You might also like
- How To Pronounce Latin WordsDocument2 pagesHow To Pronounce Latin Wordsshshsh12346565No ratings yet
- Museum EducationDocument9 pagesMuseum Educationshshsh12346565No ratings yet
- Unicode Basic LatinDocument6 pagesUnicode Basic LatinAKMARNo ratings yet
- Forschungen 61/1954/, 147-169 (That Is To Say Subsequent To The Deciphering ofDocument16 pagesForschungen 61/1954/, 147-169 (That Is To Say Subsequent To The Deciphering ofshshsh12346565No ratings yet
- Acta Classica XXI (: Archaeological EvidenceDocument13 pagesActa Classica XXI (: Archaeological Evidenceshshsh12346565No ratings yet
- Modeling and Rendering Escher-Like Impossible Scenes: ForumDocument7 pagesModeling and Rendering Escher-Like Impossible Scenes: Forumshshsh12346565No ratings yet
- Flyer Product 52913 enDocument2 pagesFlyer Product 52913 enshshsh12346565No ratings yet
- Major Modes GuideDocument6 pagesMajor Modes Guideshshsh12346565No ratings yet
- A1998DendronEngl PDFDocument37 pagesA1998DendronEngl PDFshshsh12346565No ratings yet
- 0203partwritinghorizontal PDFDocument1 page0203partwritinghorizontal PDFshshsh12346565No ratings yet
- 0202partwritingvertical PDFDocument1 page0202partwritingvertical PDFshshsh12346565No ratings yet
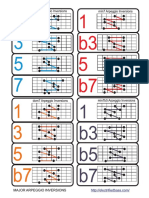
- Major Arpeggio Inversions Bass Guitar PDFDocument1 pageMajor Arpeggio Inversions Bass Guitar PDFshshsh12346565No ratings yet
- Chord Vs Scales Poster 11x17Document1 pageChord Vs Scales Poster 11x17shshsh12346565100% (1)
- 44 WW W WW W B WW W BB: Triad Shapes To Be Used in The SandwichDocument1 page44 WW W WW W B WW W BB: Triad Shapes To Be Used in The Sandwichshshsh12346565No ratings yet
- Police Dogs From Albania As Indicators of Exposure Risk To Toxoplasma Gondii, Neospora Caninum and Vector-Borne Pathogens of Zoonotic and Veterinary ConcernDocument13 pagesPolice Dogs From Albania As Indicators of Exposure Risk To Toxoplasma Gondii, Neospora Caninum and Vector-Borne Pathogens of Zoonotic and Veterinary Concernshshsh12346565No ratings yet
- Ph.d. 2015 Adam HyllestedDocument228 pagesPh.d. 2015 Adam Hyllestedshshsh12346565No ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Unit 5 - Computer Graphics & MultimediaDocument22 pagesUnit 5 - Computer Graphics & MultimediaTonnyNo ratings yet
- MS VBAProject BinDocument111 pagesMS VBAProject BinMartin LeeNo ratings yet
- Howto Unicode PDFDocument13 pagesHowto Unicode PDFMonish PNo ratings yet
- Data Conversion MQDocument40 pagesData Conversion MQsuryo.gumilarNo ratings yet
- Percona Server 5.5.34-32.0Document195 pagesPercona Server 5.5.34-32.0Mas KliwonNo ratings yet
- Machine Level Representation of Data Character RepresentationDocument14 pagesMachine Level Representation of Data Character RepresentationRenchie GonzalesNo ratings yet
- Computer Graphics and MultimediaDocument19 pagesComputer Graphics and Multimediasunikesh shuklaNo ratings yet
- Strings - ASCII, UTF8, UTF32, ISCII (Indian Script Code), Unicode-2 PDFDocument30 pagesStrings - ASCII, UTF8, UTF32, ISCII (Indian Script Code), Unicode-2 PDFSumit KumarNo ratings yet
- Grandstream Networks, Inc.: GXV3275 IP Multimedia Phone For Android XML Based Downloadable Phonebook GuideDocument22 pagesGrandstream Networks, Inc.: GXV3275 IP Multimedia Phone For Android XML Based Downloadable Phonebook GuidemasoodkamaliNo ratings yet
- NetAnalysis v2 User GuideDocument261 pagesNetAnalysis v2 User GuideIan HendersonNo ratings yet
- PEP-8 Tutorial - Code Standards in Python PDFDocument20 pagesPEP-8 Tutorial - Code Standards in Python PDFPavankumar KaredlaNo ratings yet
- Unicode CPP PDFDocument139 pagesUnicode CPP PDFE.P.No ratings yet
- MS OxcdataDocument136 pagesMS Oxcdatagaby_munteanNo ratings yet
- NewsDocument143 pagesNewsnirminNo ratings yet
- jBASE InternationalizationDocument57 pagesjBASE InternationalizationryfatoudiakhateNo ratings yet
- Pcre 2 TestDocument33 pagesPcre 2 TestAhmed HassanNo ratings yet
- Unicodebook PDFDocument73 pagesUnicodebook PDFaminerachedNo ratings yet
- Python Programming UNIT 2Document25 pagesPython Programming UNIT 2indu budamaguntaNo ratings yet
- db2 Unicode-DbcsDocument30 pagesdb2 Unicode-DbcsSantosh SubuddhiNo ratings yet
- (MS-DTYP) : Windows Data Types: Open Specifications Promise Microsoft Community PromiseDocument153 pages(MS-DTYP) : Windows Data Types: Open Specifications Promise Microsoft Community PromiseVarnavas XiaomiNo ratings yet
- LiveCode Documentation Format Reference PDFDocument5 pagesLiveCode Documentation Format Reference PDFfx0neNo ratings yet
- Python TutorialDocument88 pagesPython TutorialAbiy MulugetaNo ratings yet
- History of PythonDocument134 pagesHistory of PythonrayascribdNo ratings yet
- Lecture 1: Encoding Language: LING 1330/2330: Introduction To Computational Linguistics Na-Rae HanDocument18 pagesLecture 1: Encoding Language: LING 1330/2330: Introduction To Computational Linguistics Na-Rae HanLaura AmwayiNo ratings yet
- Unicode - Wikipedia, The Free EncyclopediaDocument18 pagesUnicode - Wikipedia, The Free EncyclopediaManitNo ratings yet
- (MS Offcrypto) PDFDocument107 pages(MS Offcrypto) PDFelisaNo ratings yet
- Python 3.2 Quick Reference: John W. ShipmanDocument52 pagesPython 3.2 Quick Reference: John W. ShipmanRafaelCostaNo ratings yet
- Cyber Forensics Module - 2 NotesDocument39 pagesCyber Forensics Module - 2 NotesYash DiwanNo ratings yet
- Lecture - ASCII and UnicodeDocument38 pagesLecture - ASCII and UnicodeTeen SlaveNo ratings yet
- Z/architecture - Reference SummaryDocument84 pagesZ/architecture - Reference SummarymukeshNo ratings yet