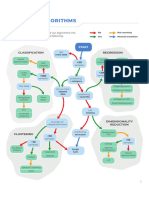
You might also like
- CNN Features Off-the-Shelf - An Astounding Baseline For RecognitionDocument8 pagesCNN Features Off-the-Shelf - An Astounding Baseline For RecognitionhiriNo ratings yet
- Technical Analysis 20 January 2010 JPY: Comment: Strategy: Chart LevelsDocument1 pageTechnical Analysis 20 January 2010 JPY: Comment: Strategy: Chart LevelsMiir ViirNo ratings yet
- Mizuho Corporate BankDocument1 pageMizuho Corporate BankMiir ViirNo ratings yet
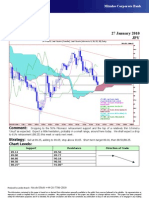
- Technical Analysis 27 January 2010 JPY: Comment: Strategy: Chart LevelsDocument1 pageTechnical Analysis 27 January 2010 JPY: Comment: Strategy: Chart LevelsMiir ViirNo ratings yet
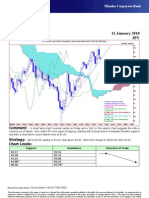
- Technical Analysis 11 January 2010 JPY: Comment: Strategy: Chart LevelsDocument1 pageTechnical Analysis 11 January 2010 JPY: Comment: Strategy: Chart LevelsMiir ViirNo ratings yet
- Walls 2017 Undergrad Research Day at The Capitol FinalDocument1 pageWalls 2017 Undergrad Research Day at The Capitol Finaldario susanoNo ratings yet
- Mizuho Corporate BankDocument1 pageMizuho Corporate BankMiir ViirNo ratings yet
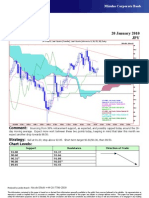
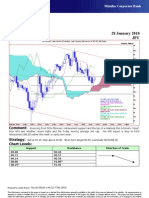
- Technical Analysis 28 January 2010 JPY: Comment: Strategy: Chart LevelsDocument1 pageTechnical Analysis 28 January 2010 JPY: Comment: Strategy: Chart LevelsMiir ViirNo ratings yet
- Mizuho Corporate BankDocument1 pageMizuho Corporate BankMiir ViirNo ratings yet
- Technical Analysis 12 January 2010 JPY: Comment: Strategy: Chart LevelsDocument1 pageTechnical Analysis 12 January 2010 JPY: Comment: Strategy: Chart LevelsMiir ViirNo ratings yet
- Machine Learning Quick Start GuideDocument1 pageMachine Learning Quick Start GuideHammad RiazNo ratings yet
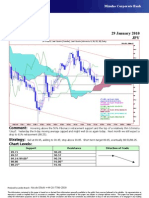
- Technical Analysis 29 January 2010 JPY: Comment: Strategy: Chart LevelsDocument1 pageTechnical Analysis 29 January 2010 JPY: Comment: Strategy: Chart LevelsMiir ViirNo ratings yet
- RuralConnect Gen 3 6MHzDocument4 pagesRuralConnect Gen 3 6MHzyaciro cabezasNo ratings yet
- Of The Present Work Data AnalysisDocument1 pageOf The Present Work Data Analysisharjeet sindhuNo ratings yet
- ZakDennis 2Document1 pageZakDennis 2Zakerij DennisNo ratings yet
- Mizuho Corporate BankDocument1 pageMizuho Corporate BankMiir ViirNo ratings yet
- Gen 3 Ruralconnect SpecificationsDocument4 pagesGen 3 Ruralconnect SpecificationsDeriansyah Al GhurabaNo ratings yet
- East Imi Post DT ReportDocument17 pagesEast Imi Post DT ReportHAWLITUNo ratings yet
- Mizuho Corporate BankDocument1 pageMizuho Corporate BankMiir ViirNo ratings yet
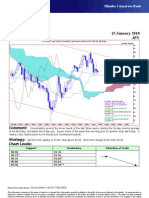
- Technical Analysis 15 January 2010 JPY: Comment: Strategy: Chart LevelsDocument1 pageTechnical Analysis 15 January 2010 JPY: Comment: Strategy: Chart LevelsMiir ViirNo ratings yet
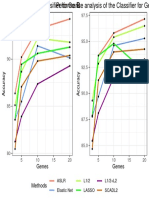
- Genes Genes: Aslr Elastic Net L1/2 Lasso L1/2+L2 Scadl2Document1 pageGenes Genes: Aslr Elastic Net L1/2 Lasso L1/2+L2 Scadl2viju001No ratings yet
- Genes Genes: Aslr Elastic Net L1/2 Lasso L1/2+L2 Scadl2Document1 pageGenes Genes: Aslr Elastic Net L1/2 Lasso L1/2+L2 Scadl2viju001No ratings yet
- # (PAPAYA Plus) Catalog Eng Ver.2021 - CompressedDocument5 pages# (PAPAYA Plus) Catalog Eng Ver.2021 - CompressedTONDERAINo ratings yet
- RuralConnect Gen3 ETSI 03 22 18 Print Book RDocument4 pagesRuralConnect Gen3 ETSI 03 22 18 Print Book RMICHAELL SEBASTIAN RUBIANO ORTIZNo ratings yet
- 16-20att6 3Document4 pages16-20att6 3aldojudinNo ratings yet
- Swin Transformer V2: Scaling Up Capacity and ResolutionDocument11 pagesSwin Transformer V2: Scaling Up Capacity and ResolutionqwertyNo ratings yet
- Find & Fic Jdsu PDFDocument1 pageFind & Fic Jdsu PDFoscarNo ratings yet
- 2017:Machine Learning of SVM Classification Utilizing Complete Binary Tree Structure for PAM-4、8 Optical InterconnectionDocument2 pages2017:Machine Learning of SVM Classification Utilizing Complete Binary Tree Structure for PAM-4、8 Optical InterconnectionRana Babar AliNo ratings yet
- Open SQL Editor: Saps'Word - We Sap For Your CauseDocument5 pagesOpen SQL Editor: Saps'Word - We Sap For Your CauseVinod NagarahalliNo ratings yet
- Deli Be Rant TestDocument19 pagesDeli Be Rant TestvezetoNo ratings yet
- VolteDocument1 pageVoltemohamed100% (1)
- EfficientNet - Rethinking Model Scaling For Convolutional Neural NetworksDocument10 pagesEfficientNet - Rethinking Model Scaling For Convolutional Neural NetworksRahul DeoraNo ratings yet
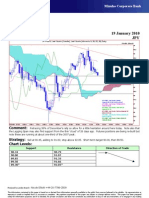
- Technical Analysis 19 January 2010 JPY: Comment: Strategy: Chart LevelsDocument1 pageTechnical Analysis 19 January 2010 JPY: Comment: Strategy: Chart LevelsMiir ViirNo ratings yet
- Residential Area: 10 M Wide RoadDocument1 pageResidential Area: 10 M Wide RoadharishNo ratings yet
- Technical Requirements: Importance To CustDocument4 pagesTechnical Requirements: Importance To CustAhmad SafrizalNo ratings yet
- Take A Closer Look: Deliver The Optimal Course of TreatmentDocument6 pagesTake A Closer Look: Deliver The Optimal Course of TreatmentEliesNo ratings yet
- Efficientnet: Rethinking Model Scaling For Convolutional Neural NetworksDocument10 pagesEfficientnet: Rethinking Model Scaling For Convolutional Neural Networks吳 澍 WU SU F74056297No ratings yet
- How To Embed Your KPIsDocument13 pagesHow To Embed Your KPIsdtvt40No ratings yet
- Vision and Image Processing Lab, Indian Institute of Technology Bombay, India (Ferozalitm, SC) @ee - Iitb.ac - inDocument1 pageVision and Image Processing Lab, Indian Institute of Technology Bombay, India (Ferozalitm, SC) @ee - Iitb.ac - inferozalitmNo ratings yet
- Papaya 2 DDocument5 pagesPapaya 2 Dsosomagdi65No ratings yet
- Apache Quick Reference Card: Sectional DirectivesDocument2 pagesApache Quick Reference Card: Sectional DirectivesAllen SmithNo ratings yet
- EXFO Reference-Poster Raman V1 enDocument3 pagesEXFO Reference-Poster Raman V1 enBoy Tai HinNo ratings yet
- Scikit LearnDocument1 pageScikit Learnmax bisceneNo ratings yet
- Deep Learning For Scene Classification: A SurveyDocument24 pagesDeep Learning For Scene Classification: A Surveyamta1No ratings yet
- Site Plan S6 - 4-1-2020Document1 pageSite Plan S6 - 4-1-2020harishNo ratings yet
- Back Modeling WPDocument13 pagesBack Modeling WPSanderXNo ratings yet
- CNCF LandscapeDocument1 pageCNCF Landscaperodrigo.filgueiraNo ratings yet
- VISSIM Calibration PDFDocument4 pagesVISSIM Calibration PDFÁdám DunsztNo ratings yet
- Method Development With Eclipse Plus 3Document42 pagesMethod Development With Eclipse Plus 3Martin GrifaldoNo ratings yet
- 15 - Introduction To Optimization Tools Rev ADocument37 pages15 - Introduction To Optimization Tools Rev Abrahiti3No ratings yet
- Bit Error Ratio BER in DVB As A Function of S/N: Application NoteDocument16 pagesBit Error Ratio BER in DVB As A Function of S/N: Application NoteIndra Al-KahfiNo ratings yet
- Installation Procedure, Electronic Vessel Control, Gas and D3 EVC - BDocument1 pageInstallation Procedure, Electronic Vessel Control, Gas and D3 EVC - BRaul JosingNo ratings yet
- Literature Survey: Paper Model Used Dataset Results RemarksDocument2 pagesLiterature Survey: Paper Model Used Dataset Results RemarksHarshal SomanNo ratings yet
- OPT British Cumulus - IMO 9724532 - Cargo Operating ManualDocument231 pagesOPT British Cumulus - IMO 9724532 - Cargo Operating Manualseawolf50No ratings yet
- Apache Quick Reference CardDocument2 pagesApache Quick Reference Cardsakworld100% (1)
- Preamble Design and Coarse Synchronization Using CAZAC Sequence For Uplink Cable ModemDocument5 pagesPreamble Design and Coarse Synchronization Using CAZAC Sequence For Uplink Cable ModemHaji Rana ShahidNo ratings yet
- West Imi Post DT ReportDocument17 pagesWest Imi Post DT ReportHAWLITUNo ratings yet
- MEP - KPI - Annexure - IDocument1 pageMEP - KPI - Annexure - Iranjeet.globalgreenNo ratings yet
- Digital Modulations using MatlabFrom EverandDigital Modulations using MatlabRating: 4 out of 5 stars4/5 (6)
- Big Data For Health PDFDocument16 pagesBig Data For Health PDFAkash GuptaNo ratings yet
- Top Interview QuestionsDocument2 pagesTop Interview QuestionsAkash GuptaNo ratings yet
- Speech Intelligibility Potential of General andDocument15 pagesSpeech Intelligibility Potential of General andAkash GuptaNo ratings yet
- Robust Sound Event Classification UsingDocument13 pagesRobust Sound Event Classification UsingAkash GuptaNo ratings yet
- ASR For Under-Resourced Languages FromDocument14 pagesASR For Under-Resourced Languages FromAkash GuptaNo ratings yet
- DAV ProjDocument1 pageDAV ProjAkash GuptaNo ratings yet
- Strassens Matrix MultiplicationDocument1 pageStrassens Matrix MultiplicationAkash GuptaNo ratings yet
- Smart CarDocument13 pagesSmart CarAkash GuptaNo ratings yet
- Sensor Data Wearable DviceDocument8 pagesSensor Data Wearable DviceAkash GuptaNo ratings yet
- Neural Machine Translation PDFDocument15 pagesNeural Machine Translation PDFAkash GuptaNo ratings yet
- Learning How To Learn Coursera Meflou PDFDocument7 pagesLearning How To Learn Coursera Meflou PDFAkash GuptaNo ratings yet
- COE PLACEMENTS Jobtraining Form ResponsesDocument4 pagesCOE PLACEMENTS Jobtraining Form ResponsesAkash GuptaNo ratings yet
- Vehicle DetectionDocument10 pagesVehicle DetectionAkash GuptaNo ratings yet
- MST - CG - AnswersDocument12 pagesMST - CG - AnswersAkash GuptaNo ratings yet
- Applications of Stacks HGJDocument3 pagesApplications of Stacks HGJAkash GuptaNo ratings yet
- QUEUE - 2 VHBJNKNKDocument6 pagesQUEUE - 2 VHBJNKNKAkash GuptaNo ratings yet
- Lecture 13 (9) BJNNKMLDocument9 pagesLecture 13 (9) BJNNKMLAkash GuptaNo ratings yet
- Sample Map Reduce CodeDocument1 pageSample Map Reduce CodeAkash GuptaNo ratings yet
- 3 V's of Big DatahgjDocument9 pages3 V's of Big DatahgjAkash GuptaNo ratings yet
- TransformationDocument10 pagesTransformationzex007No ratings yet
- Email Spam Classifier: Test Case DocumentationDocument2 pagesEmail Spam Classifier: Test Case DocumentationAkash GuptaNo ratings yet
- UCS805 GHVVGVCGDocument1 pageUCS805 GHVVGVCGAkash GuptaNo ratings yet
- Lecture 13 (9) BJNNKMLDocument9 pagesLecture 13 (9) BJNNKMLAkash GuptaNo ratings yet
- DFD Examples: Yong Choi BPA CsubDocument20 pagesDFD Examples: Yong Choi BPA Csubsharoo501No ratings yet
- B.E/B.Tech. M.E/M.Tech. M.Sc. MBADocument28 pagesB.E/B.Tech. M.E/M.Tech. M.Sc. MBAAkash GuptaNo ratings yet
- Sequence To Sequence Learning With Neural NetworksDocument9 pagesSequence To Sequence Learning With Neural NetworksIonel Alexandru HosuNo ratings yet
- Time Tablejan - May 2017 3-1-2017Document204 pagesTime Tablejan - May 2017 3-1-2017Akash GuptaNo ratings yet
- 1506 05869v3Document8 pages1506 05869v3Akash GuptaNo ratings yet
- MB700.4 Managerial Economics Quiz 1 MarksDocument3 pagesMB700.4 Managerial Economics Quiz 1 MarksJAY SolankiNo ratings yet
- PDF Edited Chapter 1-5Document46 pagesPDF Edited Chapter 1-5Revtech RevalbosNo ratings yet
- Wsnake Prog 06a Withlogo 1Document2 pagesWsnake Prog 06a Withlogo 1api-216697963No ratings yet
- Test 2Document7 pagesTest 2muhammad_muhammadshoaib_shoaibNo ratings yet
- Techniques To Memorize SwiftlyDocument33 pagesTechniques To Memorize SwiftlyAsad ChishtiNo ratings yet
- McNamara Graesser Coh-MetrixDocument30 pagesMcNamara Graesser Coh-Metrixdiankusuma123No ratings yet
- LmsDocument10 pagesLmsRohit VermaNo ratings yet
- Gwhollinger 23Document5 pagesGwhollinger 23api-371629484No ratings yet
- Reading Writing Speaking Listening: in A Classroom, I Prefer ToDocument10 pagesReading Writing Speaking Listening: in A Classroom, I Prefer ToAnaJGNo ratings yet
- Crafting An MSC Project ProposalDocument4 pagesCrafting An MSC Project ProposalStanslaus FrancisNo ratings yet
- The Settings, Processes, Methods and Tools in COunselingDocument11 pagesThe Settings, Processes, Methods and Tools in COunselingAdditional File StorageNo ratings yet
- First HPTA MeetingDocument20 pagesFirst HPTA MeetingRochelle OlivaNo ratings yet
- INDOOR SPORTS CENTRES - RESEARCH v3Document66 pagesINDOOR SPORTS CENTRES - RESEARCH v3thomas.miller43995No ratings yet
- PANOYPOYAN ES Report On LASDocument4 pagesPANOYPOYAN ES Report On LASEric D. ValleNo ratings yet
- Curriculum Vitae and Letter of ApplicationDocument7 pagesCurriculum Vitae and Letter of ApplicationandragraziellaNo ratings yet
- Analisis Faktor Yang Berhubungan Dengan Perilaku Seks Bebas Pada Remaja Di SMK DR Soetomo Surabaya Berdasarkan Teori Perilaku WhoDocument14 pagesAnalisis Faktor Yang Berhubungan Dengan Perilaku Seks Bebas Pada Remaja Di SMK DR Soetomo Surabaya Berdasarkan Teori Perilaku WhoMONIKA SUJOKONo ratings yet
- Research On Administrative CompetenceDocument2 pagesResearch On Administrative Competencehastim rosianaNo ratings yet
- Protein Synthesis QuestionarreDocument2 pagesProtein Synthesis QuestionarreRiza Sardido SimborioNo ratings yet
- Table of Specification in Tle 7Document1 pageTable of Specification in Tle 7JhEng Cao ManansalaNo ratings yet
- State of AI Report 2023 - ONLINEDocument163 pagesState of AI Report 2023 - ONLINEtwwang.ntuNo ratings yet
- More Theatre Games and Exercises: Section 3Document20 pagesMore Theatre Games and Exercises: Section 3Alis MocanuNo ratings yet
- 337TO 003 World's Largest FLNG PreludeDocument9 pages337TO 003 World's Largest FLNG PreludeRamNo ratings yet
- Nrityagram DocsDocument2 pagesNrityagram DocsSajalSaket100% (1)
- Short CV: Prof. Dr. Zulkardi, M.I.Komp., MSCDocument39 pagesShort CV: Prof. Dr. Zulkardi, M.I.Komp., MSCDika Dani SeptiatiNo ratings yet
- Econ 251 PS4 SolutionsDocument11 pagesEcon 251 PS4 SolutionsPeter ShangNo ratings yet
- ICT Project For Social Change Lesson 4Document58 pagesICT Project For Social Change Lesson 4Maria MaraNo ratings yet
- Error Analysis Practice Form 6Document3 pagesError Analysis Practice Form 6manbitt1208No ratings yet
- 11-Foundations of GMAT VerbalDocument35 pages11-Foundations of GMAT VerbalDroea Intimates100% (1)
- Hepp Katz Lazarfeld 4Document5 pagesHepp Katz Lazarfeld 4linhgtran010305No ratings yet
- Black Bodies White Bodies Gypsy Images IDocument23 pagesBlack Bodies White Bodies Gypsy Images IPatricia GallettiNo ratings yet