You might also like
- Gesture Classification With Kinect Sensor DataDocument5 pagesGesture Classification With Kinect Sensor DataMr BenniganNo ratings yet
- Multimodal Human Action Recognition Based On A Fusion of Dynamic Images Using CNN DescriptorsDocument8 pagesMultimodal Human Action Recognition Based On A Fusion of Dynamic Images Using CNN DescriptorsLourdesRamírezNo ratings yet
- Ijct V3i2p5Document9 pagesIjct V3i2p5IjctJournalsNo ratings yet
- Recognizing Military GesturesDocument17 pagesRecognizing Military GesturesPrayitNo ratings yet
- Signalizacija 19891988199019851980Document5 pagesSignalizacija 19891988199019851980milos89milosavljevicNo ratings yet
- LITERATUREDocument9 pagesLITERATUREJ SANDHYANo ratings yet
- Experimental Investigation of Linguistic PDFDocument20 pagesExperimental Investigation of Linguistic PDFNexuslord1kNo ratings yet
- Environment Recognition Based On Human Actions Using Probability NetworksDocument14 pagesEnvironment Recognition Based On Human Actions Using Probability NetworksLia Intan Nor KholifahNo ratings yet
- Fibra OpticDocument39 pagesFibra OpticCristhian Aparcana RomanNo ratings yet
- Lewkowicz 2015Document15 pagesLewkowicz 2015byrucNo ratings yet
- B F M G R S: Rightness Actor Atching For Esture Ecognition Ystem Using Scaled NormalizationDocument12 pagesB F M G R S: Rightness Actor Atching For Esture Ecognition Ystem Using Scaled NormalizationAnonymous Gl4IRRjzNNo ratings yet
- Hand Gesture Recognition Using A Real-Time Tracking Method and Hidden Markov ModelsDocument14 pagesHand Gesture Recognition Using A Real-Time Tracking Method and Hidden Markov ModelsNitin NileshNo ratings yet
- Sensors: Human Part Segmentation in Depth Images With Annotated Part PositionsDocument15 pagesSensors: Human Part Segmentation in Depth Images With Annotated Part PositionsAna-Maria ȘtefanNo ratings yet
- Bull Name Is GivenDocument13 pagesBull Name Is GivenPrateek Kumar PandeyNo ratings yet
- Full Body RecognisationDocument10 pagesFull Body RecognisationTahmid IkhlasNo ratings yet
- Features 2d TrajectoryDocument14 pagesFeatures 2d TrajectorySara RijoNo ratings yet
- Aid Deaf-Dumb PeopleDocument5 pagesAid Deaf-Dumb PeopleAbhishek PatilNo ratings yet
- Human Activity Recognition Process Using 3-D Posture DataDocument12 pagesHuman Activity Recognition Process Using 3-D Posture DataJojo SeseNo ratings yet
- Aviris Hyperspectral Images Compression Using 3d Spiht AlgorithmDocument6 pagesAviris Hyperspectral Images Compression Using 3d Spiht AlgorithmIOSRJEN : hard copy, certificates, Call for Papers 2013, publishing of journalNo ratings yet
- Gesture Recognition Using Voxelisation of SpaceDocument6 pagesGesture Recognition Using Voxelisation of SpaceturingsmartNo ratings yet
- Paper - Deep - Learning - Emotion Detection PDFDocument7 pagesPaper - Deep - Learning - Emotion Detection PDFJose Guillermo Balbuena GalvanNo ratings yet
- Densepose: Dense Human Pose Estimation in The Wild: Seminar: Vision Systems Ma-Inf 4208Document10 pagesDensepose: Dense Human Pose Estimation in The Wild: Seminar: Vision Systems Ma-Inf 4208Jelena TrajkovicNo ratings yet
- An Application of Anns To Human Action Recognition Based On Limbs' DataDocument4 pagesAn Application of Anns To Human Action Recognition Based On Limbs' DataMyagmarbayar NerguiNo ratings yet
- InTech-Real Time Robotic Hand Control Using Hand GesturesDocument16 pagesInTech-Real Time Robotic Hand Control Using Hand GesturesOrion HardwaredesignlabNo ratings yet
- Human Motion Detection in Manufacturing Process: Ágnes Lipovits, Mónika Gál, Péter József Kiss, Csaba SüvegesDocument8 pagesHuman Motion Detection in Manufacturing Process: Ágnes Lipovits, Mónika Gál, Péter József Kiss, Csaba SüvegesFarid MukhtarNo ratings yet
- Tmp7e53 TMPDocument12 pagesTmp7e53 TMPFrontiersNo ratings yet
- Performance Analysis of SVD and SPIHT Algorithm For Image Compression ApplicationDocument6 pagesPerformance Analysis of SVD and SPIHT Algorithm For Image Compression Applicationeditor_ijarcsseNo ratings yet
- Online Hand Gesture Recognition &2016Document4 pagesOnline Hand Gesture Recognition &2016sruthi 98No ratings yet
- Real Time Robust Human Detection and Tracking System: Jianpeng Zhou and Jack Hoang I3DVR International IncDocument8 pagesReal Time Robust Human Detection and Tracking System: Jianpeng Zhou and Jack Hoang I3DVR International IncDondelubyo RamzNo ratings yet
- Human Activity Recognition From VideoDocument24 pagesHuman Activity Recognition From Videobhagyashri1982No ratings yet
- IEEE Sensor Journal Motion Recognition 2012Document8 pagesIEEE Sensor Journal Motion Recognition 20129985237595No ratings yet
- Waves Paper For Nasa 00Document47 pagesWaves Paper For Nasa 00ssfofoNo ratings yet
- Meeting RecognisionDocument4 pagesMeeting RecognisionpeterijNo ratings yet
- WsRobotVision Gori Etal2013Document6 pagesWsRobotVision Gori Etal2013mounamalarNo ratings yet
- SynopsisDocument6 pagesSynopsisLokesh BhatiNo ratings yet
- Stereovision Based Hand Gesture RecognitionDocument30 pagesStereovision Based Hand Gesture RecognitionVikram Shenoy HandiruNo ratings yet
- Hand Gesture RecognisationDocument3 pagesHand Gesture RecognisationJournalNX - a Multidisciplinary Peer Reviewed JournalNo ratings yet
- Group30 Superpixel Based Human Computer Interface UsingaHand Gesture RecognitionDocument3 pagesGroup30 Superpixel Based Human Computer Interface UsingaHand Gesture RecognitionAmir RehmanNo ratings yet
- Bayesian Estimation of 3-d Human Motion From An Image SequenceDocument19 pagesBayesian Estimation of 3-d Human Motion From An Image SequenceElizar AlmencionNo ratings yet
- Collaborative Robotic Masonry and Early Stage Fatigue PredictionDocument8 pagesCollaborative Robotic Masonry and Early Stage Fatigue PredictionmadatdesignNo ratings yet
- Silangmaranan 2014Document10 pagesSilangmaranan 2014Dániel FábiánNo ratings yet
- Visually Gesture Recognition For An Interactive Robot Grasping ApplicationDocument8 pagesVisually Gesture Recognition For An Interactive Robot Grasping ApplicationMusthafa KadershaNo ratings yet
- Recognition of ASL Using Hand GesturesDocument5 pagesRecognition of ASL Using Hand GesturesInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Sign Language Recognition For Deaf and Dumb People: Y.M.Pathan, S.R.Waghmare, P.K.PatilDocument3 pagesSign Language Recognition For Deaf and Dumb People: Y.M.Pathan, S.R.Waghmare, P.K.PatilAnonymous Ndsvh2soNo ratings yet
- Signature Verification Entailing Principal Component Analysis As A Feature ExtractorDocument5 pagesSignature Verification Entailing Principal Component Analysis As A Feature Extractorscience2222No ratings yet
- A Gender Recognition System From Facial ImageDocument10 pagesA Gender Recognition System From Facial Imageahtasham hussainNo ratings yet
- Hand Gesture Recognition System: January 2011Document6 pagesHand Gesture Recognition System: January 2011raviNo ratings yet
- 3D Body MovingDocument13 pages3D Body MovingAnanya SaikiaNo ratings yet
- SanketDocument5 pagesSanketapi-26142417No ratings yet
- Ouellette 2006 PDFDocument13 pagesOuellette 2006 PDFsamik4uNo ratings yet
- Recognizing Bharatnatyam Mudra Using Principles of Gesture RecognitionDocument7 pagesRecognizing Bharatnatyam Mudra Using Principles of Gesture RecognitionijcsnNo ratings yet
- Ijaiem 2014 02 28 088Document4 pagesIjaiem 2014 02 28 088International Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Fingerprint Authentication With Minutiae Using Ridge Feature ExtractionDocument5 pagesFingerprint Authentication With Minutiae Using Ridge Feature ExtractionInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Low Cost Motion CaptureDocument5 pagesLow Cost Motion CaptureioscherzoNo ratings yet
- Sensor Controlled Animatronic Hand: Graduation Project PresentationDocument24 pagesSensor Controlled Animatronic Hand: Graduation Project PresentationAnonymous D2FmKSxuuNo ratings yet
- Swarm Intelligence 3.1. Swarm IntelligenceDocument6 pagesSwarm Intelligence 3.1. Swarm IntelligencePravat SatpathyNo ratings yet
- Real-Time Robotic Hand Control Using Hand GesturesDocument5 pagesReal-Time Robotic Hand Control Using Hand GesturesmenzactiveNo ratings yet
- Image Background Search: Combining Object Detection Techniques With Content-Based Image Retrieval (CBIR) SystemsDocument5 pagesImage Background Search: Combining Object Detection Techniques With Content-Based Image Retrieval (CBIR) Systemspraveenreddy7No ratings yet
- Stereo Vision IROS05Document7 pagesStereo Vision IROS05bidwejNo ratings yet
- Schoonenbeek Kees Concertino Pour Flute A Bec Et Piano 67702Document16 pagesSchoonenbeek Kees Concertino Pour Flute A Bec Et Piano 67702Rodrigo Balthar FurmanNo ratings yet
- Friedrich Lehmann - A Treatise On Simple Counterpoint in 40 LessonsDocument7 pagesFriedrich Lehmann - A Treatise On Simple Counterpoint in 40 LessonsRodrigo Balthar FurmanNo ratings yet
- Hatching and Cross Hatching ExamplesDocument2 pagesHatching and Cross Hatching ExamplesRodrigo Balthar FurmanNo ratings yet
- Rysen, Fenwick - Occult Swordplay - Basics PDFDocument8 pagesRysen, Fenwick - Occult Swordplay - Basics PDFTerra Sancta Permaculture100% (1)
- Haimo - Developing Variation and Schoenbergs Serial MusicDocument18 pagesHaimo - Developing Variation and Schoenbergs Serial MusicRodrigo Balthar FurmanNo ratings yet
- IOS Csound - A Beginners GuideDocument40 pagesIOS Csound - A Beginners GuideRodrigo Balthar FurmanNo ratings yet
- APPLYING THE ŠEVČIK ANALYTICAL STUDIES METHOD TO BARTÓK'S CONCERTO FOR VIOLA AND ORCHESTRA: A PERFORMER'S GUIDE by MEGAN CHISOM PEYTONDocument103 pagesAPPLYING THE ŠEVČIK ANALYTICAL STUDIES METHOD TO BARTÓK'S CONCERTO FOR VIOLA AND ORCHESTRA: A PERFORMER'S GUIDE by MEGAN CHISOM PEYTONRodrigo Balthar FurmanNo ratings yet
- Eaglestone, Ford, Nuhn, Moore and Brown - Composition Systems Requirements For Creativity: What Research Methodology?Document10 pagesEaglestone, Ford, Nuhn, Moore and Brown - Composition Systems Requirements For Creativity: What Research Methodology?Rodrigo Balthar FurmanNo ratings yet
- Complete EIS BrochureDocument13 pagesComplete EIS BrochureRodrigo Balthar Furman100% (6)
- Elliott Review LaBelle AcousticTerritories LibreDocument3 pagesElliott Review LaBelle AcousticTerritories LibreRodrigo Balthar FurmanNo ratings yet
- Dan Warburton - A Working Terminology For Minimal MusicDocument12 pagesDan Warburton - A Working Terminology For Minimal MusicRodrigo Balthar FurmanNo ratings yet
- Handout 1 - Post-Humboldtian DoctorateDocument12 pagesHandout 1 - Post-Humboldtian DoctorateRodrigo Balthar FurmanNo ratings yet
- (Martial Arts) Fitness TipsDocument7 pages(Martial Arts) Fitness Tipsbrogan100% (21)
- Santa Morena PDFDocument6 pagesSanta Morena PDFchumpitais50% (2)
- Imslp01307 BWV1004 PDFDocument11 pagesImslp01307 BWV1004 PDFhaaltamiNo ratings yet
- Hurrian Tab LTDDocument2 pagesHurrian Tab LTDRodrigo Balthar FurmanNo ratings yet
- The Well-Cultured AnonymousDocument111 pagesThe Well-Cultured AnonymousJewJitsu666No ratings yet
- Rosa CruzDocument1 pageRosa CruzRodrigo Balthar FurmanNo ratings yet
- Guide For Programming in AssemblyDocument70 pagesGuide For Programming in AssemblyRodrigo Balthar FurmanNo ratings yet
- Composition ReadingsDocument2 pagesComposition ReadingsRodrigo Balthar FurmanNo ratings yet
- Hurrian Tab LTDDocument2 pagesHurrian Tab LTDRodrigo Balthar FurmanNo ratings yet
- Fluid Electrolyte Acid-Base BalanceDocument16 pagesFluid Electrolyte Acid-Base BalanceAsif AliNo ratings yet
- GPHC Pre-Registration Complete Exam Question List JUNE 2017 - NOV 2021Document50 pagesGPHC Pre-Registration Complete Exam Question List JUNE 2017 - NOV 2021Summer Sunshine TVNo ratings yet
- Dr.d.k.taneja, DR - Jayant Sharma2Document306 pagesDr.d.k.taneja, DR - Jayant Sharma2samabdelaal20000% (1)
- Larone S Medically Important Fungi - 2018 - Walsh - Color PlatesDocument29 pagesLarone S Medically Important Fungi - 2018 - Walsh - Color PlatesYenia Micol MatwiejukNo ratings yet
- Haemoptysis Diagnosis and TreatmentDocument57 pagesHaemoptysis Diagnosis and TreatmentMuhammad Cholid AlfahroziNo ratings yet
- Posterior CorticalDocument24 pagesPosterior CorticalJ Alonso MejiaNo ratings yet
- Gastrointestinal Disease: Oral MedicineDocument11 pagesGastrointestinal Disease: Oral Medicineحمزه التلاحمهNo ratings yet
- The Physical Examination To Assess For Anemia and HypovolemiaDocument10 pagesThe Physical Examination To Assess For Anemia and HypovolemiaAlejandro MaitaNo ratings yet
- XIJU5502Document3 pagesXIJU5502Praveen ReddyNo ratings yet
- Pulmonology Short CasesDocument10 pagesPulmonology Short CasesRZ Ng100% (1)
- Epilepsy SurgeryDocument13 pagesEpilepsy SurgeryDon RomanNo ratings yet
- Meds #1 NotesDocument4 pagesMeds #1 NotesAnh TrinhNo ratings yet
- Becker's Nevus With Neurofibromatosis Type 1: Annals of Indian Academy of Neurology February 2015Document4 pagesBecker's Nevus With Neurofibromatosis Type 1: Annals of Indian Academy of Neurology February 2015YesicaNo ratings yet
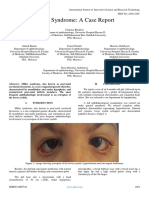
- Chaimae Khodriss Ahmed Bennis Fouad Chraibi Meriem Abdellaoui Idriss Benatiya AndaloussiDocument3 pagesChaimae Khodriss Ahmed Bennis Fouad Chraibi Meriem Abdellaoui Idriss Benatiya AndaloussiInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Case Study - CvaDocument3 pagesCase Study - CvaJrBong Semanero50% (2)
- Ier 1Document27 pagesIer 1Shara BolañosNo ratings yet
- Oxford Handbook of Clinical Pathology PDFDocument7 pagesOxford Handbook of Clinical Pathology PDFppgpcsNo ratings yet
- Drug Study (Measles)Document7 pagesDrug Study (Measles)Ericka VillanuevaNo ratings yet
- Kode Icd XDocument8 pagesKode Icd Xraniasyahcandra67% (6)
- Medicament OsDocument109 pagesMedicament OsKatia ColonioNo ratings yet
- TRIANGLES OF THE BODY (Sources: Snell, Internet Sources)Document3 pagesTRIANGLES OF THE BODY (Sources: Snell, Internet Sources)Mei Bejerano - Roldan100% (1)
- Pewarisan Sifat PSPDDocument73 pagesPewarisan Sifat PSPDWILLIAM LUTHNo ratings yet
- Integrated Management of Childhood Illnesses (IMCI) : Dr. Pushpa Raj SharmaDocument29 pagesIntegrated Management of Childhood Illnesses (IMCI) : Dr. Pushpa Raj SharmaEarl CorderoNo ratings yet
- Adenosine Life MedicalDocument20 pagesAdenosine Life MedicalLaura ZahariaNo ratings yet
- Basicecginterpretationpracticetestv1 AshxDocument7 pagesBasicecginterpretationpracticetestv1 AshxEdward ZiyachechaNo ratings yet
- Abdominal Aortic AneurysmDocument10 pagesAbdominal Aortic AneurysmSNo ratings yet
- Locked-In SyndromeDocument3 pagesLocked-In SyndromeBlogos CarlaNo ratings yet
- Banti Syndrome PDFDocument8 pagesBanti Syndrome PDFWiyosa RusdiNo ratings yet
- Orthodontics in Medically CompromisedDocument189 pagesOrthodontics in Medically CompromisedAshish MathewNo ratings yet
- 1 Gastrointestinal System DisordersDocument14 pages1 Gastrointestinal System DisordersAnna Sofia Reyes100% (1)