You might also like
- Tentaive Date of Online Exams Tobe Published On Aai Website - 3 PDFDocument1 pageTentaive Date of Online Exams Tobe Published On Aai Website - 3 PDFAshutosh PandeyNo ratings yet
- Tul - TMP Juspay Report 2018 07 16Document400 pagesTul - TMP Juspay Report 2018 07 16Ella BhattacharyaNo ratings yet
- Control Systems Sample ChapterDocument22 pagesControl Systems Sample ChapterElla BhattacharyaNo ratings yet
- GATE Control Systems by KanodiaDocument97 pagesGATE Control Systems by Kanodiakaran11364% (11)
- Tul TMP Refund Report 2018-07-17Document82 pagesTul TMP Refund Report 2018-07-17Ella BhattacharyaNo ratings yet
- Tul - TMP Juspay Report 2018 07 16Document400 pagesTul - TMP Juspay Report 2018 07 16Ella BhattacharyaNo ratings yet
- Webinar Invite - 25 April v2Document32 pagesWebinar Invite - 25 April v2Ella BhattacharyaNo ratings yet
- Webinar Invite - 25 April v2Document1 pageWebinar Invite - 25 April v2Ella BhattacharyaNo ratings yet
- 10 PM Drop Roster G.park Dated On 09.07.2018Document30 pages10 PM Drop Roster G.park Dated On 09.07.2018Ella BhattacharyaNo ratings yet
- Drop Roster 09.00 PM - G.PARK - 12.07.2018Document22 pagesDrop Roster 09.00 PM - G.PARK - 12.07.2018Ella BhattacharyaNo ratings yet
- Drop Roster 09.00 PM - G.PARK - 12.07.2018Document22 pagesDrop Roster 09.00 PM - G.PARK - 12.07.2018Ella BhattacharyaNo ratings yet
- Drop Roster 09.00 PM - G.PARK - 02.07.2018Document20 pagesDrop Roster 09.00 PM - G.PARK - 02.07.2018Ella BhattacharyaNo ratings yet
- Drop Roster 08.00 PM - G.PARK - 28.06.2018Document53 pagesDrop Roster 08.00 PM - G.PARK - 28.06.2018Ella BhattacharyaNo ratings yet
- Drop Roster 09.00 PM - G.PARK - 02.07.2018Document20 pagesDrop Roster 09.00 PM - G.PARK - 02.07.2018Ella BhattacharyaNo ratings yet
- Airport Authority of India Recruitment Through GATE 2018 Official NotificationDocument7 pagesAirport Authority of India Recruitment Through GATE 2018 Official NotificationKshitijaNo ratings yet
- 12 13 3 2016 Sr. - Tech - AssistantDocument9 pages12 13 3 2016 Sr. - Tech - AssistantAmlan ChowdhuryNo ratings yet
- History (Hist) Class - XI: Theory-80 Marks Project-20 MarksDocument76 pagesHistory (Hist) Class - XI: Theory-80 Marks Project-20 MarksElla BhattacharyaNo ratings yet
- Drop Roster 08.00 PM - G.PARK - 22.06.2018Document52 pagesDrop Roster 08.00 PM - G.PARK - 22.06.2018Ella BhattacharyaNo ratings yet
- 10 PM Drop Roster G.park Dated On 21.06.2018Document32 pages10 PM Drop Roster G.park Dated On 21.06.2018Ella BhattacharyaNo ratings yet
- NEW PATTERN Quant SolutionsDocument2 pagesNEW PATTERN Quant SolutionsElla BhattacharyaNo ratings yet
- Study Plan SSC CGL 2018.PDF-63Document4 pagesStudy Plan SSC CGL 2018.PDF-63Ella BhattacharyaNo ratings yet
- Sangeeta N. Bhatia - WikipediaDocument17 pagesSangeeta N. Bhatia - WikipediaElla BhattacharyaNo ratings yet
- 50 Synnonyms QuestionsDocument8 pages50 Synnonyms QuestionsElla BhattacharyaNo ratings yet
- Webinar Invite - 25 April v2Document1 pageWebinar Invite - 25 April v2Ella BhattacharyaNo ratings yet
- Tul TMP Refund Report 2018-04-26Document22 pagesTul TMP Refund Report 2018-04-26Ella BhattacharyaNo ratings yet
- Study Plan SSC CGL 2018.PDF-63Document4 pagesStudy Plan SSC CGL 2018.PDF-63Ella BhattacharyaNo ratings yet
- Tul TMP Refund Report 2018-04-25Document22 pagesTul TMP Refund Report 2018-04-25Ella BhattacharyaNo ratings yet
- G.park Drop Roster 9.00pm Dated On 12.04.18Document14 pagesG.park Drop Roster 9.00pm Dated On 12.04.18Ella BhattacharyaNo ratings yet
- Drop Roster 09.00 PM - G.PARK - 23.04.2018Document14 pagesDrop Roster 09.00 PM - G.PARK - 23.04.2018Ella BhattacharyaNo ratings yet
- Drop Roster 08.00 PM - G.PARK - 24.04.2018Document23 pagesDrop Roster 08.00 PM - G.PARK - 24.04.2018Ella BhattacharyaNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Johns Hopkins University Press Is Collaborating With JSTOR To Digitize, Preserve and Extend Access To ELHDocument13 pagesJohns Hopkins University Press Is Collaborating With JSTOR To Digitize, Preserve and Extend Access To ELHAttila Lébényi-PalkovicsNo ratings yet
- DLL Week 5Document3 pagesDLL Week 5Nen CampNo ratings yet
- Elementary SurveyingDocument19 pagesElementary SurveyingJefferson EscobidoNo ratings yet
- Answers To Case Studies 1a - 2dDocument9 pagesAnswers To Case Studies 1a - 2dOgnen GaleskiNo ratings yet
- Creating Literacy Instruction For All Students ResourceDocument25 pagesCreating Literacy Instruction For All Students ResourceNicole RickettsNo ratings yet
- Impact of Micro FinanceDocument61 pagesImpact of Micro FinancePerry Arcilla SerapioNo ratings yet
- Paradigm Shift in Teaching: The Plight of Teachers, Coping Mechanisms and Productivity in The New Normal As Basis For Psychosocial SupportDocument5 pagesParadigm Shift in Teaching: The Plight of Teachers, Coping Mechanisms and Productivity in The New Normal As Basis For Psychosocial SupportPsychology and Education: A Multidisciplinary JournalNo ratings yet
- Broshure JepanDocument6 pagesBroshure JepanIrwan Mohd YusofNo ratings yet
- Introduction To E-Business SystemsDocument19 pagesIntroduction To E-Business SystemsArtur97% (79)
- Symbiosis National Aptitude Test (SNAP) 2004: InstructionsDocument21 pagesSymbiosis National Aptitude Test (SNAP) 2004: InstructionsHarsh JainNo ratings yet
- Endocrine System Unit ExamDocument3 pagesEndocrine System Unit ExamCHRISTINE JULIANENo ratings yet
- Mathematics - Grade 9 - First QuarterDocument9 pagesMathematics - Grade 9 - First QuarterSanty Enril Belardo Jr.No ratings yet
- Rizal ExaminationDocument3 pagesRizal ExaminationBea ChristineNo ratings yet
- Nin/Pmjay Id Name of The Vaccination Site Category Type District BlockDocument2 pagesNin/Pmjay Id Name of The Vaccination Site Category Type District BlockNikunja PadhanNo ratings yet
- What Are RussiaDocument3 pagesWhat Are RussiaMuhammad SufyanNo ratings yet
- Sta. Lucia National High School: Republic of The Philippines Region III-Central LuzonDocument7 pagesSta. Lucia National High School: Republic of The Philippines Region III-Central LuzonLee Charm SantosNo ratings yet
- Fascinating Numbers: Some Numbers of 3 Digits or More Exhibit A Very Interesting PropertyDocument2 pagesFascinating Numbers: Some Numbers of 3 Digits or More Exhibit A Very Interesting PropertyAnonymous JGW0KRl6No ratings yet
- PED100 Mod2Document3 pagesPED100 Mod2Risa BarritaNo ratings yet
- This Study Resource Was: Interactive Reading QuestionsDocument3 pagesThis Study Resource Was: Interactive Reading QuestionsJoshua LagonoyNo ratings yet
- Reading İzmir Culture Park Through Women S Experiences Matinee Practices in The 1970s Casino SpacesDocument222 pagesReading İzmir Culture Park Through Women S Experiences Matinee Practices in The 1970s Casino SpacesAta SagirogluNo ratings yet
- Sale Deed Document Rajyalakshmi, 2222222Document3 pagesSale Deed Document Rajyalakshmi, 2222222Madhav Reddy100% (2)
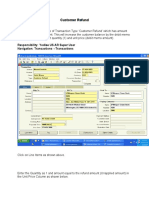
- Customer Refund: Responsibility: Yodlee US AR Super User Navigation: Transactions TransactionsDocument12 pagesCustomer Refund: Responsibility: Yodlee US AR Super User Navigation: Transactions TransactionsAziz KhanNo ratings yet
- Tamil Ilakkanam Books For TNPSCDocument113 pagesTamil Ilakkanam Books For TNPSCkk_kamalakkannan100% (1)
- Case - Marico SCMDocument26 pagesCase - Marico SCMChandan Gupta50% (2)
- Public BudgetingDocument15 pagesPublic BudgetingTom Wan Der100% (4)
- In Christ Alone My Hope Is FoundDocument9 pagesIn Christ Alone My Hope Is FoundJessie JessNo ratings yet
- Resume Testing6+ SaptagireswarDocument5 pagesResume Testing6+ SaptagireswarSuresh RamasamyNo ratings yet
- Life in The Past - Year 6 WorksheetsDocument11 pagesLife in The Past - Year 6 WorksheetstinaNo ratings yet
- Soal Midtest + Kunci JawabanDocument28 pagesSoal Midtest + Kunci JawabanYuyun RasulongNo ratings yet
- Jesus Christ Was A HinduDocument168 pagesJesus Christ Was A Hinduhbk22198783% (12)