You might also like
- Structured Search for Big Data: From Keywords to Key-objectsFrom EverandStructured Search for Big Data: From Keywords to Key-objectsNo ratings yet
- Binary Search Research PaperDocument5 pagesBinary Search Research Paperfys5ehgs100% (1)
- Unit1 IntroductionDocument31 pagesUnit1 Introductionharinimurugesan834No ratings yet
- Search Engine TechniquesDocument10 pagesSearch Engine TechniquesSrikanth AryanNo ratings yet
- 2008d Sigirforum MurdockDocument4 pages2008d Sigirforum MurdockrrbgittanNo ratings yet
- Information Retrieval Thesis TopicsDocument6 pagesInformation Retrieval Thesis Topicstheresasinghseattle100% (2)
- 4 Primitives For Data Mining 3Document27 pages4 Primitives For Data Mining 3Nguyễn Gia TríNo ratings yet
- BCA-404: Data Mining and Data Ware HousingDocument19 pagesBCA-404: Data Mining and Data Ware HousingefwewefNo ratings yet
- Ir - Chapter 1Document7 pagesIr - Chapter 1Anoo ShresthaNo ratings yet
- A Language For Manipulating Clustered Web Documents ResultsDocument19 pagesA Language For Manipulating Clustered Web Documents ResultsAlessandro Siro CampiNo ratings yet
- Generating Query Facets Using Knowledge Bases: CSE Dept 1 VMTWDocument63 pagesGenerating Query Facets Using Knowledge Bases: CSE Dept 1 VMTWMahveen ArshiNo ratings yet
- Research Paper On Information Retrieval SystemDocument7 pagesResearch Paper On Information Retrieval Systemfys1q18y100% (1)
- Order #455987742Document4 pagesOrder #455987742Brian RelsonNo ratings yet
- Empowerment Week3Document3 pagesEmpowerment Week3dabidNo ratings yet
- DEXA08final PDFDocument9 pagesDEXA08final PDFVerginaSANo ratings yet
- Name of Learner: - Section: - SchoolDocument7 pagesName of Learner: - Section: - Schooljestony matillaNo ratings yet
- Literature Review of Survey MethodsDocument6 pagesLiterature Review of Survey Methodsc5qdk8jn100% (1)
- CS6007 - Information Retrieval Models, Web Search and Text MiningDocument24 pagesCS6007 - Information Retrieval Models, Web Search and Text MiningPavithra paviNo ratings yet
- Unit-1 DWDMDocument20 pagesUnit-1 DWDMsanjayktNo ratings yet
- Chapter 1 Introduction To ISRDocument39 pagesChapter 1 Introduction To ISRAaron MelendezNo ratings yet
- Empowerment and TechnologyDocument11 pagesEmpowerment and TechnologyfharnizaparasanNo ratings yet
- Research Papers On Information Retrieval SystemsDocument4 pagesResearch Papers On Information Retrieval Systemsgahebak1mez2100% (1)
- Personalized Web Search Using User ProfilesDocument35 pagesPersonalized Web Search Using User ProfilesMahmoud Abdel-SalamNo ratings yet
- Module - 3 - Empowerment Technology - Week 3-4Document11 pagesModule - 3 - Empowerment Technology - Week 3-4Jay Dhel75% (4)
- Book Exercises NayelliAnswersDocument3 pagesBook Exercises NayelliAnswersNayelli Valeria PcNo ratings yet
- q1 Module 2 EmptechDocument8 pagesq1 Module 2 EmptechKhie MonidaNo ratings yet
- A Design of Faceted Search Engine - A ReviewDocument5 pagesA Design of Faceted Search Engine - A ReviewMohammed Al-NiameyNo ratings yet
- Multi-Label Classification of Short Text: A Study On Wikipedia BarnstarsDocument6 pagesMulti-Label Classification of Short Text: A Study On Wikipedia BarnstarsPyankoffNo ratings yet
- Information Retrieval Thesis PDFDocument4 pagesInformation Retrieval Thesis PDFjessicaoatisneworleans100% (2)
- Literature Review Data Envelopment AnalysisDocument10 pagesLiterature Review Data Envelopment Analysisea3c5mfq100% (1)
- Information Retrieval On The Internet: OutlineDocument30 pagesInformation Retrieval On The Internet: OutlineIbrahim Ahmed AlishuNo ratings yet
- Chapter 5 Web and Search EnginesDocument18 pagesChapter 5 Web and Search EnginesabrehamNo ratings yet
- OntoSearch An Ontology Search EngineDocument12 pagesOntoSearch An Ontology Search EngineDũng NguyễnNo ratings yet
- DMW - Unit 1Document21 pagesDMW - Unit 1Priya BhaleraoNo ratings yet
- Topcat: Data Mining For Topic Identification in A Text CorpusDocument33 pagesTopcat: Data Mining For Topic Identification in A Text CorpusDrSenthil KumarNo ratings yet
- The Librarian As Hacker Getting More From GoogleDocument10 pagesThe Librarian As Hacker Getting More From Googletensun tNo ratings yet
- Empowerment Technologies Week 3Document4 pagesEmpowerment Technologies Week 3Vanessa LubianoNo ratings yet
- Can All Tags Be Used For SearchDocument10 pagesCan All Tags Be Used For SearchSilicon ValleyNo ratings yet
- IR Algorithms Survey: Representation and Searching TechniquesDocument8 pagesIR Algorithms Survey: Representation and Searching TechniquesshanthinisampathNo ratings yet
- ICT Empowerment-Technologies Q1 Module3Document13 pagesICT Empowerment-Technologies Q1 Module3Luckyluige NagbuyaNo ratings yet
- Information Literacy Skills: Research SkillsDocument42 pagesInformation Literacy Skills: Research SkillsMuhammad RedzuanNo ratings yet
- "Busres": BSBA MM-III Evening ClassDocument22 pages"Busres": BSBA MM-III Evening ClassMay Rhey Grace AparriNo ratings yet
- TXSA Lecture-7-9-2023 PDFDocument8 pagesTXSA Lecture-7-9-2023 PDFWeixin07No ratings yet
- IJCER (WWW - Ijceronline.com) International Journal of Computational Engineering ResearchDocument4 pagesIJCER (WWW - Ijceronline.com) International Journal of Computational Engineering ResearchInternational Journal of computational Engineering research (IJCER)No ratings yet
- Online Literature Search For Research Projects: October 2014Document10 pagesOnline Literature Search For Research Projects: October 2014Hizbullah KhanNo ratings yet
- Cs8080 - Irt - Notes AllDocument281 pagesCs8080 - Irt - Notes Allmukeshmsd2No ratings yet
- Thesis Information RetrievalDocument8 pagesThesis Information RetrievalScientificPaperWritingServicesKansasCity100% (2)
- Cse3087 Information-retrieval-And-Organization Eth 1.0 0 Information Retrieval and Organization-convertedDocument3 pagesCse3087 Information-retrieval-And-Organization Eth 1.0 0 Information Retrieval and Organization-convertedJaswanthh KrishnaNo ratings yet
- Research Paper On Database IndexingDocument4 pagesResearch Paper On Database Indexingcwzobjbkf100% (1)
- DWDM R19 Unit 1Document27 pagesDWDM R19 Unit 1GAYATHRI KAMMARA 19MIS7006No ratings yet
- HF91Document13 pagesHF91api-3803202No ratings yet
- Literature Review On Pattern RecognitionDocument8 pagesLiterature Review On Pattern Recognitionaflshxeid100% (1)
- Information Retrieval ThesisDocument5 pagesInformation Retrieval ThesisDaphne Smith100% (2)
- IR-Course-Introduction-Part-1Document249 pagesIR-Course-Introduction-Part-1Gaurav MahajanNo ratings yet
- Syllabus: Unit-I Why We Need Data Mining?Document21 pagesSyllabus: Unit-I Why We Need Data Mining?Pradeepkumar 05No ratings yet
- Interactive Query and Search in Semistructured Databases: Roy Goldman, Jennifer WidomDocument7 pagesInteractive Query and Search in Semistructured Databases: Roy Goldman, Jennifer WidompostscriptNo ratings yet
- Jens-Erik Mai: GuidelinesDocument3 pagesJens-Erik Mai: GuidelinesJijoyMNo ratings yet
- Brief Comments About Qualitative Data AnalysisDocument10 pagesBrief Comments About Qualitative Data AnalysisTreymax SikanNo ratings yet
- Genre Classification of Web Pages: - User Study and Feasibility AnalysisDocument15 pagesGenre Classification of Web Pages: - User Study and Feasibility AnalysisBOTTA NAVEEN KRISHNA 20186068No ratings yet
- Introduction to Algorithms & Data Structures 2: A solid foundation for the real world of machine learning and data analyticsFrom EverandIntroduction to Algorithms & Data Structures 2: A solid foundation for the real world of machine learning and data analyticsNo ratings yet
- 5G Challenges & ResearchDocument4 pages5G Challenges & ResearchInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- An Experimental Study On Flexural Behaviour of Reinforced Concrete Beam Strengthened With FRP CompositesDocument4 pagesAn Experimental Study On Flexural Behaviour of Reinforced Concrete Beam Strengthened With FRP CompositesInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Seismic Analysis and Design of Multi-Storied RC Building Using STAAD Pro and ETABSDocument4 pagesSeismic Analysis and Design of Multi-Storied RC Building Using STAAD Pro and ETABSInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Study of Supraharmonics and Its Reduction by Using Novel ControllerDocument4 pagesStudy of Supraharmonics and Its Reduction by Using Novel ControllerInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Fabrication of Hand Motion Control End EffectorDocument3 pagesFabrication of Hand Motion Control End EffectorInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Safety Management in Coal Mining Industrial Output Transporting System (Haul Roads, Benches Heights, Widths and Slope) For Effective ProductionDocument3 pagesSafety Management in Coal Mining Industrial Output Transporting System (Haul Roads, Benches Heights, Widths and Slope) For Effective ProductionInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Static Seismic Analysis of RCC Building As Per Is 18932002 by Using STAAD-Pro SoftwareDocument7 pagesStatic Seismic Analysis of RCC Building As Per Is 18932002 by Using STAAD-Pro SoftwareInternational Journal of Innovations in Engineering and Science100% (1)
- Experimental Analysis of Self Compacting Concrete (SCC) Using Fly Ash, Stone Dust and Silica FumesDocument4 pagesExperimental Analysis of Self Compacting Concrete (SCC) Using Fly Ash, Stone Dust and Silica FumesInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Design and Fabrication of Three Wheeler Drive Forklift For Industrial WarehousesDocument3 pagesDesign and Fabrication of Three Wheeler Drive Forklift For Industrial WarehousesInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Mathematical Modeling and Analysis of Various Parameters Responsible For Gray Cast Iron DefectsDocument4 pagesMathematical Modeling and Analysis of Various Parameters Responsible For Gray Cast Iron DefectsInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Intelligent Transportation System-Recent Trends in Transportation System A ReviewDocument6 pagesIntelligent Transportation System-Recent Trends in Transportation System A ReviewInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Design and Analysis of Go-Kart ChassisDocument6 pagesDesign and Analysis of Go-Kart ChassisInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Study of Real-Time Smart Traffic ControllerDocument4 pagesStudy of Real-Time Smart Traffic ControllerInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Analysis and Design of (G+100) Storied Building by Using SoftwareDocument3 pagesAnalysis and Design of (G+100) Storied Building by Using SoftwareInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Dynamic Seismic Analysis of RCC Building As Per Is 18932002 by Using STAAD-Pro SoftwareDocument7 pagesDynamic Seismic Analysis of RCC Building As Per Is 18932002 by Using STAAD-Pro SoftwareInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Increasing Productivity Using 5 S Techniques in Small Scale IndustriesDocument4 pagesIncreasing Productivity Using 5 S Techniques in Small Scale IndustriesInternational Journal of Innovations in Engineering and Science100% (1)
- A Survey On Jamming Attacks in Wireless Sensor NetworksDocument6 pagesA Survey On Jamming Attacks in Wireless Sensor NetworksInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Evaluation of Part Production Methodology in Automotive IndustryDocument5 pagesEvaluation of Part Production Methodology in Automotive IndustryInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Steer The Sphere Navigate The Location Nearby Using Augmented RealityDocument3 pagesSteer The Sphere Navigate The Location Nearby Using Augmented RealityInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- An Experimental Study On ShearBehaviour of Reinforced Concrete Beam Strengthened With FRP CompositesDocument4 pagesAn Experimental Study On ShearBehaviour of Reinforced Concrete Beam Strengthened With FRP CompositesInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Customer Satisfaction Analysis in Four Wheeler Service CentreDocument4 pagesCustomer Satisfaction Analysis in Four Wheeler Service CentreInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Computer Aided Analysis of Vibration in Machine Tool and Design of Damping SystemDocument4 pagesComputer Aided Analysis of Vibration in Machine Tool and Design of Damping SystemInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Design & Analysis of Multi-Part Fixture For Pin Quadrant of Quadrant Sub-Assembly of CultivatorDocument12 pagesDesign & Analysis of Multi-Part Fixture For Pin Quadrant of Quadrant Sub-Assembly of CultivatorInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Sustainability Assessment For Road Project UsingDocument2 pagesSustainability Assessment For Road Project UsingInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Smart Trolley in Shopping MallDocument3 pagesSmart Trolley in Shopping MallInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Survey On Automatic Solar Tracking SystemDocument3 pagesSurvey On Automatic Solar Tracking SystemInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Smart Ration Card System Using RFIDDocument3 pagesSmart Ration Card System Using RFIDInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Sentiment Analysis of Product ReviewDocument6 pagesSentiment Analysis of Product ReviewInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Navigo: Harshal Kamble, Mayuri Waghmare, Rajeshree Sonwane, Sonal Shende, Sonali Tiwari. Prof.N.R.HatwarDocument3 pagesNavigo: Harshal Kamble, Mayuri Waghmare, Rajeshree Sonwane, Sonal Shende, Sonali Tiwari. Prof.N.R.HatwarInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Remote Sensing and Geographic Information System Based Route Planning ReviewDocument5 pagesRemote Sensing and Geographic Information System Based Route Planning ReviewInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Practise Active and Passive Voice History of Central Europe: I Lead-InDocument4 pagesPractise Active and Passive Voice History of Central Europe: I Lead-InCorina LuchianaNo ratings yet
- HOTC 1 TheFoundingoftheChurchandtheEarlyChristians PPPDocument42 pagesHOTC 1 TheFoundingoftheChurchandtheEarlyChristians PPPSuma HashmiNo ratings yet
- Nursing Effective Leadership in Career DevelopmentDocument4 pagesNursing Effective Leadership in Career DevelopmentAlan Divine BNo ratings yet
- RQQDocument3 pagesRQQRazerrdooNo ratings yet
- Bracketing MethodsDocument13 pagesBracketing Methodsasd dsa100% (1)
- Summary Essay Items..EditedDocument8 pagesSummary Essay Items..EditedJoboy FritzNo ratings yet
- In The United States Bankruptcy Court For The District of Delaware in Re:) ) Mervyn'S Holdings, LLC, Et Al.) Case No. 08-11586 (KG) ) ) Debtors.) Affidavit of ServiceDocument19 pagesIn The United States Bankruptcy Court For The District of Delaware in Re:) ) Mervyn'S Holdings, LLC, Et Al.) Case No. 08-11586 (KG) ) ) Debtors.) Affidavit of ServiceChapter 11 DocketsNo ratings yet
- WSP - Aci 318-02 Shear Wall DesignDocument5 pagesWSP - Aci 318-02 Shear Wall DesignSalomi Ann GeorgeNo ratings yet
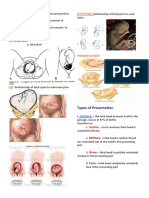
- The 4Ps of Labor: Passenger, Passageway, Powers, and PlacentaDocument4 pagesThe 4Ps of Labor: Passenger, Passageway, Powers, and PlacentaMENDIETA, JACQUELINE V.No ratings yet
- Lantern October 2012Document36 pagesLantern October 2012Jovel JosephNo ratings yet
- Module 1 in Contemporary Arts First MonthDocument12 pagesModule 1 in Contemporary Arts First MonthMiles Bugtong CagalpinNo ratings yet
- TOTAL Income: POSSTORE JERTEH - Account For 2021 Start Date 8/1/2021 End Date 8/31/2021Document9 pagesTOTAL Income: POSSTORE JERTEH - Account For 2021 Start Date 8/1/2021 End Date 8/31/2021Alice NguNo ratings yet
- Explore the rules and history of American football and basketballDocument2 pagesExplore the rules and history of American football and basketballAndrei IoneanuNo ratings yet
- Engaged Listening Worksheet 3 - 24Document3 pagesEngaged Listening Worksheet 3 - 24John BennettNo ratings yet
- Fundamentals of Analytics in Practice /TITLEDocument43 pagesFundamentals of Analytics in Practice /TITLEAcad ProgrammerNo ratings yet
- Class Homework Chapter 1Document9 pagesClass Homework Chapter 1Ela BallıoğluNo ratings yet
- Midnight HotelDocument7 pagesMidnight HotelAkpevweOghene PeaceNo ratings yet
- RITL 2007 (Full Text)Document366 pagesRITL 2007 (Full Text)Institutul de Istorie și Teorie LiterarăNo ratings yet
- AIESEC - Exchange Participant (EP) GuidebookDocument24 pagesAIESEC - Exchange Participant (EP) GuidebookAnonymous aoQ8gc1No ratings yet
- Midterm Exam ADM3350 Summer 2022 PDFDocument7 pagesMidterm Exam ADM3350 Summer 2022 PDFHan ZhongNo ratings yet
- Introduction To ResearchDocument5 pagesIntroduction To Researchapi-385504653No ratings yet
- Keppel's lease rights and option to purchase land upheldDocument6 pagesKeppel's lease rights and option to purchase land upheldkdcandariNo ratings yet
- 2020 Non Student Candidates For PCL BoardDocument13 pages2020 Non Student Candidates For PCL BoardPeoples College of LawNo ratings yet
- Compiled May 5, 2017 Case DigestDocument16 pagesCompiled May 5, 2017 Case DigestGrace CastilloNo ratings yet
- Ethanox 330 Antioxidant: Safety Data SheetDocument7 pagesEthanox 330 Antioxidant: Safety Data Sheetafryan azhar kurniawanNo ratings yet
- 6 Lesson Writing Unit: Personal Recount For Grade 3 SEI, WIDA Level 2 Writing Kelsie Drown Boston CollegeDocument17 pages6 Lesson Writing Unit: Personal Recount For Grade 3 SEI, WIDA Level 2 Writing Kelsie Drown Boston Collegeapi-498419042No ratings yet
- Portfolio HistoryDocument8 pagesPortfolio Historyshubham singhNo ratings yet
- January 2008 Ecobon Newsletter Hilton Head Island Audubon SocietyDocument6 pagesJanuary 2008 Ecobon Newsletter Hilton Head Island Audubon SocietyHilton Head Island Audubon SocietyNo ratings yet
- Georgetown University NewsletterDocument3 pagesGeorgetown University Newsletterapi-262723514No ratings yet