Chapter 4Document47 pagesChapter 4vishal kumar oadNo ratings yet
- Hashing ReadingDocument10 pagesHashing Reading16bec102No ratings yet
- GProg Python 6-PrintDocument14 pagesGProg Python 6-PrintneverwolfNo ratings yet
- Arrays: A. Answer The Following Questions: AnsDocument56 pagesArrays: A. Answer The Following Questions: AnsmdsNo ratings yet
- Week 9Document27 pagesWeek 9Betül ÖztürkNo ratings yet
- Xii Informatics Practices Chap 4Document10 pagesXii Informatics Practices Chap 4Shaurya GargNo ratings yet
- Numpy in Visually Appealing MannerDocument12 pagesNumpy in Visually Appealing MannerSowrya ReganaNo ratings yet
- Arrays and StringsDocument38 pagesArrays and Stringsaryan86yaNo ratings yet
- Unit - VDocument75 pagesUnit - Vgokul100% (1)
- LAB ManualDocument99 pagesLAB ManualRohit ChaharNo ratings yet
- MatricesDocument6 pagesMatricesOntime BestwritersNo ratings yet
- Assignment 2Document5 pagesAssignment 2Nguyễn Văn NhậtNo ratings yet
- Assignment 2 With ProgramDocument8 pagesAssignment 2 With ProgramPalash SarowareNo ratings yet
- Lecture No.0001 Data Structures & AlgorithmsDocument52 pagesLecture No.0001 Data Structures & AlgorithmsAsif SaeedNo ratings yet
- 19cs2205a KeyDocument8 pages19cs2205a KeySuryateja KokaNo ratings yet
- Group 1 Array: Picture of An ArrayDocument13 pagesGroup 1 Array: Picture of An ArrayNivlem B ArerbagNo ratings yet
- KOS1110 Python - Introduction To Plotting: 1. Getting Started - What Do You Need?Document8 pagesKOS1110 Python - Introduction To Plotting: 1. Getting Started - What Do You Need?Syuhada AhmadNo ratings yet
- Handson-Ml - Tools - Matplotlib - Ipynb at 265099f9 Ageron - Handson-Ml GitHubDocument33 pagesHandson-Ml - Tools - Matplotlib - Ipynb at 265099f9 Ageron - Handson-Ml GitHubRaFaT HaQNo ratings yet
- Lecture 1: Brief Overview - PAC LearningDocument3 pagesLecture 1: Brief Overview - PAC LearningChitradeep Dutta RoyNo ratings yet
- 133A TextbookDocument348 pages133A TextbookChitradeep Dutta RoyNo ratings yet
- 10-601 Machine LearningDocument7 pages10-601 Machine LearningChitradeep Dutta RoyNo ratings yet
- NetworksDocument75 pagesNetworksChitradeep Dutta RoyNo ratings yet
- Quick Tour of Linear Algebra and Graph TheoryDocument27 pagesQuick Tour of Linear Algebra and Graph TheoryChitradeep Dutta RoyNo ratings yet
- YellowstoneDocument2 pagesYellowstoneChitradeep Dutta RoyNo ratings yet
- Pigeonhole Principle and The Probabilistic Method: Same BirthdayDocument9 pagesPigeonhole Principle and The Probabilistic Method: Same BirthdayChitradeep Dutta RoyNo ratings yet
- Dynamic Programming For Graphs On Surfaces: Juanjo Ru E Ignasi Sau Dimitrios M. ThilikosDocument26 pagesDynamic Programming For Graphs On Surfaces: Juanjo Ru E Ignasi Sau Dimitrios M. ThilikosChitradeep Dutta RoyNo ratings yet
- Git & Github: Basics of Distributed Version ControlDocument44 pagesGit & Github: Basics of Distributed Version ControlChitradeep Dutta RoyNo ratings yet
- Scan APIDocument183 pagesScan APIChitradeep Dutta RoyNo ratings yet
- Differential Evolution: A Survey of The State-of-the-Art: Swagatam Das, and Ponnuthurai Nagaratnam SuganthanDocument41 pagesDifferential Evolution: A Survey of The State-of-the-Art: Swagatam Das, and Ponnuthurai Nagaratnam SuganthanChitradeep Dutta RoyNo ratings yet
- Intro To Probability - U of UDocument269 pagesIntro To Probability - U of UChris WhitingNo ratings yet
- Neanderthal JHE 2004Document21 pagesNeanderthal JHE 2004Chitradeep Dutta RoyNo ratings yet
- Towards Patient-Specific Treatment:: Medical Applications of Machine LearningDocument22 pagesTowards Patient-Specific Treatment:: Medical Applications of Machine LearningChitradeep Dutta RoyNo ratings yet
- HW 6Document3 pagesHW 6Chitradeep Dutta RoyNo ratings yet
- Paul Yiu - Introduction To Triangle GeometryDocument160 pagesPaul Yiu - Introduction To Triangle GeometryGy SzNo ratings yet
- XV6, A Simple, Unix-Like Teaching Operating System (Book)Document92 pagesXV6, A Simple, Unix-Like Teaching Operating System (Book)gitsNo ratings yet
- Python Basics: The Crash CourseDocument14 pagesPython Basics: The Crash CourseSrinivas BijigiriNo ratings yet
- Nim On GraphDocument46 pagesNim On GraphManas MaheshwariNo ratings yet
- Red Hat Enterprise Linux-6-6.8 Release Notes-En-UsDocument65 pagesRed Hat Enterprise Linux-6-6.8 Release Notes-En-Uskamel najjarNo ratings yet
- Idoc Error Handling For Everyone: How It WorksDocument2 pagesIdoc Error Handling For Everyone: How It WorksSudheer KumarNo ratings yet
- CSEC Information Technology June 2015 P02Document18 pagesCSEC Information Technology June 2015 P02SiennaNo ratings yet
- Block Diagram and Signal Flow GraphDocument15 pagesBlock Diagram and Signal Flow GraphAngelus Vincent GuilalasNo ratings yet
- Problem Set No.2 SolutionDocument9 pagesProblem Set No.2 SolutionAshley Quinn MorganNo ratings yet
- APEX Student GuideDocument17 pagesAPEX Student GuideYode Arliando100% (2)
- Elb AgDocument117 pagesElb AgniravNo ratings yet
- FortiOS v4.0 MR3 Patch Release 11 Release NotesDocument31 pagesFortiOS v4.0 MR3 Patch Release 11 Release NotesmonsieurkozoNo ratings yet
- Computer Integrated ManufacturingDocument2 pagesComputer Integrated ManufacturingDhiren Patel100% (1)
- Symbol Master Multi-Pass Symbolic Disassembler Manual V2.0 (Feb 2 1986)Document68 pagesSymbol Master Multi-Pass Symbolic Disassembler Manual V2.0 (Feb 2 1986)weirdocolectorNo ratings yet
- DP Sound Conexant 14062 DriversDocument242 pagesDP Sound Conexant 14062 DriversRamesh BabuNo ratings yet
- WosaDocument23 pagesWosadoeaccNo ratings yet
- Design and Implementation The LLC Resonant TransformerDocument3 pagesDesign and Implementation The LLC Resonant TransformerMathe ZsoltNo ratings yet
- Introduction To Internet: Definition, History of Internet, Functions, Different ServicesDocument20 pagesIntroduction To Internet: Definition, History of Internet, Functions, Different ServicesMoonlight LotusNo ratings yet
- CV-Sushil GuptaDocument3 pagesCV-Sushil Guptaanurag_bahety6067No ratings yet
- 3 - DHCP and Wireless Basic SecurityDocument3 pages3 - DHCP and Wireless Basic SecurityDmddldldldlNo ratings yet
- Question Bank - Module 1 and Module 2Document3 pagesQuestion Bank - Module 1 and Module 2Manasha DeviNo ratings yet
- B Cisco Nexus 9000 Series NX-OS System Management Configuration Guide 7x Chapter 011100Document16 pagesB Cisco Nexus 9000 Series NX-OS System Management Configuration Guide 7x Chapter 011100RiyanSahaNo ratings yet
- C++ SummaryDocument2 pagesC++ SummaryramakantsawantNo ratings yet
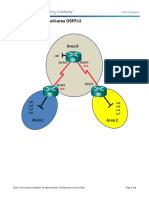
- 9.2.2.9 Lab - Configuring Multi-Area OSPFv3Document8 pages9.2.2.9 Lab - Configuring Multi-Area OSPFv3Jessica GregoryNo ratings yet
- Control Card For SB-3C Security Barrier With Multiplexer Photocell System SB-6P Reference HandbookDocument10 pagesControl Card For SB-3C Security Barrier With Multiplexer Photocell System SB-6P Reference HandbookEdnelson CostaNo ratings yet
- Subject Manual Tle 9-10Document12 pagesSubject Manual Tle 9-10Rhayan Dela Cruz DaquizNo ratings yet
- Laptop Sale Agreement ToolkitDocument2 pagesLaptop Sale Agreement ToolkitYogesh KherdeNo ratings yet
- Tender Document Power and Distribution TransformerDocument185 pagesTender Document Power and Distribution TransformerrasheshinNo ratings yet
- F5218213600000 PDFDocument6 pagesF5218213600000 PDFriga liruNo ratings yet
- 4CC Carrier Aggregation - AlexDocument19 pages4CC Carrier Aggregation - Alexel yousfiNo ratings yet
- Coupling and CohesionDocument2 pagesCoupling and CohesionDebadatta GadanayakNo ratings yet
- OQLDocument16 pagesOQLVikram KarkiNo ratings yet
- Embedded System and Matlab SIMULINK PDFDocument31 pagesEmbedded System and Matlab SIMULINK PDFclaudiunicolaNo ratings yet
- Chip War: The Fight for the World's Most Critical TechnologyFrom EverandChip War: The Fight for the World's Most Critical TechnologyRating: 4.5 out of 5 stars4.5/5 (82)
- Chip War: The Quest to Dominate the World's Most Critical TechnologyFrom EverandChip War: The Quest to Dominate the World's Most Critical TechnologyRating: 4.5 out of 5 stars4.5/5 (228)
- CompTIA A+ Complete Review Guide: Exam Core 1 220-1001 and Exam Core 2 220-1002From EverandCompTIA A+ Complete Review Guide: Exam Core 1 220-1001 and Exam Core 2 220-1002Rating: 5 out of 5 stars5/5 (1)
- iPhone 14 Guide for Seniors: Unlocking Seamless Simplicity for the Golden Generation with Step-by-Step ScreenshotsFrom EverandiPhone 14 Guide for Seniors: Unlocking Seamless Simplicity for the Golden Generation with Step-by-Step ScreenshotsRating: 5 out of 5 stars5/5 (3)
- Raspberry PI: Learn Rasberry Pi Programming the Easy Way, A Beginner Friendly User GuideFrom EverandRaspberry PI: Learn Rasberry Pi Programming the Easy Way, A Beginner Friendly User GuideNo ratings yet
- iPhone X Hacks, Tips and Tricks: Discover 101 Awesome Tips and Tricks for iPhone XS, XS Max and iPhone XFrom EverandiPhone X Hacks, Tips and Tricks: Discover 101 Awesome Tips and Tricks for iPhone XS, XS Max and iPhone XRating: 3 out of 5 stars3/5 (2)
- Cancer and EMF Radiation: How to Protect Yourself from the Silent Carcinogen of ElectropollutionFrom EverandCancer and EMF Radiation: How to Protect Yourself from the Silent Carcinogen of ElectropollutionRating: 5 out of 5 stars5/5 (2)
- CompTIA A+ Complete Review Guide: Core 1 Exam 220-1101 and Core 2 Exam 220-1102From EverandCompTIA A+ Complete Review Guide: Core 1 Exam 220-1101 and Core 2 Exam 220-1102Rating: 5 out of 5 stars5/5 (2)
- iPhone Unlocked for the Non-Tech Savvy: Color Images & Illustrated Instructions to Simplify the Smartphone Use for Beginners & Seniors [COLOR EDITION]From EverandiPhone Unlocked for the Non-Tech Savvy: Color Images & Illustrated Instructions to Simplify the Smartphone Use for Beginners & Seniors [COLOR EDITION]Rating: 5 out of 5 stars5/5 (3)
- CompTIA A+ Certification All-in-One Exam Guide, Eleventh Edition (Exams 220-1101 & 220-1102)From EverandCompTIA A+ Certification All-in-One Exam Guide, Eleventh Edition (Exams 220-1101 & 220-1102)Rating: 5 out of 5 stars5/5 (2)
- Hacking With Linux 2020:A Complete Beginners Guide to the World of Hacking Using Linux - Explore the Methods and Tools of Ethical Hacking with LinuxFrom EverandHacking With Linux 2020:A Complete Beginners Guide to the World of Hacking Using Linux - Explore the Methods and Tools of Ethical Hacking with LinuxNo ratings yet
- Mastering IoT For Industrial Environments: Unlock the IoT Landscape for Industrial Environments with Industry 4.0, Covering Architecture, Protocols like MQTT, and Advancements with ESP-IDFFrom EverandMastering IoT For Industrial Environments: Unlock the IoT Landscape for Industrial Environments with Industry 4.0, Covering Architecture, Protocols like MQTT, and Advancements with ESP-IDFNo ratings yet
- Arduino Sketches: Tools and Techniques for Programming WizardryFrom EverandArduino Sketches: Tools and Techniques for Programming WizardryRating: 4 out of 5 stars4/5 (1)
- CompTIA Security+ All-in-One Exam Guide, Sixth Edition (Exam SY0-601)From EverandCompTIA Security+ All-in-One Exam Guide, Sixth Edition (Exam SY0-601)Rating: 5 out of 5 stars5/5 (1)
- Raspberry Pi Retro Gaming: Build Consoles and Arcade Cabinets to Play Your Favorite Classic GamesFrom EverandRaspberry Pi Retro Gaming: Build Consoles and Arcade Cabinets to Play Your Favorite Classic GamesNo ratings yet
- Essential iPhone X iOS 12 Edition: The Illustrated Guide to Using iPhone XFrom EverandEssential iPhone X iOS 12 Edition: The Illustrated Guide to Using iPhone XRating: 5 out of 5 stars5/5 (1)