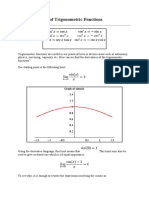
You might also like
- Week012 ModuleDocument12 pagesWeek012 ModuleAKIRA HarashiNo ratings yet
- Scientific Computation (COMS 3210) Bigass Study Guide: Spring 2012Document30 pagesScientific Computation (COMS 3210) Bigass Study Guide: Spring 2012David CohenNo ratings yet
- MITOCW - Ocw-18-01-F07-Lec15 - 300k: ProfessorDocument9 pagesMITOCW - Ocw-18-01-F07-Lec15 - 300k: Professornk4everNo ratings yet
- Linear System Modeling A Single Degree of Freedom OscillatorDocument23 pagesLinear System Modeling A Single Degree of Freedom OscillatorCristian AnghelNo ratings yet
- QdbkvD4N UsDocument17 pagesQdbkvD4N UsTheoNo ratings yet
- The Derivatives of Trigonometric FunctionsDocument29 pagesThe Derivatives of Trigonometric FunctionsM Arifin RasdhakimNo ratings yet
- L27jvpzoz yDocument17 pagesL27jvpzoz yBastian DewiNo ratings yet
- MITOCW - MITRES2 - 002s10linear - Lec02 - 300k-mp4: ProfessorDocument21 pagesMITOCW - MITRES2 - 002s10linear - Lec02 - 300k-mp4: ProfessorDanielNo ratings yet
- MITOCW - MITRES2 - 002s10linear - Lec11 - 300k-mp4: ProfessorDocument18 pagesMITOCW - MITRES2 - 002s10linear - Lec11 - 300k-mp4: ProfessorDanielNo ratings yet
- Lec 33Document11 pagesLec 33shailiayushNo ratings yet
- Lec 26Document27 pagesLec 26salimNo ratings yet
- Tips and Tricks in Real Analysis: Nate Eldredge August 3, 2008Document5 pagesTips and Tricks in Real Analysis: Nate Eldredge August 3, 2008Zainul HurmainNo ratings yet
- lPz7VFnKI PDFDocument9 pageslPz7VFnKI PDFnk4everNo ratings yet
- MITOCW - MITRES - 6-007s11lec03 - 300k.mp4: ProfessorDocument16 pagesMITOCW - MITRES - 6-007s11lec03 - 300k.mp4: ProfessorsivatejamundlamuriNo ratings yet
- "Newton's Method and Loops": University of Karbala College of Engineering Petroleum Eng. DepDocument11 pages"Newton's Method and Loops": University of Karbala College of Engineering Petroleum Eng. DepAli MahmoudNo ratings yet
- Lec 13Document13 pagesLec 13shailiayushNo ratings yet
- Lec 39Document32 pagesLec 39Sueja MalligwadNo ratings yet
- Real NumbersDocument125 pagesReal NumbersVernon MonteiroNo ratings yet
- eHJuAByQf5A PDFDocument13 pageseHJuAByQf5A PDFHello It's MeNo ratings yet
- Instructor (Brad Osgood) :does Somebody Know - Don't You Occasionally Get BadDocument10 pagesInstructor (Brad Osgood) :does Somebody Know - Don't You Occasionally Get BadElisée NdjabuNo ratings yet
- Sequence of FucntionsDocument15 pagesSequence of Fucntionskishalay sarkarNo ratings yet
- Lagrange's Equations PDFDocument26 pagesLagrange's Equations PDFDebkanta DasNo ratings yet
- Lec 80Document29 pagesLec 80anupriyaaaNo ratings yet
- MITOCW - MITRES2 - 002s10linear - Lec08 - 300k-mp4: ProfessorDocument16 pagesMITOCW - MITRES2 - 002s10linear - Lec08 - 300k-mp4: ProfessorDanielNo ratings yet
- Finite Element Analysis Prof. Dr. B. N. Rao Department of Civil Engineering Indian Institute of Technology, MadrasDocument40 pagesFinite Element Analysis Prof. Dr. B. N. Rao Department of Civil Engineering Indian Institute of Technology, MadrasMarijaNo ratings yet
- Classical Mechanics: From Newtonian To Lagrangian FormulationDocument9 pagesClassical Mechanics: From Newtonian To Lagrangian Formulationchirag jainNo ratings yet
- Lec 34Document12 pagesLec 34shailiayushNo ratings yet
- Mathematics-I Prof. S.K. Ray Department of Mathematics and Statistics Indian Institute of Technology, Kanpur Lecture - 2 SequencesDocument24 pagesMathematics-I Prof. S.K. Ray Department of Mathematics and Statistics Indian Institute of Technology, Kanpur Lecture - 2 Sequencesjayaram prakash kNo ratings yet
- MITOCW - MITRES2 - 002s10linear - Lec12 - 300k-mp4: ProfessorDocument21 pagesMITOCW - MITRES2 - 002s10linear - Lec12 - 300k-mp4: ProfessorDanielNo ratings yet
- PKM K Usaha Jamur Crispy KriukDocument17 pagesPKM K Usaha Jamur Crispy Kriukraihan riadhyNo ratings yet
- Instructor (Brad Osgood) :hey. Jesus. Man, I Just Back and I'm Tired. and WelcomeDocument11 pagesInstructor (Brad Osgood) :hey. Jesus. Man, I Just Back and I'm Tired. and WelcomeElisée NdjabuNo ratings yet
- Lec 5Document33 pagesLec 5shipraNo ratings yet
- Instructor (Brad Osgood) :there We Go. All Right, The Exams - Remember The Exams? IDocument10 pagesInstructor (Brad Osgood) :there We Go. All Right, The Exams - Remember The Exams? IElisée NdjabuNo ratings yet
- MITOCW - Ocw-18-01-F07-Lec01 - 300k: ProfessorDocument11 pagesMITOCW - Ocw-18-01-F07-Lec01 - 300k: ProfessorMuhammad AzamNo ratings yet
- Lec 30Document12 pagesLec 30Jitendra GurjarNo ratings yet
- MITOCW - MITRES - 18-007 - Part3 - Lec5 - 300k.mp4: ProfessorDocument12 pagesMITOCW - MITRES - 18-007 - Part3 - Lec5 - 300k.mp4: Professorfrank_grimesNo ratings yet
- Lec 35Document18 pagesLec 35Win Alfalah NasutionNo ratings yet
- Lec10 PDFDocument23 pagesLec10 PDFsuntararaajanNo ratings yet
- Mitocw - Watch?V 4wsmeqckpgi: Barton ZwiebachDocument23 pagesMitocw - Watch?V 4wsmeqckpgi: Barton ZwiebachdeependrasinghjadounNo ratings yet
- Instructor (Brad Osgood) : Here We Go. All Right. The Exams, You Remember The ExamsDocument10 pagesInstructor (Brad Osgood) : Here We Go. All Right. The Exams, You Remember The ExamsElisée NdjabuNo ratings yet
- Lec 3Document28 pagesLec 3shubhamNo ratings yet
- 4q37io 1Document12 pages4q37io 1Vinayak JhaNo ratings yet
- Calculus I - Related RatesDocument15 pagesCalculus I - Related Rateswag2325No ratings yet
- Introduction To Finite Element Method Dr. R. Krishnakumar Department of Mechanical Engineering Indian Institute of Technology, Madras Lecture - 19Document23 pagesIntroduction To Finite Element Method Dr. R. Krishnakumar Department of Mechanical Engineering Indian Institute of Technology, Madras Lecture - 19mahendranNo ratings yet
- Lec 12Document12 pagesLec 12shailiayushNo ratings yet
- Mathematical InductionDocument17 pagesMathematical InductionJayaram BhueNo ratings yet
- Lec 43Document10 pagesLec 43sixfacerajNo ratings yet
- Nptel 1 PDFDocument23 pagesNptel 1 PDFBiplove PokhrelNo ratings yet
- Instructor (Brad Osgood) :okay. Let Me Circulate, Starting Over This Side of The RoomDocument15 pagesInstructor (Brad Osgood) :okay. Let Me Circulate, Starting Over This Side of The RoomNi PeterNo ratings yet
- Functional Analysis Prof. P. D. Srivastava Department of Mathematics Indian Institute of Technology, KharagpurDocument15 pagesFunctional Analysis Prof. P. D. Srivastava Department of Mathematics Indian Institute of Technology, KharagpurKofi Appiah-DanquahNo ratings yet
- MITOCW - MITRES2 - 002s10nonlinear - Lec05 - 300k-mp4: ProfessorDocument19 pagesMITOCW - MITRES2 - 002s10nonlinear - Lec05 - 300k-mp4: ProfessorBastian DewiNo ratings yet
- Lesson 4Document58 pagesLesson 4Md Kaiser HamidNo ratings yet
- 03 - 3 1 3 B The Space of Bandlimited Functions - enDocument2 pages03 - 3 1 3 B The Space of Bandlimited Functions - enAbulSayeedDoulahNo ratings yet
- Instructor (Brad Osgood) :are We On? I Can't See. It Looks Kinda Dark. I Don't Know. ItDocument12 pagesInstructor (Brad Osgood) :are We On? I Can't See. It Looks Kinda Dark. I Don't Know. ItElisée NdjabuNo ratings yet
- Newton Raphson MethodDocument23 pagesNewton Raphson Methodsumaiyakter1311No ratings yet
- MITOCW - MITRES - 18-007 - Part3 - Lec6 - 300k.mp4: ProfessorDocument12 pagesMITOCW - MITRES - 18-007 - Part3 - Lec6 - 300k.mp4: Professorgaur1234No ratings yet
- 4.1 Solution of Algebraic and Transcendental Equations: Bisection MethodDocument10 pages4.1 Solution of Algebraic and Transcendental Equations: Bisection MethodDileep kumarNo ratings yet
- Lec 6Document22 pagesLec 6Srikar ArcheryNo ratings yet
- MITOCW - MITRES - 18-007 - Part2 - Lec1 - 300k.mp4: ProfessorDocument16 pagesMITOCW - MITRES - 18-007 - Part2 - Lec1 - 300k.mp4: Professorfrank_grimesNo ratings yet
- MITOCW - MITRES2 - 002s10nonlinear - Lec12 - 300k-mp4: NarratorDocument16 pagesMITOCW - MITRES2 - 002s10nonlinear - Lec12 - 300k-mp4: NarratorBastian DewiNo ratings yet
- MITOCW - MITRES2 - 002s10nonlinear - Lec13 - 300k-mp4: ProfessorDocument17 pagesMITOCW - MITRES2 - 002s10nonlinear - Lec13 - 300k-mp4: ProfessorBastian DewiNo ratings yet
- MITOCW - MITRES2 - 002s10nonlinear - Lec11 - 300k-mp4: ProfessorDocument15 pagesMITOCW - MITRES2 - 002s10nonlinear - Lec11 - 300k-mp4: ProfessorBastian DewiNo ratings yet
- MITOCW - MITRES2 - 002s10nonlinear - Lec09 - 300k-mp4: ProfessorDocument13 pagesMITOCW - MITRES2 - 002s10nonlinear - Lec09 - 300k-mp4: ProfessorBastian DewiNo ratings yet
- MITOCW - MITRES2 - 002s10nonlinear - Lec05 - 300k-mp4: ProfessorDocument19 pagesMITOCW - MITRES2 - 002s10nonlinear - Lec05 - 300k-mp4: ProfessorBastian DewiNo ratings yet
- L27jvpzoz yDocument17 pagesL27jvpzoz yBastian DewiNo ratings yet
- Clamp - Sheet1 PDFDocument1 pageClamp - Sheet1 PDFBastian DewiNo ratings yet
- Plat Atas - Sheet1Document1 pagePlat Atas - Sheet1Bastian DewiNo ratings yet
- QHADocument82 pagesQHABastian DewiNo ratings yet
- Clamp - Sheet1Document1 pageClamp - Sheet1Bastian DewiNo ratings yet
- Performance of 2d Frame OptimizationDocument21 pagesPerformance of 2d Frame OptimizationBastian DewiNo ratings yet
- AssignmentDocument3 pagesAssignmentWesen LegesseNo ratings yet
- Convergence PropertiesDocument9 pagesConvergence PropertiessumathyNo ratings yet
- v1 Quiz 3 PDFDocument2 pagesv1 Quiz 3 PDFParam Veer ChoudharyNo ratings yet
- Matrices Over ZDocument3 pagesMatrices Over Zalok pradhanNo ratings yet
- Mathematical Tripos Part IA: at The End of The ExaminationDocument8 pagesMathematical Tripos Part IA: at The End of The ExaminationOscarNo ratings yet
- Kolam DesignsDocument21 pagesKolam DesignsSri Kumar60% (5)
- (Universitext) Elmer G. Rees (Auth.) - Notes On Geometry-Springer-Verlag Berlin Heidelberg (1983)Document118 pages(Universitext) Elmer G. Rees (Auth.) - Notes On Geometry-Springer-Verlag Berlin Heidelberg (1983)library gcpeshawar0% (3)
- Chapter 8 (Complex Numbers)Document8 pagesChapter 8 (Complex Numbers)Naledi MashishiNo ratings yet
- PPSC Lecturer Mathematics 2004Document1 pagePPSC Lecturer Mathematics 2004Sadia ahmadNo ratings yet
- Chapter 2 Matrices MATV101 UpdatedDocument35 pagesChapter 2 Matrices MATV101 Updated1jabujohnshibambo12No ratings yet
- Emtl 5 Units ProblemsDocument110 pagesEmtl 5 Units ProblemsTharun konda100% (2)
- MAT 211, Spring 2012 Solutions To Homework Assignment 9Document5 pagesMAT 211, Spring 2012 Solutions To Homework Assignment 9okeNo ratings yet
- Math 1554 Worksheets Distance Fall 2018 PDFDocument178 pagesMath 1554 Worksheets Distance Fall 2018 PDFLuke PearceNo ratings yet
- (Ir (NLL: A Robust Gmres-Based Adaptive Polynomial Preconditioning Algorithm For Nonsymmetric Linear JouberttDocument13 pages(Ir (NLL: A Robust Gmres-Based Adaptive Polynomial Preconditioning Algorithm For Nonsymmetric Linear JouberttaabbNo ratings yet
- IntegrationDocument104 pagesIntegrationPratham MalhotraNo ratings yet
- 2018 - Stability Analysis and Stabilization Methods of DC Microgrid With Multiple Parallel-Connected DC-DC Converters Loaded by CPLsDocument11 pages2018 - Stability Analysis and Stabilization Methods of DC Microgrid With Multiple Parallel-Connected DC-DC Converters Loaded by CPLsRahul ChakrabortyNo ratings yet
- Lec5 & 6 Imaging GeometryDocument35 pagesLec5 & 6 Imaging Geometryume habibaNo ratings yet
- Matrix Det 1Document16 pagesMatrix Det 1QwertyNo ratings yet
- Slides VectorAnalysisDocument65 pagesSlides VectorAnalysisTrideeb BhattacharyaNo ratings yet
- Vol. 11, No. 2 (2020) H. 217-229: Jurnal Pendidikan Matematika Dan IpaDocument13 pagesVol. 11, No. 2 (2020) H. 217-229: Jurnal Pendidikan Matematika Dan IpaDustin AzelartNo ratings yet
- BPHCT 141Document6 pagesBPHCT 141viploveNo ratings yet
- Homework 2 QuestionsDocument6 pagesHomework 2 QuestionsSUPRIYA MADDELANo ratings yet
- Further Mathematics Teaching NotesDocument2 pagesFurther Mathematics Teaching NotesZoran IvanovskiNo ratings yet
- Vectors Graphical & Analytical MethodsDocument47 pagesVectors Graphical & Analytical MethodsJean Bataanon CallejoNo ratings yet
- Engineering MathematicsDocument3 pagesEngineering MathematicsgopichandallakaNo ratings yet
- Question Bank On Determinants & MatrixDocument12 pagesQuestion Bank On Determinants & MatrixShivam Jaggi100% (6)
- Linear Algebra - Intuitive Math1Document3 pagesLinear Algebra - Intuitive Math1Sumanth GowdaNo ratings yet
- The Theory of Matrices by P. Lancaster and M. TismenetskyDocument292 pagesThe Theory of Matrices by P. Lancaster and M. TismenetskyzakwanaslamNo ratings yet
- PSD MatricesDocument2 pagesPSD Matricesfatihy73No ratings yet
- MATH-243 Vector Calculus: Line IntegralsDocument22 pagesMATH-243 Vector Calculus: Line IntegralsWaleed ZafarNo ratings yet
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.From EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Rating: 5 out of 5 stars5/5 (1)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsFrom EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsRating: 4.5 out of 5 stars4.5/5 (3)
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingFrom EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingRating: 4.5 out of 5 stars4.5/5 (21)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeFrom EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeRating: 4 out of 5 stars4/5 (2)
- ParaPro Assessment Preparation 2023-2024: Study Guide with 300 Practice Questions and Answers for the ETS Praxis Test (Paraprofessional Exam Prep)From EverandParaPro Assessment Preparation 2023-2024: Study Guide with 300 Practice Questions and Answers for the ETS Praxis Test (Paraprofessional Exam Prep)No ratings yet
- Images of Mathematics Viewed Through Number, Algebra, and GeometryFrom EverandImages of Mathematics Viewed Through Number, Algebra, and GeometryNo ratings yet
- Calculus Workbook For Dummies with Online PracticeFrom EverandCalculus Workbook For Dummies with Online PracticeRating: 3.5 out of 5 stars3.5/5 (8)
- How Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsFrom EverandHow Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsRating: 3.5 out of 5 stars3.5/5 (9)
- Magic Multiplication: Discover the Ultimate Formula for Fast MultiplicationFrom EverandMagic Multiplication: Discover the Ultimate Formula for Fast MultiplicationNo ratings yet
- Mental Math Secrets - How To Be a Human CalculatorFrom EverandMental Math Secrets - How To Be a Human CalculatorRating: 5 out of 5 stars5/5 (3)
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldFrom EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldRating: 3 out of 5 stars3/5 (80)
- Applied Predictive Modeling: An Overview of Applied Predictive ModelingFrom EverandApplied Predictive Modeling: An Overview of Applied Predictive ModelingNo ratings yet
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)From EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)No ratings yet
- A Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathFrom EverandA Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathRating: 5 out of 5 stars5/5 (1)
- Who Tells the Truth?: Collection of Logical Puzzles to Make You ThinkFrom EverandWho Tells the Truth?: Collection of Logical Puzzles to Make You ThinkRating: 5 out of 5 stars5/5 (1)