You might also like
- Vol4Iss2 P6Document9 pagesVol4Iss2 P6desx redjNo ratings yet
- DSInnovate Why Do Startup Choose CloudDocument47 pagesDSInnovate Why Do Startup Choose CloudAdrian KurniaNo ratings yet
- CC Unit-1Document18 pagesCC Unit-1ELON MUSKNo ratings yet
- Software-Defined Cloud Centers: Operational and Management Technologies and ToolsFrom EverandSoftware-Defined Cloud Centers: Operational and Management Technologies and ToolsNo ratings yet
- Moving To The Cloud: Why Cloud Computing MattersDocument40 pagesMoving To The Cloud: Why Cloud Computing MattersShaikat D. AjaxNo ratings yet
- Cloud Computing: Harnessing the Power of the Digital Skies: The IT CollectionFrom EverandCloud Computing: Harnessing the Power of the Digital Skies: The IT CollectionNo ratings yet
- Cloud Computing Seminar Report - 1713310073 PDFDocument23 pagesCloud Computing Seminar Report - 1713310073 PDFDeepesh RaiNo ratings yet
- Management Strategies for the Cloud Revolution (Review and Analysis of Babcock's Book)From EverandManagement Strategies for the Cloud Revolution (Review and Analysis of Babcock's Book)No ratings yet
- Lecture 2 Introduction To Cloud ComputingDocument122 pagesLecture 2 Introduction To Cloud ComputingSteffyRobert0% (1)
- A Review On Cloud Computing IJERTCONV3IS10108Document6 pagesA Review On Cloud Computing IJERTCONV3IS10108Awanish KumarNo ratings yet
- To Implement Data Security in Cloud Computing Environment: Mr.S.P.PATIL, Mr.H.E.Khodke, Mr.P.B.LandgeDocument5 pagesTo Implement Data Security in Cloud Computing Environment: Mr.S.P.PATIL, Mr.H.E.Khodke, Mr.P.B.LandgeManimurugan MNo ratings yet
- Cloud Computing IT As A ServiceDocument4 pagesCloud Computing IT As A Serviceferano915No ratings yet
- IeeeDocument22 pagesIeeekarthikajoyNo ratings yet
- Clearing The Clouds On Cloud Computing S-51490823 PDFDocument6 pagesClearing The Clouds On Cloud Computing S-51490823 PDFFisehaNo ratings yet
- NFV Theory and Practice - Cloudification - 3Document3 pagesNFV Theory and Practice - Cloudification - 3Mohammed Ghaleb100% (1)
- Dzone Rc82 Cloud ComputingDocument7 pagesDzone Rc82 Cloud Computingalx yedekNo ratings yet
- Cloud ComputingDocument14 pagesCloud ComputingAjay MathewNo ratings yet
- Cloud Computing A Seminar Report Submitt 3Document57 pagesCloud Computing A Seminar Report Submitt 3yihunieNo ratings yet
- Cloud Continuum: The DefinitionDocument18 pagesCloud Continuum: The DefinitionSunaina AroraNo ratings yet
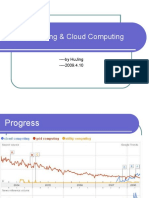
- Grid Computing & Cloud Computing: - by Hujing - 2009.4.10Document21 pagesGrid Computing & Cloud Computing: - by Hujing - 2009.4.10Kevin LowNo ratings yet
- !cloud Computing - Pros & ConsDocument5 pages!cloud Computing - Pros & ConsJeejooNo ratings yet
- Chapter 1 Introduction To Cloud Computing - Cloud ComputingDocument8 pagesChapter 1 Introduction To Cloud Computing - Cloud ComputingpalailalithaNo ratings yet
- Cloud Computing: A Collection of Working PapersDocument33 pagesCloud Computing: A Collection of Working PaperspymntsNo ratings yet
- Multi Component Application in Edge Computing.: AbstractDocument3 pagesMulti Component Application in Edge Computing.: AbstractAshutoshNo ratings yet
- Cloud of Things Cloud Computing and IoTDocument5 pagesCloud of Things Cloud Computing and IoTjonathan jibunorNo ratings yet
- Distributed Computing System: Research ReportDocument8 pagesDistributed Computing System: Research ReportRaman PalNo ratings yet
- Cloud ComputingDocument20 pagesCloud Computingchetnasri01No ratings yet
- CloudcomputingDocument29 pagesCloudcomputingKARAN MASTERNo ratings yet
- Cloud ComputingDocument3 pagesCloud ComputingAkash RajputNo ratings yet
- Secure CloudDocument8 pagesSecure CloudGanesh NavinNo ratings yet
- Analysis On The Concepts of Cloud Computing: Dhivyaa M, Praveena EDocument4 pagesAnalysis On The Concepts of Cloud Computing: Dhivyaa M, Praveena EDinesh KumarNo ratings yet
- Cloud Computing: Anggia Dasa Putri, S.Kom.,M.KomDocument14 pagesCloud Computing: Anggia Dasa Putri, S.Kom.,M.KomYoga RenaldiNo ratings yet
- Cloud Computing An Overview PDFDocument27 pagesCloud Computing An Overview PDFJaweria JaweriaNo ratings yet
- Edge Computing: Vision and Challenges: Weisong Shi, Jie Cao, Quan Zhang, Youhuizi Li and Lanyu XuDocument10 pagesEdge Computing: Vision and Challenges: Weisong Shi, Jie Cao, Quan Zhang, Youhuizi Li and Lanyu XuMoksha ShahNo ratings yet
- Enhancing Library Services With CloudDocument6 pagesEnhancing Library Services With Cloudserkalem yimerNo ratings yet
- A Survey of Fog Computing: Concepts, Applications and IssuesDocument6 pagesA Survey of Fog Computing: Concepts, Applications and IssuesSammy PakNo ratings yet
- Cloud Computing ResearchDocument2 pagesCloud Computing Researchapi-629866322No ratings yet
- Cloud Solutions NewsletterDocument15 pagesCloud Solutions NewsletterRay CarpenterNo ratings yet
- Clouded GuideDocument38 pagesClouded Guideturco de turquiaNo ratings yet
- Impact of Cloud Computing On IT Industry: A Review & AnalysisDocument5 pagesImpact of Cloud Computing On IT Industry: A Review & AnalysismarwanNo ratings yet
- White Paper Cloud Computing ( (PDF, 351 KB) )Document25 pagesWhite Paper Cloud Computing ( (PDF, 351 KB) )vidi87No ratings yet
- On The Planning and Design Problem of Fog Computing NetworksDocument14 pagesOn The Planning and Design Problem of Fog Computing NetworksnikhilNo ratings yet
- Deep Dive Into Cloud TechnologyDocument12 pagesDeep Dive Into Cloud TechnologyPhalit GuptaNo ratings yet
- Cloud Computing in Resource ManagementDocument6 pagesCloud Computing in Resource ManagementIJEMR JournalNo ratings yet
- Lecture 2 - Introduction To Cloud ComputingDocument122 pagesLecture 2 - Introduction To Cloud Computingmskumar_me100% (1)
- Ijcsit2014050513 PDFDocument4 pagesIjcsit2014050513 PDFrebwarpcNo ratings yet
- A Review Paper On Evolution of Cloud Computing, Its Approaches and Comparison With Grid ComputingDocument4 pagesA Review Paper On Evolution of Cloud Computing, Its Approaches and Comparison With Grid ComputingrebwarpcNo ratings yet
- Ijcsit20140505133 PDFDocument4 pagesIjcsit20140505133 PDFrebwarpcNo ratings yet
- Ijcsit2014050513 PDFDocument4 pagesIjcsit2014050513 PDFrebwarpcNo ratings yet
- Efficient Resource Management For Cloud Computing EnvironmentsDocument8 pagesEfficient Resource Management For Cloud Computing EnvironmentsNasir SayyedNo ratings yet
- Cloud Computing Is The Delivery ofDocument15 pagesCloud Computing Is The Delivery ofLuis RodriguesNo ratings yet
- Cloud Computing SecurityDocument4 pagesCloud Computing SecurityDiksha ChaudhariNo ratings yet
- Cloud Computing Introduction PDFDocument28 pagesCloud Computing Introduction PDFbshankar481No ratings yet
- CC Unit 4.1 Cloud-IntroDocument61 pagesCC Unit 4.1 Cloud-Introaditya guptaNo ratings yet
- IoT Technical PublicationsDocument128 pagesIoT Technical PublicationsAbhinav Saini50% (2)
- Cloud Computing - A New Era of Internet Computing.: Dhanush, 1st B.C.A, Vels University, Chennai. E-MailDocument4 pagesCloud Computing - A New Era of Internet Computing.: Dhanush, 1st B.C.A, Vels University, Chennai. E-MailVinoth VetrivelNo ratings yet
- Program Laravel Data Penjualan (Dasbor, Datapenjualan, Databarang, Input, Edit, Delete, View)Document32 pagesProgram Laravel Data Penjualan (Dasbor, Datapenjualan, Databarang, Input, Edit, Delete, View)Said RomadhonNo ratings yet
- Software SecurityDocument29 pagesSoftware SecuritySanjiv CrNo ratings yet
- Peaucel Perartilla CS158-2 Activity InstructionsDocument5 pagesPeaucel Perartilla CS158-2 Activity InstructionsPeaucel PerartillaNo ratings yet
- Chapter 01Document22 pagesChapter 01Aryan JuyalNo ratings yet
- Securing Information Systems: Case Study of Stuxnet and CyberwarfareDocument3 pagesSecuring Information Systems: Case Study of Stuxnet and CyberwarfareHasanthikaNo ratings yet
- Cyber WarfareDocument5 pagesCyber WarfareAmit KumarNo ratings yet
- Gujarat Technological UniversityDocument1 pageGujarat Technological UniversityCode AttractionNo ratings yet
- Meraki + Umbrella Better Together: GTM KickoffDocument22 pagesMeraki + Umbrella Better Together: GTM KickoffSon PhanNo ratings yet
- Rsync From QNAP To My Cloud HowToDocument8 pagesRsync From QNAP To My Cloud HowToConstantinos GardasNo ratings yet
- Deep Security 11 Certified Professional - Exam: Questions: 45 - Attempts: 3Document20 pagesDeep Security 11 Certified Professional - Exam: Questions: 45 - Attempts: 3machadotulio100% (2)
- DICE AnalyticsDocument24 pagesDICE Analyticsanjum87No ratings yet
- FM-SGO-PLA-003 Technical Assistance Form For EBEIS and LISDocument1 pageFM-SGO-PLA-003 Technical Assistance Form For EBEIS and LISLA SALETTE AURORANo ratings yet
- SG-Edge 电力物联网可信边缘计算框架关键技术 杨维永Document23 pagesSG-Edge 电力物联网可信边缘计算框架关键技术 杨维永Erix YangNo ratings yet
- Computer Security Chapter 5Document8 pagesComputer Security Chapter 5rh_rathodNo ratings yet
- Importance of Information Technology in Today World - by Niya John - MediumDocument2 pagesImportance of Information Technology in Today World - by Niya John - MediumHarapriya MohantaNo ratings yet
- BlackHat DC 2011 NunezDiCroce Onapsis-WpDocument19 pagesBlackHat DC 2011 NunezDiCroce Onapsis-Wprins.vitsNo ratings yet
- MCQ of Computer Security and Network SecurityDocument4 pagesMCQ of Computer Security and Network SecurityVipul SharmaNo ratings yet
- Nse 1Document14 pagesNse 1RenzoNo ratings yet
- DNM Safety Noob Guide PDFDocument7 pagesDNM Safety Noob Guide PDFTruco El MartinezNo ratings yet
- Device Protection With Microsoft Endpoint Manager and Microsoft Defender For Endpoint - Module 09 - Microsoft Defender For EndpointDocument71 pagesDevice Protection With Microsoft Endpoint Manager and Microsoft Defender For Endpoint - Module 09 - Microsoft Defender For EndpointLuke WhitemanNo ratings yet
- Analisis Dan Deteksi Malware Dengan Metode Hybrid Analysis Menggunakan Framework MobsfDocument11 pagesAnalisis Dan Deteksi Malware Dengan Metode Hybrid Analysis Menggunakan Framework MobsfAgung Tri LaksonoNo ratings yet
- What Is A Key Risk Indicator (KRI) and Why Is It ImportantDocument4 pagesWhat Is A Key Risk Indicator (KRI) and Why Is It ImportantJaveed A. KhanNo ratings yet
- Unit 5 Cyber CrimeDocument35 pagesUnit 5 Cyber CrimeDeborahNo ratings yet
- Gain Visibility and Control Over Your SSH and SSL EnvironmentsDocument9 pagesGain Visibility and Control Over Your SSH and SSL Environmentsmasterlinh2008No ratings yet
- NShield Microsoft ADCS and OCSP Windows Server 2012 IgDocument28 pagesNShield Microsoft ADCS and OCSP Windows Server 2012 IgJustin RobinsonNo ratings yet
- Panorama: Key Security FeaturesDocument6 pagesPanorama: Key Security FeaturesbercialesNo ratings yet
- PTask3 (Q) S1 20222023 StudentsDocument5 pagesPTask3 (Q) S1 20222023 StudentsMuhammad Afiq AffendiNo ratings yet
- IISF-Industry Internet of Things Security Framework v2 (Ebook)Document191 pagesIISF-Industry Internet of Things Security Framework v2 (Ebook)Mayer FernandesNo ratings yet
- CS 671: Cybersecurity: Lecture 1: Intro, Terms, ConceptsDocument36 pagesCS 671: Cybersecurity: Lecture 1: Intro, Terms, ConceptsTVBNo ratings yet
- ISO27k Standards ListingDocument2 pagesISO27k Standards Listingmax4oneNo ratings yet
- The Internet Con: How to Seize the Means of ComputationFrom EverandThe Internet Con: How to Seize the Means of ComputationRating: 5 out of 5 stars5/5 (6)
- Laws of UX: Using Psychology to Design Better Products & ServicesFrom EverandLaws of UX: Using Psychology to Design Better Products & ServicesRating: 5 out of 5 stars5/5 (9)
- Social Media Marketing 2024, 2025: Build Your Business, Skyrocket in Passive Income, Stop Working a 9-5 Lifestyle, True Online Working from HomeFrom EverandSocial Media Marketing 2024, 2025: Build Your Business, Skyrocket in Passive Income, Stop Working a 9-5 Lifestyle, True Online Working from HomeNo ratings yet
- Evaluation of Some Websites that Offer Virtual Phone Numbers for SMS Reception and Websites to Obtain Virtual Debit/Credit Cards for Online Accounts VerificationsFrom EverandEvaluation of Some Websites that Offer Virtual Phone Numbers for SMS Reception and Websites to Obtain Virtual Debit/Credit Cards for Online Accounts VerificationsRating: 5 out of 5 stars5/5 (1)
- Grokking Algorithms: An illustrated guide for programmers and other curious peopleFrom EverandGrokking Algorithms: An illustrated guide for programmers and other curious peopleRating: 4 out of 5 stars4/5 (16)
- The Designer’s Guide to Figma: Master Prototyping, Collaboration, Handoff, and WorkflowFrom EverandThe Designer’s Guide to Figma: Master Prototyping, Collaboration, Handoff, and WorkflowNo ratings yet
- Practical Industrial Cybersecurity: ICS, Industry 4.0, and IIoTFrom EverandPractical Industrial Cybersecurity: ICS, Industry 4.0, and IIoTNo ratings yet
- The Digital Marketing Handbook: A Step-By-Step Guide to Creating Websites That SellFrom EverandThe Digital Marketing Handbook: A Step-By-Step Guide to Creating Websites That SellRating: 5 out of 5 stars5/5 (6)
- The YouTube Formula: How Anyone Can Unlock the Algorithm to Drive Views, Build an Audience, and Grow RevenueFrom EverandThe YouTube Formula: How Anyone Can Unlock the Algorithm to Drive Views, Build an Audience, and Grow RevenueRating: 5 out of 5 stars5/5 (33)
- React.js Design Patterns: Learn how to build scalable React apps with ease (English Edition)From EverandReact.js Design Patterns: Learn how to build scalable React apps with ease (English Edition)No ratings yet
- More Porn - Faster!: 50 Tips & Tools for Faster and More Efficient Porn BrowsingFrom EverandMore Porn - Faster!: 50 Tips & Tools for Faster and More Efficient Porn BrowsingRating: 3.5 out of 5 stars3.5/5 (24)
- Tor Darknet Bundle (5 in 1): Master the Art of InvisibilityFrom EverandTor Darknet Bundle (5 in 1): Master the Art of InvisibilityRating: 4.5 out of 5 stars4.5/5 (5)
- The Ultimate LinkedIn Sales Guide: How to Use Digital and Social Selling to Turn LinkedIn into a Lead, Sales and Revenue Generating MachineFrom EverandThe Ultimate LinkedIn Sales Guide: How to Use Digital and Social Selling to Turn LinkedIn into a Lead, Sales and Revenue Generating MachineNo ratings yet
- TikTok Algorithms 2024 $15,000/Month Guide To Escape Your Job And Build an Successful Social Media Marketing Business From Home Using Your Personal Account, Branding, SEO, InfluencerFrom EverandTikTok Algorithms 2024 $15,000/Month Guide To Escape Your Job And Build an Successful Social Media Marketing Business From Home Using Your Personal Account, Branding, SEO, InfluencerRating: 4 out of 5 stars4/5 (4)
- Branding: What You Need to Know About Building a Personal Brand and Growing Your Small Business Using Social Media Marketing and Offline Guerrilla TacticsFrom EverandBranding: What You Need to Know About Building a Personal Brand and Growing Your Small Business Using Social Media Marketing and Offline Guerrilla TacticsRating: 5 out of 5 stars5/5 (32)
- How to Do Nothing: Resisting the Attention EconomyFrom EverandHow to Do Nothing: Resisting the Attention EconomyRating: 4 out of 5 stars4/5 (421)
- The Wires of War: Technology and the Global Struggle for PowerFrom EverandThe Wires of War: Technology and the Global Struggle for PowerRating: 4 out of 5 stars4/5 (34)
- Ultimate Guide to YouTube for BusinessFrom EverandUltimate Guide to YouTube for BusinessRating: 5 out of 5 stars5/5 (1)
- Summary of Traffic Secrets: by Russell Brunson - The Underground Playbook for Filling Your Websites and Funnels with Your Dream Customers - A Comprehensive SummaryFrom EverandSummary of Traffic Secrets: by Russell Brunson - The Underground Playbook for Filling Your Websites and Funnels with Your Dream Customers - A Comprehensive SummaryNo ratings yet