You might also like
- On The Histories of Linear Algebra The Case of Linear SystemsDocument28 pagesOn The Histories of Linear Algebra The Case of Linear SystemsArnulfo Ariel Rios Aparicio100% (1)
- Handbook of Numerical Methods for the Solution of Algebraic and Transcendental EquationsFrom EverandHandbook of Numerical Methods for the Solution of Algebraic and Transcendental EquationsNo ratings yet
- Paper 1 Global Politics Writing GuideDocument8 pagesPaper 1 Global Politics Writing Guideminagoymen07No ratings yet
- Maths Book ListDocument16 pagesMaths Book ListKusumlata TomarNo ratings yet
- EE MCQ Web Preview Sample PagesDocument25 pagesEE MCQ Web Preview Sample PagesSoham ChatterjeeNo ratings yet
- Born This Way: Becoming, Being, and Understanding ScientistsFrom EverandBorn This Way: Becoming, Being, and Understanding ScientistsNo ratings yet
- Mathematics, Probability and Statistics, Applied Mathematics (6222 Titles)Document260 pagesMathematics, Probability and Statistics, Applied Mathematics (6222 Titles)Shan Thi80% (1)
- ECON6004: Intro to Numbers, Sets, and FunctionsDocument12 pagesECON6004: Intro to Numbers, Sets, and FunctionsSean WilliamsNo ratings yet
- Linear AlgebraDocument43 pagesLinear AlgebraKshitiz SinghalNo ratings yet
- Geometry and CombinatoricsDocument4 pagesGeometry and Combinatoricsmoka0687100% (1)
- de Moivres TheoremDocument18 pagesde Moivres TheoremAbdullah SaeedNo ratings yet
- Ted Draft) Logic For PhilosophersDocument284 pagesTed Draft) Logic For Philosopherssteven2235100% (1)
- 2020 Assessment 1 - Alternate Task Ext1 (William's Work) PDFDocument7 pages2020 Assessment 1 - Alternate Task Ext1 (William's Work) PDF黑剑No ratings yet
- Course 2 Unit 5Document98 pagesCourse 2 Unit 5amit aryaNo ratings yet
- Виллемсе И., Ниелисани П. Статистические методы и навыки расчетовDocument328 pagesВиллемсе И., Ниелисани П. Статистические методы и навыки расчетовНиколай Калашников100% (1)
- Theory of Probability. A Historical Essay.Document316 pagesTheory of Probability. A Historical Essay.rbrumaNo ratings yet
- Theoretical Computer Science An IntroductionDocument214 pagesTheoretical Computer Science An IntroductionJeremy HutchinsonNo ratings yet
- Linear Algebra - Bypaul DawkinsDocument343 pagesLinear Algebra - Bypaul Dawkinssd1642No ratings yet
- MATH 119 Spring 2022 Midterm SolutionsDocument14 pagesMATH 119 Spring 2022 Midterm Solutions이채연No ratings yet
- Ch07 Basic Knowledge Representation in First Order LogicDocument30 pagesCh07 Basic Knowledge Representation in First Order LogicICHSAN AL SABAH L100% (1)
- Chapter8 Matrices and Determinants: Advanced Level Pure MathematicsDocument37 pagesChapter8 Matrices and Determinants: Advanced Level Pure MathematicsKelvin Cheung100% (1)
- Mathematical Foundations of Computing NotesDocument379 pagesMathematical Foundations of Computing NoteswilltunaNo ratings yet
- Essentials MathDocument79 pagesEssentials MathNeil CorpuzNo ratings yet
- The Application of Mathematical Statistics to Chemical AnalysisFrom EverandThe Application of Mathematical Statistics to Chemical AnalysisNo ratings yet
- Exponential Worksheet1Document3 pagesExponential Worksheet1edren malaguenoNo ratings yet
- Symmetries and Laplacians: Introduction to Harmonic Analysis, Group Representations and ApplicationsFrom EverandSymmetries and Laplacians: Introduction to Harmonic Analysis, Group Representations and ApplicationsNo ratings yet
- Theory of Algebraic Integers (Cambridge Mathematical Library)Document167 pagesTheory of Algebraic Integers (Cambridge Mathematical Library)Anonymous QlJjisdlLINo ratings yet
- Math QuotesDocument15 pagesMath QuotesRichie BlasabasNo ratings yet
- Magic Table and Tower of Hanoi PuzzlesDocument8 pagesMagic Table and Tower of Hanoi PuzzlesNurul Jannah MokhtarNo ratings yet
- AP Human Geography: Teacher's GuideDocument125 pagesAP Human Geography: Teacher's GuideDominiqueAmorsoloNo ratings yet
- Incorrect Proofs and Mathematical InductionDocument34 pagesIncorrect Proofs and Mathematical InductionDKNo ratings yet
- Math 214 NotesDocument466 pagesMath 214 NotesLuis Javier IxtepanNo ratings yet
- Probability and Statistics CourseDocument129 pagesProbability and Statistics CourseFarah Najihah Sethjiha100% (1)
- Full SSG Ma214 Napostmidsem 201718Document267 pagesFull SSG Ma214 Napostmidsem 201718Tihid Reza100% (1)
- Numerical Methods for Differential Systems: Recent Developments in Algorithms, Software, and ApplicationsFrom EverandNumerical Methods for Differential Systems: Recent Developments in Algorithms, Software, and ApplicationsL. LapidusRating: 1 out of 5 stars1/5 (1)
- Stochastic Geometry and Its ApplicationsFrom EverandStochastic Geometry and Its ApplicationsRating: 3.5 out of 5 stars3.5/5 (1)
- Notes On Linear Algebra-Peter J CameronDocument124 pagesNotes On Linear Algebra-Peter J CameronAjay KumarNo ratings yet
- Morden Mathematical StatisticsDocument872 pagesMorden Mathematical Statisticsranaadhya100No ratings yet
- MIT 18.781 Theory of Numbers - Introduction to Number TheoryDocument5 pagesMIT 18.781 Theory of Numbers - Introduction to Number TheoryMartha EllisNo ratings yet
- XII STD - Statistics English MediumDocument280 pagesXII STD - Statistics English MediumSuvendu ChoudhuryNo ratings yet
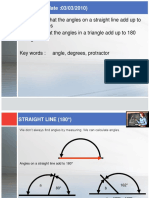
- Review Angles Add Up to 180 and 360 DegreesDocument8 pagesReview Angles Add Up to 180 and 360 DegreesNurulAinMatAronNo ratings yet
- History in Mathematics EducationDocument455 pagesHistory in Mathematics EducationRudolf Rainer AsuncionNo ratings yet
- Branching ProcessesDocument15 pagesBranching ProcessesPatrick MugoNo ratings yet
- Math ReviewerDocument4 pagesMath ReviewerMikaela UyNo ratings yet
- An Elementary Course in Synthetic Projective GeometryFrom EverandAn Elementary Course in Synthetic Projective GeometryNo ratings yet
- BayesforbeginnersDocument21 pagesBayesforbeginnersapi-284811969No ratings yet
- EAR2024Document7 pagesEAR2024eunchan.hwang100% (1)
- Algebra Maths BookDocument430 pagesAlgebra Maths BookAmbikesh kumar PandeyNo ratings yet
- On Reform Movement and The Limits of Mathematical DiscourseDocument42 pagesOn Reform Movement and The Limits of Mathematical DiscourseEly HernandezNo ratings yet
- METHODS OF PROOFSDocument9 pagesMETHODS OF PROOFSPotatoprysNo ratings yet
- Probing in Islamic Philosophy Studies in The Philosophies of Ibn Sina, Al-Ghazali and Other Major Muslim Thinkers PDFDocument12 pagesProbing in Islamic Philosophy Studies in The Philosophies of Ibn Sina, Al-Ghazali and Other Major Muslim Thinkers PDFikutmilis50% (2)
- Aristotle, Archimedes, Euclid, and The Origin of MechanicsDocument17 pagesAristotle, Archimedes, Euclid, and The Origin of Mechanicsmullen65100% (1)
- CIDAM-gen MathDocument7 pagesCIDAM-gen MathJewel Shyne Estrada-LidayNo ratings yet
- Facts Evidence and Legal ProofDocument23 pagesFacts Evidence and Legal ProofSimu JemwaNo ratings yet
- Math Lecture Notes Set TheoryDocument36 pagesMath Lecture Notes Set TheorySheehan Dominic HanrahanNo ratings yet
- Sets in Types, Types in Sets: October 2006Document18 pagesSets in Types, Types in Sets: October 2006Yeeyee AungNo ratings yet
- HirstDocument119 pagesHirstMuhammad Umer MughalNo ratings yet
- C G C S A I A 1. I: Ertificate of Uide Ertificate of TudentDocument28 pagesC G C S A I A 1. I: Ertificate of Uide Ertificate of TudentabhishekNo ratings yet
- 1 Leonhard EulerDocument6 pages1 Leonhard EulerTon TonNo ratings yet
- The Art of The Intelligible - BellDocument251 pagesThe Art of The Intelligible - BellbleximNo ratings yet
- Construction of Number SystemsDocument31 pagesConstruction of Number SystemsKelvin100% (1)
- Course Notes Math235 - Copy 2Document118 pagesCourse Notes Math235 - Copy 2fullmetalporo2012No ratings yet
- Proving Some Geometric Inequalities by Using Complex Numbers - Titu Andreescu and Dorin AndricaDocument8 pagesProving Some Geometric Inequalities by Using Complex Numbers - Titu Andreescu and Dorin AndricaAltananyNo ratings yet
- Terrance Howard Dollar Book OTOET PREVIEW 044 NOV7 2019Document162 pagesTerrance Howard Dollar Book OTOET PREVIEW 044 NOV7 2019Orion PaxNo ratings yet
- Year 11 Specialist Maths TextbookDocument767 pagesYear 11 Specialist Maths TextbookMikiNo ratings yet
- Course Outline: MATH1081 Discrete MathematicsDocument15 pagesCourse Outline: MATH1081 Discrete MathematicsEdwardNo ratings yet
- Geometry For College StudentsDocument238 pagesGeometry For College Studentsbrr100% (12)
- A P P L e P I e o R D e RDocument149 pagesA P P L e P I e o R D e RJan LubinaNo ratings yet
- Logical Agents: Mr. Prayag PatelDocument224 pagesLogical Agents: Mr. Prayag PatelDhruv VyasNo ratings yet
- A Step by Step Guide To Godel S Incomple PDFDocument48 pagesA Step by Step Guide To Godel S Incomple PDFHp RaghunandanNo ratings yet
- Xin Ma - Using Classification and Regression Trees - A Practical Primer-Information Age Publishing (2018)Document166 pagesXin Ma - Using Classification and Regression Trees - A Practical Primer-Information Age Publishing (2018)betty wynstraNo ratings yet
- Fund Intro PDFDocument49 pagesFund Intro PDFFizqi Boedax R-ezecpectorNo ratings yet
- The Axiom of Choice, The Well Ordering Principle and Zorn's LemmaDocument8 pagesThe Axiom of Choice, The Well Ordering Principle and Zorn's LemmaGonçalo MadalenoNo ratings yet
- Arturo Sangalli-Pythagoras' Revenge - A Mathematical Mystery-Princeton University Press (2009)Document301 pagesArturo Sangalli-Pythagoras' Revenge - A Mathematical Mystery-Princeton University Press (2009)Mónica MondragónNo ratings yet
- Summative Test in Mathematics 8Document4 pagesSummative Test in Mathematics 8Garry D. DivinagraciaNo ratings yet
- Weakest-Precondition Reasoning What Do We Mean by "Weakest"?Document18 pagesWeakest-Precondition Reasoning What Do We Mean by "Weakest"?Mohit Kumar BoriwalNo ratings yet
- Famous MathematicianDocument116 pagesFamous MathematicianAngelyn MontibolaNo ratings yet
- Lucan Central CollegesDocument14 pagesLucan Central CollegesKaye Jean VillaNo ratings yet