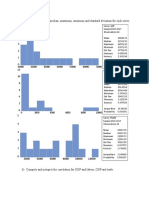
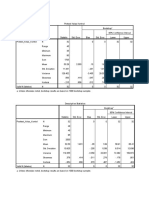
You might also like
- Group Assignment Hi6007 StatiticsDocument21 pagesGroup Assignment Hi6007 Statiticschris100% (3)
- HW5 2023Document5 pagesHW5 2023writersleedNo ratings yet
- Business Statistics DAPDocument19 pagesBusiness Statistics DAPBhanupratap SisodiyaNo ratings yet
- Stats AgainDocument4 pagesStats AgainJericoh TicgueNo ratings yet
- Data Set Final 2Document908 pagesData Set Final 2arber hasaNo ratings yet
- APDQ - 02211940000190 - Ma'ruf Bintang Dwi CahyoDocument18 pagesAPDQ - 02211940000190 - Ma'ruf Bintang Dwi CahyoMa'ruf BintangdwicahyoNo ratings yet
- Out Put Tugas Pertemuan 2 MondariDocument6 pagesOut Put Tugas Pertemuan 2 MondariMuhammad Naufal fauzanNo ratings yet
- Hasil Uji Eviwes 12&9Document6 pagesHasil Uji Eviwes 12&9Vivi KrisdayantiNo ratings yet
- AssignmDocument10 pagesAssignmAmedorme WisdomNo ratings yet
- RIVERA ECE11 Laboratory Exercise 3Document3 pagesRIVERA ECE11 Laboratory Exercise 3Ehron RiveraNo ratings yet
- Btquant1 Sol 2010Document5 pagesBtquant1 Sol 2010ANa TrầnNo ratings yet
- Pretest Kelas IVA Pretest Kelas IVB Postest Kelas IVA Postest Kelas IVBDocument7 pagesPretest Kelas IVA Pretest Kelas IVB Postest Kelas IVA Postest Kelas IVBbennyNo ratings yet
- Lincolnville Schoold District Bus Data AliDocument23 pagesLincolnville Schoold District Bus Data AlialiNo ratings yet
- Descriptives: Descriptive StatisticsDocument10 pagesDescriptives: Descriptive StatisticsNovi MuspitaNo ratings yet
- Rajat Kapoor Assignment No. 5 8102Document7 pagesRajat Kapoor Assignment No. 5 8102kapoorrajat859500No ratings yet
- PCP-Disso-v3: % Release (Average With Flux) )Document36 pagesPCP-Disso-v3: % Release (Average With Flux) )amitkhobragade100% (2)
- Descriptive Statistics of Kotak Mahindra BankDocument1 pageDescriptive Statistics of Kotak Mahindra BankKollapudi HemanthkumarNo ratings yet
- SPSS HanaDocument2 pagesSPSS HanaNurfadila YusufNo ratings yet
- Lab 10Document3 pagesLab 10kyle_palmer_18No ratings yet
- Column1 Column2Document3 pagesColumn1 Column2Shilpi ShroffNo ratings yet
- Abm1 Abm2 Abm3 Abm4 Tvl1Document1 pageAbm1 Abm2 Abm3 Abm4 Tvl1Vic FranciscoNo ratings yet
- Young Professional MagazineDocument6 pagesYoung Professional MagazinePhalit GuptaNo ratings yet
- Forecasts Worksheet: (Tài-chính-Quán-cà-phê-5.xlsx) TÀI CHÍNH Forecast: NPV Cell: C199Document39 pagesForecasts Worksheet: (Tài-chính-Quán-cà-phê-5.xlsx) TÀI CHÍNH Forecast: NPV Cell: C199Yennhi MaiNo ratings yet
- Sales Price List Price: 1. Gulf View CondominiumsDocument9 pagesSales Price List Price: 1. Gulf View CondominiumsLeslie OpokuNo ratings yet
- Business Statistics ProfessionalDocument8 pagesBusiness Statistics ProfessionalMohit VaidyaNo ratings yet
- Z TestDocument2 pagesZ TestSumit GuptaNo ratings yet
- (STATS) WordDocument7 pages(STATS) WordRIYA RIYANo ratings yet
- Descriptive Analytics AssignmentDocument23 pagesDescriptive Analytics Assignmentswapnajit mukherjeeNo ratings yet
- Nomor 2 UAS 200533628063 - Naufal ArliandoDocument3 pagesNomor 2 UAS 200533628063 - Naufal ArliandoArliando NaufalNo ratings yet
- Laboratory Exercise2Document4 pagesLaboratory Exercise2alia fauniNo ratings yet
- Simple Multiple Regression (Taking All Scale Variable) : DescriptivesDocument26 pagesSimple Multiple Regression (Taking All Scale Variable) : Descriptivesrao saadNo ratings yet
- Final POM Arrangement 2Document5 pagesFinal POM Arrangement 2Samuel kwateiNo ratings yet
- Car Price ($) Cost/ Mile Road-Test Score Predicted Reliability Value ScoreDocument23 pagesCar Price ($) Cost/ Mile Road-Test Score Predicted Reliability Value ScoreShubham PalNo ratings yet
- Analytical Chem Lab 1Document9 pagesAnalytical Chem Lab 1Raja GokhulNo ratings yet
- Tutorial 12Document9 pagesTutorial 12HENG QUAN PANNo ratings yet
- NO Model Pembalajaran TPS TTW TstsDocument4 pagesNO Model Pembalajaran TPS TTW TstsMarlydTalakuaNo ratings yet
- Hasil SpssDocument10 pagesHasil Spssbidan amanahNo ratings yet
- ICFAI University, Dehradun: Student Name Iud No Ibs NoDocument9 pagesICFAI University, Dehradun: Student Name Iud No Ibs Nochetan2787No ratings yet
- Case Processing SummaryDocument3 pagesCase Processing SummaryNadzar Canggih HendroNo ratings yet
- Explore: Case Processing SummaryDocument12 pagesExplore: Case Processing SummaryPrajoko SusiloNo ratings yet
- Before:: Case Processing SummaryDocument10 pagesBefore:: Case Processing SummaryZain Hameed FastNUNo ratings yet
- Part 2A: About TheDocument9 pagesPart 2A: About TheSanju VisuNo ratings yet
- Gulf Real Estate Properties Case StudyDocument10 pagesGulf Real Estate Properties Case StudyADITYA VERMANo ratings yet
- Pretest Kelas KontrolDocument4 pagesPretest Kelas KontrolNurfadila YusufNo ratings yet
- Analisis GranulDocument90 pagesAnalisis GranulPiece AdnanNo ratings yet
- R Linear 0.961 R Quadratic 0.989 R2 Cubic 0.991Document7 pagesR Linear 0.961 R Quadratic 0.989 R2 Cubic 0.991Sasini PethumikaNo ratings yet
- QBA Assignment Report (1) 123Document6 pagesQBA Assignment Report (1) 123dakshith gowdaNo ratings yet
- Base de Datos Kuiper AnalisisDocument121 pagesBase de Datos Kuiper Analisisllama a casaNo ratings yet
- Stats Assignment in ExcelDocument19 pagesStats Assignment in ExcelMohammedNo ratings yet
- Statistik JilidDocument25 pagesStatistik Jilidrisda hanifa rahmanNo ratings yet
- Fundamentals of DATA Analysis: Chapter 2 - Descriptive Statistics Question No. 45Document7 pagesFundamentals of DATA Analysis: Chapter 2 - Descriptive Statistics Question No. 45Kushagra SinghNo ratings yet
- RIVERA ECE11 Laboratory Exercise 3Document3 pagesRIVERA ECE11 Laboratory Exercise 3Ehron RiveraNo ratings yet
- Output Data SPSS: Case Processing SummaryDocument12 pagesOutput Data SPSS: Case Processing Summaryweni karuniaNo ratings yet
- Project Economatrics Excel Work FFCDocument4 pagesProject Economatrics Excel Work FFCaqsarana ranaNo ratings yet
- Exact 3, X 3 at Least 3, X 3 at Most 3, X 3 Between 5 and 9, 5 X 9Document4 pagesExact 3, X 3 at Least 3, X 3 at Most 3, X 3 Between 5 and 9, 5 X 9Ehron RiveraNo ratings yet
- Oup 8Document36 pagesOup 8TAMIZHAN ANo ratings yet
- Local Tuition Starting SalaryDocument4 pagesLocal Tuition Starting SalaryJames HamiltonNo ratings yet
- Q.1 Compare The Two Types of Colleges. What Can U Conclude?: Top 10% HSDocument1 pageQ.1 Compare The Two Types of Colleges. What Can U Conclude?: Top 10% HSCt NaziHahNo ratings yet
- Input ValuesDocument121 pagesInput Valuesapi-27160411No ratings yet
- Large Deviations for Gaussian Queues: Modelling Communication NetworksFrom EverandLarge Deviations for Gaussian Queues: Modelling Communication NetworksNo ratings yet
- The Impact of Facilities On Student'S Academic AchievementDocument13 pagesThe Impact of Facilities On Student'S Academic AchievementCute AkoNo ratings yet
- Yitagesu TachibeleDocument28 pagesYitagesu TachibeleNebawNo ratings yet
- w5 PDFDocument11 pagesw5 PDFNoven VillaberNo ratings yet
- Spss Tutorial Guide CompleteDocument34 pagesSpss Tutorial Guide CompleteJoemar TarlitNo ratings yet
- JaniceNew Chapter 4-5Document53 pagesJaniceNew Chapter 4-5Janice MantiquillaNo ratings yet
- Agilent Cary 8454 UV-Visible Spectroscopy System: Good Laboratory PracticeDocument12 pagesAgilent Cary 8454 UV-Visible Spectroscopy System: Good Laboratory PracticeTho AnhNo ratings yet
- Ayala - Parone - Finishpaper - 2019Document53 pagesAyala - Parone - Finishpaper - 2019Danica Dela CruzNo ratings yet
- To Adjust or Not Adjust Nonparametric Effect Sizes, Confidence Intervals, and Real-World Meaning PDFDocument7 pagesTo Adjust or Not Adjust Nonparametric Effect Sizes, Confidence Intervals, and Real-World Meaning PDFTodd MartinezNo ratings yet
- Pearson Correlation CoefficientDocument15 pagesPearson Correlation CoefficientEdwin B. Binongcal Jr.No ratings yet
- Vasicek A Series Expansion For The Bivariate Normal IntegralDocument13 pagesVasicek A Series Expansion For The Bivariate Normal IntegralginovainmonaNo ratings yet
- Employee Involvement and Organizational Performance: Evidence From The Manufacturing Sector in Republic of MacedoniaDocument6 pagesEmployee Involvement and Organizational Performance: Evidence From The Manufacturing Sector in Republic of MacedoniaPutrii AmbaraNo ratings yet
- Sample Size Calculation For Two Independent Groups: A Useful Rule of ThumbDocument4 pagesSample Size Calculation For Two Independent Groups: A Useful Rule of ThumbabdeljelileNo ratings yet
- Academic - Udayton.edu-Using SPSS For T-TestsDocument13 pagesAcademic - Udayton.edu-Using SPSS For T-TestsDarkAster12No ratings yet
- Assstment of GlovesDocument344 pagesAssstment of GlovesAsanka SandakelumNo ratings yet
- Biomedical Signal Processing and ControlDocument6 pagesBiomedical Signal Processing and ControlIntan Alwaystry TobehappyNo ratings yet
- 1 s2.0 S1877042814001876 MainDocument3 pages1 s2.0 S1877042814001876 MainClémentine AresNo ratings yet
- Influence of Competitive Strategy On Competitive Advantage in Toyota KenyaDocument15 pagesInfluence of Competitive Strategy On Competitive Advantage in Toyota Kenyarust IfalianaNo ratings yet
- Case Study - Risk & ReturnDocument6 pagesCase Study - Risk & ReturnSomyaNo ratings yet
- Spearman RhoDocument26 pagesSpearman Rhozirromz68750% (1)
- The Contribution of Tourism To Socio-Economic Development: Myth or Reality?Document29 pagesThe Contribution of Tourism To Socio-Economic Development: Myth or Reality?Ken ReyesNo ratings yet
- Evaluation of Glucose Oxidase and Hexokinase MethodsDocument8 pagesEvaluation of Glucose Oxidase and Hexokinase MethodsPojangNo ratings yet
- Management Innovation and Business Performance of Micro, Small, and Medium Enterprises in Cotabato City During The COVID-19 PandemicDocument9 pagesManagement Innovation and Business Performance of Micro, Small, and Medium Enterprises in Cotabato City During The COVID-19 PandemicThe IjbmtNo ratings yet
- De La Salle University - Dasmariñas: Graduate ProgramDocument23 pagesDe La Salle University - Dasmariñas: Graduate ProgramRuby De GranoNo ratings yet
- 1 s2.0 S2588840419300708 MainDocument8 pages1 s2.0 S2588840419300708 MainVIRAJ PATILNo ratings yet
- Del Corro-Tiangco: 34 July - December 2014Document14 pagesDel Corro-Tiangco: 34 July - December 2014Donna PaañoNo ratings yet
- 7 QC TOOLS PPT Everest Industries LimitedDocument70 pages7 QC TOOLS PPT Everest Industries LimitedDeepakvanguri100% (2)
- Comparison of Drought Indices in A Semi-Arid River Basin of IndiaDocument28 pagesComparison of Drought Indices in A Semi-Arid River Basin of IndiaPawan WableNo ratings yet
- 60% Navraj SirDocument45 pages60% Navraj SirPrasiddha PradhanNo ratings yet
- Senior High School Students Attitudein Research Writingandtheir Academic PerformanceDocument21 pagesSenior High School Students Attitudein Research Writingandtheir Academic PerformanceVincent DelimaNo ratings yet
- RESEARCH PROPOSAL About FREE EDUCATIONDocument29 pagesRESEARCH PROPOSAL About FREE EDUCATIONDievine leami100% (2)