You might also like
- Unit IiiDocument27 pagesUnit IiiDr. R. K. Selvakesavan PSGRKCWNo ratings yet
- Genomics AssignmentDocument13 pagesGenomics AssignmentMuhammad kamran khanNo ratings yet
- Blast and Fasta algorithms explainedDocument28 pagesBlast and Fasta algorithms explaineddevbaljinderNo ratings yet
- BlastDocument18 pagesBlastJhilik PathakNo ratings yet
- Sequence Alignment Methods and ApplicationsDocument5 pagesSequence Alignment Methods and ApplicationsGopi ShankarNo ratings yet
- FASTADocument4 pagesFASTADhakshayani GNo ratings yet
- Blast Vs FastaDocument3 pagesBlast Vs FastaAhmad Faraz KhanNo ratings yet
- 04B. Bioinformatics-Lecture 4 (Alternative) - BlastDocument38 pages04B. Bioinformatics-Lecture 4 (Alternative) - BlastLinhNguyeNo ratings yet
- B1 BioinfoDocument7 pagesB1 BioinfoJohn Kent0% (1)
- Sequence Analysis - AlignmentDocument57 pagesSequence Analysis - Alignmentfilson.riyadiNo ratings yet
- Fasta Sequence DatabaseDocument17 pagesFasta Sequence DatabaseKlevis XhyraNo ratings yet
- BLAST TITLEDocument33 pagesBLAST TITLERohan RayNo ratings yet
- 1 - Sequence Alignment and VisualizationDocument68 pages1 - Sequence Alignment and VisualizationAlisha100% (1)
- Lecture2022 - 3 /!Document60 pagesLecture2022 - 3 /!MAnugrahRizkyPNo ratings yet
- Sequence DB SearchDocument38 pagesSequence DB SearchAyesha KhanNo ratings yet
- Multiple Sequence AlignmentDocument89 pagesMultiple Sequence AlignmentMeowNo ratings yet
- FASTA - A Fast Homology Search ToolDocument26 pagesFASTA - A Fast Homology Search ToolMalik FhaimNo ratings yet
- Notes BioinformaticsDocument14 pagesNotes BioinformaticsfreelancerhamzaabbasiNo ratings yet
- Sequence Analysis in BioinformaticsDocument18 pagesSequence Analysis in BioinformaticsBhaskar ChatterjeeNo ratings yet
- Lecture 4: Blast: Ly Le, PHDDocument60 pagesLecture 4: Blast: Ly Le, PHDLinhNguyeNo ratings yet
- 02.-Sequence Analysis PDFDocument14 pages02.-Sequence Analysis PDFAlexander Martínez PasekNo ratings yet
- Bioinformatics: Blast and Sequence AnalysisDocument45 pagesBioinformatics: Blast and Sequence AnalysisSalix MattNo ratings yet
- Multiple Sequence Alignment MSADocument8 pagesMultiple Sequence Alignment MSAAnonymous nUiP53SNo ratings yet
- Lecture 3 and 4 LSM2241Document6 pagesLecture 3 and 4 LSM2241Koh Yen SinNo ratings yet
- Dr. Zoya Khalid Zoya - Khalid@nu - Edu.pkDocument51 pagesDr. Zoya Khalid Zoya - Khalid@nu - Edu.pkAyesha KhanNo ratings yet
- BLAST Glossary With HighlightsDocument9 pagesBLAST Glossary With Highlightsimran47No ratings yet
- BlastDocument12 pagesBlastjincyNo ratings yet
- Database Searching Techniques for Gene Identification and ClassificationDocument47 pagesDatabase Searching Techniques for Gene Identification and ClassificationMeowNo ratings yet
- 6 BlastpDocument1 page6 BlastpDicky John Davis GNo ratings yet
- Methods For Applying Multiple Sequence AlignmentDocument17 pagesMethods For Applying Multiple Sequence AlignmentacezeeshanNo ratings yet
- Sequence Alignments: Felix Sappelt Irina WagnerDocument34 pagesSequence Alignments: Felix Sappelt Irina WagnerFelix Spacebook100% (1)
- Introduction To Bioinformatics: Sequence AlignmentDocument29 pagesIntroduction To Bioinformatics: Sequence AlignmentranjankumartiwariNo ratings yet
- Blast 2 Sequences: Salman Khan Current Gpa in Bioinf 4 GpaDocument45 pagesBlast 2 Sequences: Salman Khan Current Gpa in Bioinf 4 GpaXâlmañ KháñNo ratings yet
- MsaDocument28 pagesMsaMausam KumravatNo ratings yet
- Sequence Analysis - Pairwise AlignmentDocument26 pagesSequence Analysis - Pairwise AlignmentAnjana's WorldNo ratings yet
- Basic Local Alignment Search ToolDocument8 pagesBasic Local Alignment Search ToolfacefaceNo ratings yet
- Need & Emergence of The Field: Speaker Shashi Shekhar Head of Computational Section Biowits Life SciencesDocument59 pagesNeed & Emergence of The Field: Speaker Shashi Shekhar Head of Computational Section Biowits Life SciencesIma kuro-bikeNo ratings yet
- Difference between local and global alignmentDocument6 pagesDifference between local and global alignmentGum Naam SingerNo ratings yet
- Chapter 2 BioinformaticsDocument9 pagesChapter 2 BioinformaticsKaiash M YNo ratings yet
- Selecting the Right Similarity-Scoring MatrixDocument18 pagesSelecting the Right Similarity-Scoring Matrixderickh72jNo ratings yet
- New Sequence Alignment Algorithm Using Ai Rules and Dynamic SeedsDocument14 pagesNew Sequence Alignment Algorithm Using Ai Rules and Dynamic SeedsbioejNo ratings yet
- BLAST and FASTA algorithms for sequence alignmentDocument10 pagesBLAST and FASTA algorithms for sequence alignmentMousami SrivastavaNo ratings yet
- Blast Analisis IIDocument15 pagesBlast Analisis IIUlises Ortiz GutierrezNo ratings yet
- BlastDocument21 pagesBlastSathish KumarNo ratings yet
- FALLSEM2022-23 BIT3001 ETH VL2022230101828 Reference Material II 08-09-2022 7algorithms For Sequence ComprisonsDocument39 pagesFALLSEM2022-23 BIT3001 ETH VL2022230101828 Reference Material II 08-09-2022 7algorithms For Sequence ComprisonsTriparna PoddarNo ratings yet
- Introduction To Bioinformatics Lecture 3Document20 pagesIntroduction To Bioinformatics Lecture 3HaMmAd KhAnNo ratings yet
- Multiple Sequence AlignmentsDocument9 pagesMultiple Sequence Alignmentsvanigo1824No ratings yet
- BLASTDocument4 pagesBLASTdia320576No ratings yet
- Alignments & Phylogenetic Trees: Introduction to Sequence AlignmentDocument18 pagesAlignments & Phylogenetic Trees: Introduction to Sequence AlignmentSevs LorillaNo ratings yet
- Sequence Alignment: InterpretationDocument8 pagesSequence Alignment: InterpretationdahiyatejNo ratings yet
- Lec06 MPH46 5103Document21 pagesLec06 MPH46 5103Sabith Hasan Khan JoyNo ratings yet
- Presentation 2Document14 pagesPresentation 2abash_u1No ratings yet
- Multiple Seq AlignmentDocument36 pagesMultiple Seq AlignmentAnwar AliNo ratings yet
- Blast 2 S, A New Tool For Comparing Protein and Nucleotide SequencesDocument4 pagesBlast 2 S, A New Tool For Comparing Protein and Nucleotide SequencesXâlmañ KháñNo ratings yet
- Summary Bioinformation TechnologyDocument15 pagesSummary Bioinformation TechnologytjNo ratings yet
- Sequence Alignment: Scoring MatricesDocument30 pagesSequence Alignment: Scoring MatricesSparsh NegiNo ratings yet
- Blast ClustalDocument87 pagesBlast ClustalalexdexterNo ratings yet
- Multiple Biological Sequence Alignment: Scoring Functions, Algorithms and EvaluationFrom EverandMultiple Biological Sequence Alignment: Scoring Functions, Algorithms and EvaluationNo ratings yet
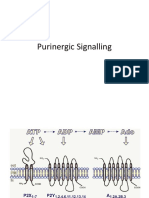
- Purinergic SignallingDocument4 pagesPurinergic SignallingsadhanaaNo ratings yet
- Origins of Circulating Endothelial Cells and Endothelial Outgrowth from Blood CulturesDocument7 pagesOrigins of Circulating Endothelial Cells and Endothelial Outgrowth from Blood CulturessadhanaaNo ratings yet
- Unit2 3Document43 pagesUnit2 3sadhanaaNo ratings yet
- Unit2 4Document13 pagesUnit2 4sadhanaaNo ratings yet
- Unit2 4Document13 pagesUnit2 4sadhanaaNo ratings yet
- Unit 1Document18 pagesUnit 1sadhanaaNo ratings yet
- Unit2 3Document43 pagesUnit2 3sadhanaaNo ratings yet
- Atomic Force MicroscopeDocument3 pagesAtomic Force MicroscopesadhanaaNo ratings yet
- Basic Length and Time Scales in Cells and MoleculesDocument20 pagesBasic Length and Time Scales in Cells and MoleculesSanthoshi Sadhanaa SankarNo ratings yet
- Tamil Nadu & Puducherry Current Affairs 2016 (Jan-Nov) by AffairsCloudDocument27 pagesTamil Nadu & Puducherry Current Affairs 2016 (Jan-Nov) by AffairsCloudsadhanaaNo ratings yet
- Sec 1 Question BankDocument6 pagesSec 1 Question BankMohmed H. El-saiedNo ratings yet
- Research - Proposal FinalDocument11 pagesResearch - Proposal FinalAhsan AshrafNo ratings yet
- Genome SequencingDocument21 pagesGenome SequencingBalraj RandhawaNo ratings yet
- Dynamic ProgrammingDocument28 pagesDynamic Programminginfamous0218No ratings yet
- Teks MC Training RevisiDocument2 pagesTeks MC Training RevisiMuhamad Wawan DarmawanNo ratings yet
- 2 Cladograms - BioNinjaDocument5 pages2 Cladograms - BioNinjaRosie SunNo ratings yet
- Bioinformatics Week 1: Play Video Starting At:4:13 and Follow Transcript4:13Document7 pagesBioinformatics Week 1: Play Video Starting At:4:13 and Follow Transcript4:13SawDust pH IndicatorNo ratings yet
- DNA Data Bank of JapanDocument2 pagesDNA Data Bank of Japanmcdonald212No ratings yet
- Computational Biology and Applied BioinformaticsDocument456 pagesComputational Biology and Applied Bioinformaticsnaveenbioinformatics75% (4)
- Sequence Alignment Algorithms: DEKM Book Notes From Dr. Bino John and Dr. Takis BenosDocument53 pagesSequence Alignment Algorithms: DEKM Book Notes From Dr. Bino John and Dr. Takis BenosAashutosh SharmaNo ratings yet
- Sequence File FormatsDocument22 pagesSequence File FormatsPragya MukherjeeNo ratings yet
- Find Similar Sequences FAST with BLASTDocument6 pagesFind Similar Sequences FAST with BLASTSupriyo ChatterjeeNo ratings yet
- Bioinformatics Quiz: Test Your Knowledge of BioinformaticsDocument16 pagesBioinformatics Quiz: Test Your Knowledge of Bioinformaticsnaveenbioinfo56% (18)
- Lab Guide For StudentDocument28 pagesLab Guide For Studentศรุตยา คงบวรเกียรติNo ratings yet
- BFG Chapter1 Introduction v03Document26 pagesBFG Chapter1 Introduction v03Paolo NaguitNo ratings yet
- UnigeneDocument7 pagesUnigeneNandni JhaNo ratings yet
- BC BioinformaticsToolsDocument29 pagesBC BioinformaticsToolsHaris QurashiNo ratings yet
- Gap Penalty - WikipediaDocument6 pagesGap Penalty - WikipediaABHINABA GUPTANo ratings yet
- Bioinformatics: Introduction and Methods Week 3 Sequence Database SearchDocument5 pagesBioinformatics: Introduction and Methods Week 3 Sequence Database SearchchahoubNo ratings yet
- Molecular Phylogenetic Analysis Methods and ApplicationsDocument35 pagesMolecular Phylogenetic Analysis Methods and ApplicationsDipanjan RayNo ratings yet
- PROBLEM SET 1. Sequence Search, Global Alignment, BLAST StatisticsDocument10 pagesPROBLEM SET 1. Sequence Search, Global Alignment, BLAST StatisticsnataphonicNo ratings yet
- BTT302 - Ktu QbankDocument6 pagesBTT302 - Ktu QbankAnn JohnNo ratings yet
- Homology Modeling Technique for Protein Structure PredictionDocument19 pagesHomology Modeling Technique for Protein Structure PredictionJainendra JainNo ratings yet
- Metagenomics - Remove Host SequencesDocument1 pageMetagenomics - Remove Host SequencesemilioNo ratings yet
- Appreciation of Computing in Different FieldsDocument7 pagesAppreciation of Computing in Different FieldsPauline Bogador MayordomoNo ratings yet
- Dual Degree L 2015Document139 pagesDual Degree L 2015anirudhNo ratings yet
- Biology For Engineers: Introduction to BioinformaticsDocument13 pagesBiology For Engineers: Introduction to BioinformaticsUttkarsh SharmaNo ratings yet
- Bioinformatics Pipeline Explores Gene RegulationDocument18 pagesBioinformatics Pipeline Explores Gene RegulationHenrique MouraNo ratings yet
- Secondary Structure Protein Prediction ListDocument3 pagesSecondary Structure Protein Prediction ListSajjad Hossain ShuvoNo ratings yet
- BlastDocument21 pagesBlastSathish KumarNo ratings yet