You might also like
- Hypothesis TestingDocument93 pagesHypothesis Testingmonerch JoserNo ratings yet
- Open Channel FlowDocument34 pagesOpen Channel Flowjss_devNo ratings yet
- Unit 3 (SAMPLE AND SAMPLE DISTRIBUTIONS)Document32 pagesUnit 3 (SAMPLE AND SAMPLE DISTRIBUTIONS)Zara Nabilah100% (2)
- IB Math HL NotesDocument19 pagesIB Math HL NotesDevbrat Hariyani100% (1)
- Slides2 RevisedDocument24 pagesSlides2 RevisedTalvany Luis de BarrosNo ratings yet
- F-BachDocument36 pagesF-BachGS SINDHUNo ratings yet
- Basic Statistical ConceptsDocument14 pagesBasic Statistical ConceptsVedha ThangavelNo ratings yet
- Online Learning: 9.520 Class 12, 20 March 2006 Andrea Caponnetto, Sanmay DasDocument33 pagesOnline Learning: 9.520 Class 12, 20 March 2006 Andrea Caponnetto, Sanmay DasHabib MradNo ratings yet
- Ranking Problems: 9.520 Class 09, 08 March 2006 Giorgos ZachariaDocument27 pagesRanking Problems: 9.520 Class 09, 08 March 2006 Giorgos ZachariaHabib MradNo ratings yet
- Section 6 - Projection Pursuit RegressionDocument23 pagesSection 6 - Projection Pursuit RegressionPeper12345No ratings yet
- THE LINE AND THE TRANSLATE PROPERTIES FOR r-PRIMITIVE ELEMENTSDocument29 pagesTHE LINE AND THE TRANSLATE PROPERTIES FOR r-PRIMITIVE ELEMENTSGiorgos KapetanakisNo ratings yet
- Chap TokkoDocument62 pagesChap TokkojalatadanbalNo ratings yet
- ACT6100 A2020 Sup 12Document37 pagesACT6100 A2020 Sup 12lebesguesNo ratings yet
- CH 1Document24 pagesCH 1reema alnafisiNo ratings yet
- Mathematical Association of AmericaDocument11 pagesMathematical Association of AmericathonguyenNo ratings yet
- Intro To Bayes Approach. Reasons To Be Bayesian: Differences Between Bayesian and Frequentist Approaches 1Document9 pagesIntro To Bayes Approach. Reasons To Be Bayesian: Differences Between Bayesian and Frequentist Approaches 1DevendraReddyPoreddyNo ratings yet
- Massachusetts Institute of Technology: 6.867 Machine Learning, Fall 2006 Problem Set 3: SolutionsDocument3 pagesMassachusetts Institute of Technology: 6.867 Machine Learning, Fall 2006 Problem Set 3: Solutionsjuanagallardo01No ratings yet
- Lec9 3Document7 pagesLec9 3manoj reddyNo ratings yet
- Machine Learning and Data Mining: Prof. Alexander IhlerDocument46 pagesMachine Learning and Data Mining: Prof. Alexander IhleroriontherecluseNo ratings yet
- Turn in Recitation and Tutorial Scheduling Form Policy: TextDocument52 pagesTurn in Recitation and Tutorial Scheduling Form Policy: TextQasim KhanNo ratings yet
- MSM780 2021 StabilityVonNeumannDocument16 pagesMSM780 2021 StabilityVonNeumannMitchell WhitingNo ratings yet
- Stat231 Final Formula SheetDocument15 pagesStat231 Final Formula SheetVazylNo ratings yet
- An Orthogonality Property of Legendre Polynomials: ResearchDocument13 pagesAn Orthogonality Property of Legendre Polynomials: ResearchRivaldo Cifuentes MonroyNo ratings yet
- Maths Revision DPP No 5Document8 pagesMaths Revision DPP No 5Praphul Pulkit GiriNo ratings yet
- Apuntes, Raices - Cos323 - f12 - Lecture02 - RootfindingDocument33 pagesApuntes, Raices - Cos323 - f12 - Lecture02 - RootfindingcmfariaNo ratings yet
- NUMETHSDocument67 pagesNUMETHSmeggaiNo ratings yet
- CEU Probability1 Solutions05 2013fallDocument2 pagesCEU Probability1 Solutions05 2013fallRoberto Antonio Rojas EstebanNo ratings yet
- Lesson6 Functions04Document11 pagesLesson6 Functions04Anonymous SpyNo ratings yet
- Statistics G6105: Probability: Professor Philip Protter 1029 SSWDocument18 pagesStatistics G6105: Probability: Professor Philip Protter 1029 SSWmehdiNo ratings yet
- Statistical Methods NotesDocument9 pagesStatistical Methods NotesDennis Uygur AnderssonNo ratings yet
- Sequence Alignment: Lecture 2, Thursday April 3, 2003Document38 pagesSequence Alignment: Lecture 2, Thursday April 3, 2003missnathiNo ratings yet
- Exercise 1Document4 pagesExercise 1Khalil El LejriNo ratings yet
- EM Algorithm: Shu-Ching Chang Hyung Jin Kim December 9, 2007Document10 pagesEM Algorithm: Shu-Ching Chang Hyung Jin Kim December 9, 2007Tomislav PetrušijevićNo ratings yet
- Trig Functions II - March 7thDocument22 pagesTrig Functions II - March 7thMissConnellNo ratings yet
- Stat6201 ch3-1Document4 pagesStat6201 ch3-1BowenYangNo ratings yet
- Taller 3 (A. NG.) - Introducción Al Aprendizaje SupervisadoDocument8 pagesTaller 3 (A. NG.) - Introducción Al Aprendizaje SupervisadoangieNo ratings yet
- Week02 Lecture BBDocument64 pagesWeek02 Lecture BBAlice XiaoNo ratings yet
- ReportDocument18 pagesReportKiran RavyNo ratings yet
- Logistic RegressionDocument19 pagesLogistic Regressionsarah alinaNo ratings yet
- Linearization and Newton's MethodDocument21 pagesLinearization and Newton's MethodbluewaterlilyNo ratings yet
- Mathgen 93432634Document14 pagesMathgen 93432634weaweaNo ratings yet
- Vibrations and WavesDocument125 pagesVibrations and WavesGika NurdianaNo ratings yet
- Distributed Optimization Via Alternating Direction Method of MultipliersDocument23 pagesDistributed Optimization Via Alternating Direction Method of MultipliersTHuy DvNo ratings yet
- Function Theory 2Document10 pagesFunction Theory 2Praveen Kumar JhaNo ratings yet
- Mark's Formula Sheet For Exam PDocument1 pageMark's Formula Sheet For Exam PSiba MohapatraNo ratings yet
- Statistical Estimation: - Maximum Likelihood Estimation - Optimal Detector Design - Experiment DesignDocument15 pagesStatistical Estimation: - Maximum Likelihood Estimation - Optimal Detector Design - Experiment Designdmp130No ratings yet
- WorkedExample CauchyDocument3 pagesWorkedExample CauchyMuhammad Taurif RasyidinNo ratings yet
- Pertemuan 2 Kalkulus 2Document8 pagesPertemuan 2 Kalkulus 2Monica Angelina NaibahoNo ratings yet
- FariaJameel 2497 16587 7 Lecture 8Document48 pagesFariaJameel 2497 16587 7 Lecture 8Jawad BhuttoNo ratings yet
- CQF ML Lab Estimating Default Probability With Logistic RegressionDocument7 pagesCQF ML Lab Estimating Default Probability With Logistic RegressionAndy willNo ratings yet
- M100 Prac 1Document2 pagesM100 Prac 1Eric ZhangNo ratings yet
- "01 Euler and ζ(s) " - Paul Garrett (2015)Document8 pages"01 Euler and ζ(s) " - Paul Garrett (2015)Jordan BlevinsNo ratings yet
- Numerical IntegrationDocument28 pagesNumerical IntegrationVincentLiangNo ratings yet
- Exercise Signal Processing 5Document21 pagesExercise Signal Processing 5Max PieriniNo ratings yet
- Module 3 - Critical PointsDocument19 pagesModule 3 - Critical PointsMaddyyyNo ratings yet
- EE-411: Digital Signal Processing - : Problem 1Document2 pagesEE-411: Digital Signal Processing - : Problem 1Qasim FarooqNo ratings yet
- 112 FinalreviewDocument10 pages112 FinalreviewfjjffjfjfjfjfjfjNo ratings yet
- Simulation Models in Industrial Engineering: Random-Variate GenerationDocument18 pagesSimulation Models in Industrial Engineering: Random-Variate GenerationManhNo ratings yet
- Support Vector MachinesDocument22 pagesSupport Vector Machinesshyed shahriarNo ratings yet
- Lec 2Document31 pagesLec 2asasdNo ratings yet
- SampleQs Solutions PDFDocument20 pagesSampleQs Solutions PDFBasiru IbrahimNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Tables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesFrom EverandTables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesNo ratings yet
- ch8 Steady Incompressible Flow in Pressure Conduits (Partb) PDFDocument66 pagesch8 Steady Incompressible Flow in Pressure Conduits (Partb) PDFnaefmubarak0% (1)
- Chapter 4 EORDocument115 pagesChapter 4 EORHidayahSazli100% (1)
- Steady Incompressible Flow in Pressure Conduits (PartB)Document21 pagesSteady Incompressible Flow in Pressure Conduits (PartB)naefmubarakNo ratings yet
- Class09 Ex1Document2 pagesClass09 Ex1naefmubarakNo ratings yet
- IMEX Product OverviewDocument2 pagesIMEX Product OverviewnaefmubarakNo ratings yet
- Well Test - 2Document14 pagesWell Test - 2naefmubarak100% (1)
- TPG4145 2008 InformationDocument4 pagesTPG4145 2008 InformationnaefmubarakNo ratings yet
- 4 Field Lab EquipmentDocument19 pages4 Field Lab EquipmentnaefmubarakNo ratings yet
- Me19b Hw3 SolutionsDocument7 pagesMe19b Hw3 SolutionsnaefmubarakNo ratings yet
- 2008 TPG4145 Lecture Notes UpdateDocument66 pages2008 TPG4145 Lecture Notes UpdatenaefmubarakNo ratings yet
- PETE311 06A Class17Document16 pagesPETE311 06A Class17naefmubarakNo ratings yet
- Project ManagementDocument57 pagesProject ManagementnaefmubarakNo ratings yet
- Well Test - 2006Document48 pagesWell Test - 2006naefmubarakNo ratings yet
- Notes From PETE 620 RTDocument121 pagesNotes From PETE 620 RTnaefmubarakNo ratings yet
- P306 91C HW 09Document10 pagesP306 91C HW 09naefmubarakNo ratings yet
- Pete603 10Document21 pagesPete603 10naefmubarakNo ratings yet
- P306 91C Ex 01 PDFDocument23 pagesP306 91C Ex 01 PDFnaefmubarakNo ratings yet
- P306 91C HW 01Document1 pageP306 91C HW 01naefmubarakNo ratings yet
- P306 91C HW 09Document10 pagesP306 91C HW 09naefmubarakNo ratings yet
- P306 91C Ex 01 PDFDocument23 pagesP306 91C Ex 01 PDFnaefmubarakNo ratings yet
- Flow in Channels and Fractures Analogies To Darcy's LawDocument11 pagesFlow in Channels and Fractures Analogies To Darcy's LawnaefmubarakNo ratings yet
- Notes From PETE P620 KRDocument157 pagesNotes From PETE P620 KRnaefmubarakNo ratings yet
- ARPS Effect of Temp On Density and Electrical Resistivity of Sodium Chloride SolutionsDocument4 pagesARPS Effect of Temp On Density and Electrical Resistivity of Sodium Chloride SolutionsnaefmubarakNo ratings yet
- PETE311 06A Class24Document13 pagesPETE311 06A Class24naefmubarakNo ratings yet
- PETE311 06A Class15Document12 pagesPETE311 06A Class15naefmubarakNo ratings yet
- PETE311 06A Class29Document9 pagesPETE311 06A Class29naefmubarakNo ratings yet
- PETE311 06A Class06 (Maggard)Document17 pagesPETE311 06A Class06 (Maggard)Unflagging1983No ratings yet
- Input Data: Water-Oil System:: Ro RW WDocument1 pageInput Data: Water-Oil System:: Ro RW WAhmed RaafatNo ratings yet
- Two and Three-Parameter Weibull Distribution in Available Wind Power AnalysisDocument15 pagesTwo and Three-Parameter Weibull Distribution in Available Wind Power AnalysisRoajs SofNo ratings yet
- Neural Voice Cloning With A Few Samples: February 2018Document17 pagesNeural Voice Cloning With A Few Samples: February 2018Suvedhya ReddyNo ratings yet
- ON "Marketing Layout and Strategy in Oil and Natural Gas Corporation-Ongc"Document35 pagesON "Marketing Layout and Strategy in Oil and Natural Gas Corporation-Ongc"shyamNo ratings yet
- Bcm-106/Bc-02: O Kolkf D Lkaf ( DH VKSJ XF - Kr@O Kolkf D Lkaf ( DHDocument11 pagesBcm-106/Bc-02: O Kolkf D Lkaf ( DH VKSJ XF - Kr@O Kolkf D Lkaf ( DHAbhishek Kumar SharmaNo ratings yet
- Model Prediction of Defects in Sheet Metal Forming ProcessesDocument12 pagesModel Prediction of Defects in Sheet Metal Forming Processeschandra jemyNo ratings yet
- Session 1 Forecasting: Advanced Management AccountingDocument40 pagesSession 1 Forecasting: Advanced Management AccountingmrhuggalumpsNo ratings yet
- Skittles AssignmentDocument8 pagesSkittles Assignmentapi-291800396No ratings yet
- Smcs QuestionsDocument5 pagesSmcs QuestionsDeepak SangrohaNo ratings yet
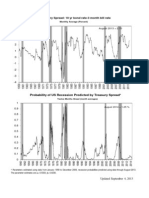
- Probability of US Recession Predicted by Treasury SpreadDocument1 pageProbability of US Recession Predicted by Treasury Spreadmustafa-ahmedNo ratings yet
- Chapter 1 5 in PRDocument15 pagesChapter 1 5 in PRSheldon RamadaNo ratings yet
- Amreen HandicraftDocument66 pagesAmreen Handicraftajay sharmaNo ratings yet
- Where To Study Maths UKDocument8 pagesWhere To Study Maths UKMike AntonyNo ratings yet
- BusStat W02 Hypothesis TestDocument18 pagesBusStat W02 Hypothesis TestStevie SeanNo ratings yet
- The Kolmogorov Smirnov One Sample TestDocument13 pagesThe Kolmogorov Smirnov One Sample TestLito LarinoNo ratings yet
- Nature of StatisticsDocument63 pagesNature of StatisticsMa. Karyl Ashrivelle CarreonNo ratings yet
- Why Is The One-Group Pretest-Posttest Design Still UsedDocument6 pagesWhy Is The One-Group Pretest-Posttest Design Still UsedsuhaNo ratings yet
- Gcse Statistics Coursework SampleDocument5 pagesGcse Statistics Coursework Samplef5b2q8e3100% (2)
- QMRB EnglischDocument58 pagesQMRB EnglischMariyappanNo ratings yet
- Macgregor 1976Document30 pagesMacgregor 1976BenjaminNo ratings yet
- Eligibility of Village Fund Direct Cash Assistance Recipients Using Artificial Neural NetworkDocument8 pagesEligibility of Village Fund Direct Cash Assistance Recipients Using Artificial Neural NetworkIAES IJAINo ratings yet
- Zapata Full ThesisDocument257 pagesZapata Full ThesisTantai RakthaijungNo ratings yet
- Transport StatisticsDocument10 pagesTransport StatisticsfrankNo ratings yet
- Angeles University FoundationDocument26 pagesAngeles University FoundationRance LacsonNo ratings yet
- Chapter 3. Decision Theory: ObjectiveDocument26 pagesChapter 3. Decision Theory: ObjectiveThien TranNo ratings yet
- D5536-94 (2010) Standard Practice For Sampling Forest Trees For Determination of Clear Wood PropertiesDocument9 pagesD5536-94 (2010) Standard Practice For Sampling Forest Trees For Determination of Clear Wood PropertiesRony YudaNo ratings yet
- G7 Math 7 Exam 4thDocument7 pagesG7 Math 7 Exam 4thMyra Ramirez RamosNo ratings yet
- Needleman-Wunsch and Smith-Waterman AlgorithmDocument19 pagesNeedleman-Wunsch and Smith-Waterman Algorithmgayu_positive67% (9)
- 1Document4 pages1someoneelses0% (1)