You might also like
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- 6th Central Pay Commission Salary CalculatorDocument15 pages6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
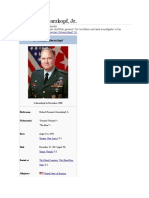
- Norman SchwarzkopfDocument16 pagesNorman SchwarzkopfnicasioaquinoNo ratings yet
- Method Vs MethodologyDocument6 pagesMethod Vs Methodologyalisyed37No ratings yet
- ISO 27001 Checklist Action ItemsDocument16 pagesISO 27001 Checklist Action ItemssujanNo ratings yet
- Impact of Digital Marketing On Consumer BehaviorDocument13 pagesImpact of Digital Marketing On Consumer BehaviorMd Belayet Hosen RajuNo ratings yet
- Research Methods: Literature ReviewDocument49 pagesResearch Methods: Literature Reviewyousaf razaNo ratings yet
- Innovation Best Practices 3mDocument4 pagesInnovation Best Practices 3mDarleen Joy UdtujanNo ratings yet
- Addiction, What Is ItDocument12 pagesAddiction, What Is ItnicasioaquinoNo ratings yet
- ISSP The Ground of Successful IT ProjectsDocument2 pagesISSP The Ground of Successful IT ProjectsnicasioaquinoNo ratings yet
- Azilsartan Medoxomil (Edarbi)Document15 pagesAzilsartan Medoxomil (Edarbi)nicasioaquinoNo ratings yet
- Army Wargaming Model Analyzes Battle PlansDocument2 pagesArmy Wargaming Model Analyzes Battle PlansnicasioaquinoNo ratings yet
- Abstract - Sayyid Qutb and Radical IslamismDocument19 pagesAbstract - Sayyid Qutb and Radical IslamismnicasioaquinoNo ratings yet
- World Bank - Philippine Economic ConditionsDocument9 pagesWorld Bank - Philippine Economic ConditionsNicasio Perez Lim AquinoNo ratings yet
- 2004 Indian Ocean Earthquake and TsunamiDocument38 pages2004 Indian Ocean Earthquake and TsunaminicasioaquinoNo ratings yet
- Broken Windows TheoryDocument18 pagesBroken Windows TheorynicasioaquinoNo ratings yet
- Thought Leader Pantawil Pamilya ProgramDocument6 pagesThought Leader Pantawil Pamilya ProgramnicasioaquinoNo ratings yet
- Simple Wind Estimation Using Drop and G7 BCDocument1 pageSimple Wind Estimation Using Drop and G7 BCnicasioaquinoNo ratings yet
- Indonesian Tycoon Skirts Charter Limits Through Corporate LayersDocument5 pagesIndonesian Tycoon Skirts Charter Limits Through Corporate LayersnicasioaquinoNo ratings yet
- 40 Percent of Global Assets Belong To 1 Percent of PopulationDocument2 pages40 Percent of Global Assets Belong To 1 Percent of PopulationnicasioaquinoNo ratings yet
- Distribution of Income by Frank LevyDocument13 pagesDistribution of Income by Frank LevynicasioaquinoNo ratings yet
- Economic Basics - Supply and DemandDocument8 pagesEconomic Basics - Supply and DemandnicasioaquinoNo ratings yet
- Fat Tailed DistributionDocument3 pagesFat Tailed DistributionnicasioaquinoNo ratings yet
- Crispy CrabletsDocument2 pagesCrispy CrabletsnicasioaquinoNo ratings yet
- Leadership 101Document1 pageLeadership 101nicasioaquinoNo ratings yet
- Game Theory Calls Cooperation Into QuestionDocument10 pagesGame Theory Calls Cooperation Into QuestionnicasioaquinoNo ratings yet
- Addiction, What Is ItDocument12 pagesAddiction, What Is ItnicasioaquinoNo ratings yet
- Broken Windows TheoryDocument18 pagesBroken Windows TheorynicasioaquinoNo ratings yet
- Embutido RecipeDocument2 pagesEmbutido RecipenicasioaquinoNo ratings yet
- Broken Windows TheoryDocument18 pagesBroken Windows TheorynicasioaquinoNo ratings yet
- Has The Randomized Trial Movement Has Put The Auditors in Charge of The R&D DepartmentDocument6 pagesHas The Randomized Trial Movement Has Put The Auditors in Charge of The R&D DepartmentnicasioaquinoNo ratings yet
- 2004 Indian Ocean Earthquake and TsunamiDocument38 pages2004 Indian Ocean Earthquake and TsunaminicasioaquinoNo ratings yet
- Don't Treat Innovation As A Cure-AllDocument3 pagesDon't Treat Innovation As A Cure-AllNicolai AquinoNo ratings yet
- Mass Atrocity Monday - Tiananmen SquareDocument6 pagesMass Atrocity Monday - Tiananmen SquarenicasioaquinoNo ratings yet
- John F. Nash Jr., Math Genius of 'A Beautiful Mind,' Dies at 86Document10 pagesJohn F. Nash Jr., Math Genius of 'A Beautiful Mind,' Dies at 86nicasioaquinoNo ratings yet
- AP Statistics 3.5Document7 pagesAP Statistics 3.5Eric0% (1)
- SHS - English For Acad Module 1Document8 pagesSHS - English For Acad Module 1vBloody BunnyNo ratings yet
- Interpretation in HistoryDocument9 pagesInterpretation in HistoryΚΟΥΣΑΡΙΔΗΣ ΚΩΝΣΤΑΝΤΙΝΟΣNo ratings yet
- Newsfiles SCE Suppl 1 2Document43 pagesNewsfiles SCE Suppl 1 2XavierNo ratings yet
- Ets 18 3 PDFDocument336 pagesEts 18 3 PDFaswardiNo ratings yet
- FAA 150 - 5300 - 18b PDFDocument492 pagesFAA 150 - 5300 - 18b PDFtangautaNo ratings yet
- PMWJ3-Oct2012-BIVINS-BIBLE-StrategicPortfolioPerformance-UTD-SecondEditionDocument15 pagesPMWJ3-Oct2012-BIVINS-BIBLE-StrategicPortfolioPerformance-UTD-SecondEditionKuldeep SinghNo ratings yet
- iX6Iazv1Rfq-biostatistics MineDocument6 pagesiX6Iazv1Rfq-biostatistics MineShashank AlokNo ratings yet
- New Microsoft Office Word DocumentDocument59 pagesNew Microsoft Office Word Document09m008_159913639No ratings yet
- Performance Based Design of Buildings & Bridges For Enhanced Seismic ResilienceDocument8 pagesPerformance Based Design of Buildings & Bridges For Enhanced Seismic ResilienceMohit JainNo ratings yet
- SIP Reports - SampleDocument2 pagesSIP Reports - SamplegauravNo ratings yet
- SMI Corporate Profile: Home Opportunities Meet Our Team Insights ContactDocument7 pagesSMI Corporate Profile: Home Opportunities Meet Our Team Insights ContactPhem PhemNo ratings yet
- Itl 608 SignatureassignmentDocument8 pagesItl 608 Signatureassignmentapi-415022394No ratings yet
- Chapter 5 Creativity, The Business Idea, and Opportunity AnalysisDocument8 pagesChapter 5 Creativity, The Business Idea, and Opportunity AnalysisHans Jhayson CuadraNo ratings yet
- Types of ScalesDocument8 pagesTypes of ScalesBahrouniNo ratings yet
- Tests For Paired SensitivitiesDocument10 pagesTests For Paired SensitivitiesscjofyWFawlroa2r06YFVabfbajNo ratings yet
- Project Charter Template 02Document4 pagesProject Charter Template 02Ali GhazanferNo ratings yet
- The Table and Histogram Show Some Information About The Weights, in Grams, of Some TomatoesDocument17 pagesThe Table and Histogram Show Some Information About The Weights, in Grams, of Some TomatoesalandavidgrantNo ratings yet
- Marketing Assignment On Short Notes - MbaDocument53 pagesMarketing Assignment On Short Notes - MbaRajat Nitika Verma100% (1)
- Poshandevi Social Studies SBA COMPLETEDDocument23 pagesPoshandevi Social Studies SBA COMPLETEDFrëßh AsíáñNo ratings yet
- Boosting-Performance-Through-Organization-DesignDocument7 pagesBoosting-Performance-Through-Organization-DesignAyoub AroucheNo ratings yet
- JD SR Sap MM Consultant PDFDocument2 pagesJD SR Sap MM Consultant PDFSrinivas DsNo ratings yet
- Ems441 A2Document40 pagesEms441 A2api-662101203No ratings yet
- 157 GSJ6271 SkillDevelopmentinIndiaALiteratureReviewDocument12 pages157 GSJ6271 SkillDevelopmentinIndiaALiteratureReviewAnchal BipinNo ratings yet