You might also like
- Exam Questions Chapter2&3Document65 pagesExam Questions Chapter2&3Aisha QasimNo ratings yet
- 2017 Formatted Exam Paper ENEN20002 (2017)Document13 pages2017 Formatted Exam Paper ENEN20002 (2017)leonNo ratings yet
- Fitting of A Transformation Geoid Model To The Gravimetric-Geometric Geoid Model of Benin CityDocument7 pagesFitting of A Transformation Geoid Model To The Gravimetric-Geometric Geoid Model of Benin CityETEJE SYLVESTSTER OKIEMUTE (Ph.D)No ratings yet
- Dflzfmp&. Ddsatda.: M M M MWKDocument20 pagesDflzfmp&. Ddsatda.: M M M MWKKiran UgalmugaleNo ratings yet
- TP PaperDocument70 pagesTP PapersannndyNo ratings yet
- PH Poe 0 PssDocument26 pagesPH Poe 0 Pssayushsingh202586No ratings yet
- Aakash Rank Booster Test Series For NEET-2020Document15 pagesAakash Rank Booster Test Series For NEET-2020Anbu100% (1)
- Xii-Neet Final Question Paper - 10.10.2021Document19 pagesXii-Neet Final Question Paper - 10.10.2021N GANESHNo ratings yet
- Mechanical Engineering Full Paper 2010Document14 pagesMechanical Engineering Full Paper 2010anbamechNo ratings yet
- 29-03-2023 - Outgoing SR Iit SPL GTM - FN - QPDocument19 pages29-03-2023 - Outgoing SR Iit SPL GTM - FN - QPAseemNo ratings yet
- Science 4 Education MinistryDocument24 pagesScience 4 Education MinistryCharith JayalathNo ratings yet
- Solver Manual - Mud Flow - : Morpho2DHDocument14 pagesSolver Manual - Mud Flow - : Morpho2DHpuji harsantoNo ratings yet
- Fts 1-1Document22 pagesFts 1-1hodmathsmsuNo ratings yet
- Intensive CST-04 - (Code-A) - Sol - 14-06-2022Document21 pagesIntensive CST-04 - (Code-A) - Sol - 14-06-2022The BoNg FOOD recipesNo ratings yet
- A Generalised Neyman Type - A DistributionDocument8 pagesA Generalised Neyman Type - A DistributionIJRASETPublicationsNo ratings yet
- 2015 Exam Paper ENEN20002Document11 pages2015 Exam Paper ENEN20002leonNo ratings yet
- Cycles Student Aug10 09Document25 pagesCycles Student Aug10 09Lindsay CookNo ratings yet
- Performance of A Floating Pipe Breakwater Based On Intelligent ComputingDocument43 pagesPerformance of A Floating Pipe Breakwater Based On Intelligent ComputingSanjay Govind PatilNo ratings yet
- Fortnightly Test SeriesDocument13 pagesFortnightly Test SeriesDebarjun Halder100% (2)
- Final DPP JEE Main 2020 PDFDocument80 pagesFinal DPP JEE Main 2020 PDFDivyank srivastavaNo ratings yet
- Narayana 22-06-2022 Outgoing SR Jee Main Model GTM A N Session QPDocument17 pagesNarayana 22-06-2022 Outgoing SR Jee Main Model GTM A N Session QPShreyas VedantiNo ratings yet
- Mechanical Engineering Full Paper 2008Document23 pagesMechanical Engineering Full Paper 2008anbamechNo ratings yet
- June 2023 BEVAE-181Document20 pagesJune 2023 BEVAE-181Shivam SainiNo ratings yet
- Intensive Program For Neet-2021Document19 pagesIntensive Program For Neet-2021Ahkil NandaNo ratings yet
- Part-1: Physics: SECTION - 1: (Maximum Marks: 80)Document11 pagesPart-1: Physics: SECTION - 1: (Maximum Marks: 80)Bhart BansalNo ratings yet
- Pyq RsDocument31 pagesPyq Rssunil adeNo ratings yet
- Intensive Program For Neet-2021: Complete Syllabus of NEETDocument19 pagesIntensive Program For Neet-2021: Complete Syllabus of NEETShankhayan Dutta100% (1)
- Neural Network Prediction of A Storm Surge: T.-L. LeeDocument12 pagesNeural Network Prediction of A Storm Surge: T.-L. LeeTamer AbdelmigidNo ratings yet
- Aakash Revision Test - 07 PaperDocument20 pagesAakash Revision Test - 07 PaperPriya DharshiniNo ratings yet
- X A C B D: 1. The Discrete Random Variable X Has Probability Function P (X) and Cumulative DistributionDocument17 pagesX A C B D: 1. The Discrete Random Variable X Has Probability Function P (X) and Cumulative DistributionHalal BoiNo ratings yet
- 2011 DecDocument23 pages2011 Deckarthimath05No ratings yet
- ch-1 Phy MEASUREMENT AND MOTIONDocument2 pagesch-1 Phy MEASUREMENT AND MOTIONRakesh GuptaNo ratings yet
- WavesDocument19 pagesWavessundar77vish77No ratings yet
- Vortex Structure in The Wall Region of An Impinging Plane JetDocument9 pagesVortex Structure in The Wall Region of An Impinging Plane JetRAVI KUMARNo ratings yet
- Seismic DesignDocument10 pagesSeismic DesignAbu Zam Afalla MananganNo ratings yet
- Study of Waves in Piezoelectric Heterogeneous Poroelastic Layer Over An Initially Stressed Heterogeneous Poroelastic Half SpaceDocument6 pagesStudy of Waves in Piezoelectric Heterogeneous Poroelastic Layer Over An Initially Stressed Heterogeneous Poroelastic Half SpaceNanda KumarNo ratings yet
- Observed Natural Frequency PileDocument5 pagesObserved Natural Frequency PileRutul DesaiNo ratings yet
- Schnabel Lysmer Seed 1972Document114 pagesSchnabel Lysmer Seed 1972Paloma CortizoNo ratings yet
- Paper 2222Document16 pagesPaper 2222Abhijeet GholapNo ratings yet
- Question Weekly Test-03 Arjuna NEET 19-08-2023Document2 pagesQuestion Weekly Test-03 Arjuna NEET 19-08-2023Shivam SolankiNo ratings yet
- Vigo 2007Document21 pagesVigo 2007Debora Cores CarreraNo ratings yet
- Rainfall Intensity-Duration-Frequency Analysis For The City of GaziantepDocument8 pagesRainfall Intensity-Duration-Frequency Analysis For The City of Gaziantepdhan singhNo ratings yet
- Engineering HydrologyDocument68 pagesEngineering HydrologyHassan Bin khalidNo ratings yet
- CST 20Document25 pagesCST 20aryaadarshsinghNo ratings yet
- Poll P-01Document3 pagesPoll P-01Mag GamingNo ratings yet
- Ant Colony Optimization Algorithm Solution For Critical Depth in Circular and Parabolic Open ChannelsDocument7 pagesAnt Colony Optimization Algorithm Solution For Critical Depth in Circular and Parabolic Open ChannelsFoolad GharbNo ratings yet
- Neet Full Test - 1Document16 pagesNeet Full Test - 1digvijay singhNo ratings yet
- All Full Syllabus TestDocument1,101 pagesAll Full Syllabus TestmevinaroNo ratings yet
- RainfallIntensity Duration FrequencyAnalysisfortheCityofGaziantepDocument8 pagesRainfallIntensity Duration FrequencyAnalysisfortheCityofGaziantepIbrahim KhanNo ratings yet
- Paths, Rechability and Connectedness (Lecture Notes)Document10 pagesPaths, Rechability and Connectedness (Lecture Notes)YASH PRAJAPATINo ratings yet
- Eol - Sci - I, II PP - 2018Document14 pagesEol - Sci - I, II PP - 2018Sharada KumarasingheNo ratings yet
- Numerical Study On The Effect of Mooring Line Stiffness On Hydrodynamic Performance of Pontoon-Type Floating BreakwaterDocument6 pagesNumerical Study On The Effect of Mooring Line Stiffness On Hydrodynamic Performance of Pontoon-Type Floating Breakwatermostafa shahrabiNo ratings yet
- Outliers in Time Series DataDocument8 pagesOutliers in Time Series DataJalluNo ratings yet
- Neet Full Test - 1Document16 pagesNeet Full Test - 1ANUP MOHAPATRANo ratings yet
- PAPER 2222 With Mark AnswersDocument16 pagesPAPER 2222 With Mark AnswersAbhijeet GholapNo ratings yet
- Physics Class Xii Sample Paper 01 For 2019 20 1Document6 pagesPhysics Class Xii Sample Paper 01 For 2019 20 1dick kumarNo ratings yet
- SBGF 2011 RJ Doriansmallpdf - Com-2Document6 pagesSBGF 2011 RJ Doriansmallpdf - Com-2Roberto de Jesús Domínguez HernándezNo ratings yet
- Print - Final - End Semester SPDocument2 pagesPrint - Final - End Semester SPom prakash vermaNo ratings yet
- Linear Programming 1 PDFDocument4 pagesLinear Programming 1 PDFmikeNo ratings yet
- CE6012Document2 pagesCE6012venkatraman20No ratings yet
- AFFILIATIONDocument1 pageAFFILIATIONvenkatraman20No ratings yet
- Civil Dept - Student DetailsDocument12 pagesCivil Dept - Student Detailsvenkatraman20No ratings yet
- Land Filling in MSWDocument83 pagesLand Filling in MSWvenkatraman20No ratings yet
- Iv Yr Agri - CMDocument10 pagesIv Yr Agri - CMvenkatraman20No ratings yet
- Book 3Document1 pageBook 3venkatraman20No ratings yet
- 7th Sem PDFDocument1 page7th Sem PDFvenkatraman20No ratings yet
- Drip Irrigation SystemDocument1 pageDrip Irrigation Systemvenkatraman20No ratings yet
- Ae Me 9 Gs Answer KeyDocument1 pageAe Me 9 Gs Answer Keyvenkatraman20No ratings yet
- Tnsssrules PDFDocument91 pagesTnsssrules PDFSelvaraj Villy0% (1)
- Anna University:: Chennai - 600 025: Office of The Controller of ExaminationsDocument15 pagesAnna University:: Chennai - 600 025: Office of The Controller of Examinationsvenkatraman20No ratings yet
- Zaidi 2015Document44 pagesZaidi 2015venkatraman20No ratings yet
- P.S.R. Group of Institutions: Sivakasi - 626 140, Virudhunagar Dist. TamilnaduDocument2 pagesP.S.R. Group of Institutions: Sivakasi - 626 140, Virudhunagar Dist. Tamilnaduvenkatraman20No ratings yet
- 7th Sem PDFDocument1 page7th Sem PDFvenkatraman20No ratings yet
- Centroid SDocument1 pageCentroid Svenkatraman20No ratings yet
- 7th SemDocument1 page7th Semvenkatraman20No ratings yet
- Syllabus Copy Course Introduction & Course PlanDocument3 pagesSyllabus Copy Course Introduction & Course Planvenkatraman20No ratings yet
- Shapes Images Area: Centroids of Common ShapesDocument4 pagesShapes Images Area: Centroids of Common Shapesharilal9285100% (1)
- 1 Matlab IntroDocument21 pages1 Matlab IntroankursonicivilNo ratings yet
- Design Project2014 - 2018Document7 pagesDesign Project2014 - 2018venkatraman20No ratings yet
- Department of Civil Engineering IV YEAR - A Section (Batch 2015-2019)Document6 pagesDepartment of Civil Engineering IV YEAR - A Section (Batch 2015-2019)venkatraman20No ratings yet
- Bhatt 2014Document18 pagesBhatt 2014venkatraman20No ratings yet
- Geoscience Frontiers: B.P. Ganasri, H. RameshDocument9 pagesGeoscience Frontiers: B.P. Ganasri, H. Rameshvenkatraman20No ratings yet
- Geoscience Frontiers: B.P. Ganasri, H. RameshDocument9 pagesGeoscience Frontiers: B.P. Ganasri, H. Rameshvenkatraman20No ratings yet
- Department of Civil Engineering Laboratory ManualDocument8 pagesDepartment of Civil Engineering Laboratory Manualvenkatraman20No ratings yet
- Module-1: Lecture 1.2-Tutorial Problem: Name Math Programming Thermodynamics MechanicsDocument1 pageModule-1: Lecture 1.2-Tutorial Problem: Name Math Programming Thermodynamics Mechanicsvenkatraman20No ratings yet
- Hydraulics Lab RubricsDocument7 pagesHydraulics Lab Rubricsvenkatraman200% (1)
- Hydrological Inferences From Watershed Analysis For Water Resource Management Using Remote Sensing and GIS TechniquesDocument11 pagesHydrological Inferences From Watershed Analysis For Water Resource Management Using Remote Sensing and GIS Techniquesvenkatraman20No ratings yet
- Evaluation of Automatic Drainage Extraction Thresholds Using ASTER GDEM and Cartosat-1 DEM: A Case Study From Basaltic Terrain of Central IndiaDocument10 pagesEvaluation of Automatic Drainage Extraction Thresholds Using ASTER GDEM and Cartosat-1 DEM: A Case Study From Basaltic Terrain of Central Indiavenkatraman20No ratings yet
- Car 1Document3 pagesCar 1VipinGuptaNo ratings yet
- An Innovative DNA Cryptography Technique For Secure Data TransmissionDocument46 pagesAn Innovative DNA Cryptography Technique For Secure Data TransmissiondevNo ratings yet
- Chapter 03 Us 7eDocument46 pagesChapter 03 Us 7eMuhammad SaefiNo ratings yet
- PTSP 2 Marks Questions Unit IDocument2 pagesPTSP 2 Marks Questions Unit IramanaNo ratings yet
- Bagging, BoostingDocument32 pagesBagging, Boostinglassijassi100% (1)
- Chap 2 Two Variable Regression AnalysisDocument18 pagesChap 2 Two Variable Regression AnalysisSamina AhmeddinNo ratings yet
- Dac & AdcDocument108 pagesDac & AdcG RAJESHNo ratings yet
- Group 1Document37 pagesGroup 1Christian Felix GuevarraNo ratings yet
- Vigenere AttackDocument13 pagesVigenere AttacksaqibmubarakNo ratings yet
- Decision Making Under Uncertainty-AMRITAS-1Document45 pagesDecision Making Under Uncertainty-AMRITAS-1Arijit DasNo ratings yet
- Model Risk ForrestDocument15 pagesModel Risk ForrestjeevithaNo ratings yet
- Sri Bestari International School: Christie Kong Pui Ching Year 7 Einstein 4 1:25pm - 2:05pmDocument3 pagesSri Bestari International School: Christie Kong Pui Ching Year 7 Einstein 4 1:25pm - 2:05pmChristie Kong Pui ChingNo ratings yet
- Static and Dynamic ModelsDocument6 pagesStatic and Dynamic ModelsNadiya Mushtaq100% (1)
- Greedy Solution To The Fractional Knapsack ProbDocument3 pagesGreedy Solution To The Fractional Knapsack Probapi-3844034No ratings yet
- Question 1: Bezier Quadratic Curve Successive Linear Interpolation EquationDocument4 pagesQuestion 1: Bezier Quadratic Curve Successive Linear Interpolation Equationaushad3mNo ratings yet
- Variational Mode Decomposition and Decision Tree Based Detection and Classification of Power Quality Disturbances in Grid-Connected Distributed Generation SystemDocument11 pagesVariational Mode Decomposition and Decision Tree Based Detection and Classification of Power Quality Disturbances in Grid-Connected Distributed Generation Systemrupa surekhaNo ratings yet
- Adaptive Learning-Based K-Nearest Neighbor Classifiers With Resilience To Class ImbalanceDocument17 pagesAdaptive Learning-Based K-Nearest Neighbor Classifiers With Resilience To Class ImbalanceAyushNo ratings yet
- Simplex Method FlowchartDocument2 pagesSimplex Method FlowchartRezaNo ratings yet
- CS - 701 Artificial IntelligenceDocument4 pagesCS - 701 Artificial IntelligenceManish SinghNo ratings yet
- Coding Round TechgigMagicServDocument6 pagesCoding Round TechgigMagicServnishantgaurav23No ratings yet
- Adaptive Differential PCM: by Dr.R.Hemalatha, ASP/ECEDocument10 pagesAdaptive Differential PCM: by Dr.R.Hemalatha, ASP/ECEthevin arokiarajNo ratings yet
- Lab Sheet 5 Discrete Fourier Transform (DFT) Using MATLABDocument16 pagesLab Sheet 5 Discrete Fourier Transform (DFT) Using MATLABSharmin RiniNo ratings yet
- Solenoid ValveDocument20 pagesSolenoid ValveMayur GaidhaneNo ratings yet
- Thera Bank-ProjectDocument26 pagesThera Bank-Projectpratik zanke100% (12)
- Chapter 7 - An Introduction To Portfolio ManagementDocument23 pagesChapter 7 - An Introduction To Portfolio ManagementImejah FaviNo ratings yet
- Fruits & Vegetable Classification and Calories Measurement SystemDocument2 pagesFruits & Vegetable Classification and Calories Measurement SystemNationalinstituteDsnrNo ratings yet
- Evan Marie Carr - Python and SKlearnDocument32 pagesEvan Marie Carr - Python and SKlearnEvan Marie CarrNo ratings yet
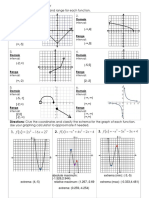
- Directions: Find The Domain and Range For Each FunctionDocument3 pagesDirections: Find The Domain and Range For Each FunctionKayla IkumaNo ratings yet
- Questions On LaplaceDocument4 pagesQuestions On LaplaceApam BenjaminNo ratings yet
- Advanced Process Control of A B-9 Permasep@ Permeator Desalination Pilot Plant. Burden. 2000. DesalinationDocument13 pagesAdvanced Process Control of A B-9 Permasep@ Permeator Desalination Pilot Plant. Burden. 2000. DesalinationEdgar HuancaNo ratings yet