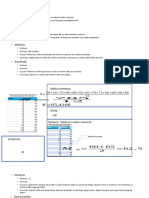
You might also like
- Apostila Etapa Definir YB - MI DomenechDocument40 pagesApostila Etapa Definir YB - MI DomenechdanielleNo ratings yet
- Atividade3 WilliamDocument3 pagesAtividade3 WilliamWilliam MiillerNo ratings yet
- Área GourmetDocument23 pagesÁrea GourmetfernandapauladesignerNo ratings yet
- 14 Check List Kaizen Como Melhoria Cont Nua 1708592110Document1 page14 Check List Kaizen Como Melhoria Cont Nua 1708592110Jardel Marin KipperNo ratings yet
- Expoente 12 - Prova-Modelo de Exame - ResolucaoDocument9 pagesExpoente 12 - Prova-Modelo de Exame - ResolucaoMarta SecoNo ratings yet
- Novas minicarregadeiras Skid CASE com maior produtividade e confortoDocument3 pagesNovas minicarregadeiras Skid CASE com maior produtividade e confortoAloah PereiraNo ratings yet
- UTF-8''atividade3 ModeloDocument3 pagesUTF-8''atividade3 ModeloJeff Ragacci GarzaroNo ratings yet
- Atividade 3Document3 pagesAtividade 3Cleidiane AlvesNo ratings yet
- Atividade 3 Eliseu 21-06-2023 RevisãoDocument3 pagesAtividade 3 Eliseu 21-06-2023 Revisãoeliseu silvaNo ratings yet
- LISTA VERIFICACAO Português EDUC LITDocument2 pagesLISTA VERIFICACAO Português EDUC LITpedro afonsoNo ratings yet
- Atividade3 UC4 TSTDocument3 pagesAtividade3 UC4 TSTKétila oliveiraNo ratings yet
- Fluxo SustentacaoDocument12 pagesFluxo Sustentacaopereira170780No ratings yet
- Curso Lean - Ferramentas Lean (Isabela Gama)Document63 pagesCurso Lean - Ferramentas Lean (Isabela Gama)João Paulo Siqueira NalonNo ratings yet
- Atividade 300123Document3 pagesAtividade 300123William SouzaNo ratings yet
- Avaliação de VendedoresDocument17 pagesAvaliação de VendedoresMudar de VidaNo ratings yet
- Template Projeto MidState (Salvo Automaticamente)Document25 pagesTemplate Projeto MidState (Salvo Automaticamente)thomainoroseNo ratings yet
- Fluxo Ábaris End To EndDocument1 pageFluxo Ábaris End To EndeudesarNo ratings yet
- Atividade3 Modelo+Document3 pagesAtividade3 Modelo+Marcella AmadorNo ratings yet
- Desaf55io Semanal 1 - CourseraDocument1 pageDesaf55io Semanal 1 - CourseraDeise EstefaniNo ratings yet
- Teste 2 - G36 - Raven - DFHDocument26 pagesTeste 2 - G36 - Raven - DFHIngrid RodriguesNo ratings yet
- atividade3_modelo1 (1)modulo b corrigidaDocument4 pagesatividade3_modelo1 (1)modulo b corrigidasandradosanjos2104No ratings yet
- EsPCEx Plano de EstudosDocument29 pagesEsPCEx Plano de Estudoskamilly studiesNo ratings yet
- Modelo ProvaDocument126 pagesModelo ProvaKlew Cleudiney Theodoro BrandãoNo ratings yet
- Atividade3 CORRIGIDA Nota ADocument3 pagesAtividade3 CORRIGIDA Nota AMarile CruzNo ratings yet
- Atividade3 Riscos OcupacionaisDocument3 pagesAtividade3 Riscos OcupacionaisLúcio LeiteNo ratings yet
- Planejamento de pessoal para empresa Bem SucedidaDocument12 pagesPlanejamento de pessoal para empresa Bem SucedidaMarri Bezerra SilvaNo ratings yet
- Processo de aprovação de clones de eucaliptoDocument1 pageProcesso de aprovação de clones de eucaliptoGuilherme de Miranda Fernandes ReisNo ratings yet
- Eye RDocument1 pageEye RCarlos HenriqueNo ratings yet
- Curso Lean - Como ImplementarDocument47 pagesCurso Lean - Como ImplementarJoão Paulo Siqueira NalonNo ratings yet
- Curso de Matemática - Potenciação e RadiciaçãoDocument25 pagesCurso de Matemática - Potenciação e Radiciaçãogustavo_romanhol2338No ratings yet
- CPS-ITC-NETWORKING ESSENTIALS 2021 - Teste Do Capítulo 9 - Revisão Da Tentativa - PDF - Sistema de Nomes de Domínio - Rede de ComputadoresDocument1 pageCPS-ITC-NETWORKING ESSENTIALS 2021 - Teste Do Capítulo 9 - Revisão Da Tentativa - PDF - Sistema de Nomes de Domínio - Rede de ComputadoresPedro Goncz100% (1)
- Avaliação auto-avaliação alimentarDocument1 pageAvaliação auto-avaliação alimentarLisa TaveiraNo ratings yet
- Atividade3 - Modelo (1) (1) - CópiaDocument2 pagesAtividade3 - Modelo (1) (1) - CópiaChandler Rodrigues da Costa S ArrudaNo ratings yet
- Planilha de Treino de ImitaçãoDocument1 pagePlanilha de Treino de ImitaçãoSAMIA PSICNo ratings yet
- Atividade 3Document3 pagesAtividade 3lorenaricardo21No ratings yet
- Atividade3 - Modelo 4Document3 pagesAtividade3 - Modelo 4Giselle stephanie da silva cruzNo ratings yet
- Radiciação: operação que permite obter a raiz de um número ou expressãoDocument15 pagesRadiciação: operação que permite obter a raiz de um número ou expressãoAna Clara SiqueiraNo ratings yet
- DMND0002627 - MatrizDocument1 pageDMND0002627 - MatrizJúnior MartinsNo ratings yet
- Tickmill CopyTrade 10 Motivos para Copiar Os Melhores Traders Do Mundo - Consistência GarantidaDocument2 pagesTickmill CopyTrade 10 Motivos para Copiar Os Melhores Traders Do Mundo - Consistência GarantidaharissonrafandradeNo ratings yet
- Ficha AutoAvaliacao TrabalhodeAulaDocument2 pagesFicha AutoAvaliacao TrabalhodeAulaÍris NevesNo ratings yet
- Treinamento de SDR's - Template MeetimeDocument14 pagesTreinamento de SDR's - Template MeetimeAndreia RodriguesNo ratings yet
- Atividade 3 Modulo b-18Document3 pagesAtividade 3 Modulo b-18Iraci Ferreira da Silva100% (1)
- Uc 4 Atividade IiiDocument3 pagesUc 4 Atividade IiiLucas ChagasNo ratings yet
- 1 Época 2021Document10 pages1 Época 2021Beatriz RodriguesNo ratings yet
- Atividade3 2024Document3 pagesAtividade3 2024emillymenezzes12No ratings yet
- Projeto Político Pedagógico 2013 Colegio CasuchaDocument269 pagesProjeto Político Pedagógico 2013 Colegio CasuchaRegina Célia PolettoNo ratings yet
- Atividade3uc4 BrunoquadrosroqueDocument3 pagesAtividade3uc4 BrunoquadrosroquebrunoquadrosrNo ratings yet
- Ficha Tecnica Advento EspecialDocument2 pagesFicha Tecnica Advento EspecialjoaochanocaNo ratings yet
- E Statistic ADocument5 pagesE Statistic Aicarocoelho93No ratings yet
- Modalidade UTEL-Estatísticas e Exame de Probabilidade - Semana 6 - Tentativa de RevisãoDocument5 pagesModalidade UTEL-Estatísticas e Exame de Probabilidade - Semana 6 - Tentativa de RevisãoScribdTranslationsNo ratings yet
- SR130-pt BR PDFDocument4 pagesSR130-pt BR PDFMarcelo MesquitaNo ratings yet
- Planilha de CorridaDocument8 pagesPlanilha de CorridaMateus SilvaNo ratings yet
- SUPORTE SENSOR POKAYOKEDocument1 pageSUPORTE SENSOR POKAYOKELucas AndreattiNo ratings yet
- Controle+de+RevisoesDocument4 pagesControle+de+Revisoesryan bentoNo ratings yet
- Simulado Inteligência ArtificialDocument2 pagesSimulado Inteligência ArtificialVictor KelerNo ratings yet
- Indicador de Conformidade Na Auditoria LV - Meio AmbienteDocument4 pagesIndicador de Conformidade Na Auditoria LV - Meio AmbienteRoberto Carlos BragaNo ratings yet
- PPL 2022Document32 pagesPPL 2022Doutora BiaNo ratings yet
- Acumular Valores Via Script - Qlik CommunityDocument5 pagesAcumular Valores Via Script - Qlik CommunityJosé SalomãoNo ratings yet
- Fichas Tecnicas Indicadores Idss Ab2020 17082020 PDFDocument309 pagesFichas Tecnicas Indicadores Idss Ab2020 17082020 PDFjuanfagnerNo ratings yet
- Atalhos de Comandos do Menu Arquivo e EditarDocument4 pagesAtalhos de Comandos do Menu Arquivo e EditarjuanfagnerNo ratings yet
- Link para Instalar e Criar Conta QlikDocument1 pageLink para Instalar e Criar Conta QlikjuanfagnerNo ratings yet
- LivroDocument652 pagesLivroMagno Saullo FonsecaNo ratings yet
- Python e o TitanicDocument18 pagesPython e o TitanicjuanfagnerNo ratings yet
- Qlik Sense Práticas RecomendadasDocument12 pagesQlik Sense Práticas RecomendadasjuanfagnerNo ratings yet
- Pdilabs 101118073834 Phpapp02Document37 pagesPdilabs 101118073834 Phpapp02Pedro NeffNo ratings yet
- Etl 2Document21 pagesEtl 2juanfagnerNo ratings yet
- 4 Batidas para Reduzir A Cintura Sem Deixar de ComerDocument4 pages4 Batidas para Reduzir A Cintura Sem Deixar de ComerjuanfagnerNo ratings yet
- Aula 01 Tutorial PdiDocument78 pagesAula 01 Tutorial PdijarleynobregaNo ratings yet
- Etl 3Document10 pagesEtl 3juanfagnerNo ratings yet
- Criação de backup automático em PythonDocument2 pagesCriação de backup automático em PythonjuanfagnerNo ratings yet
- Modelagem Decisao Enc1Document19 pagesModelagem Decisao Enc1juanfagnerNo ratings yet
- Cópia de Design ThinkingDocument3 pagesCópia de Design ThinkingjuanfagnerNo ratings yet
- Let S Data Ebook Como Se Tornar Um Cientista de DadosDocument126 pagesLet S Data Ebook Como Se Tornar Um Cientista de DadosMárcio Monteiro100% (1)
- Modelagem de Dados em UMLDocument17 pagesModelagem de Dados em UMLErick ValérioNo ratings yet
- Latam PassDocument1 pageLatam PassjuanfagnerNo ratings yet
- Comandos LinuxDocument3 pagesComandos LinuxjuanfagnerNo ratings yet
- Análise Dos DadosDocument64 pagesAnálise Dos DadosjuanfagnerNo ratings yet
- Ferramenta para Criptografia TruecryptDocument2 pagesFerramenta para Criptografia TruecryptjuanfagnerNo ratings yet
- Manual CCP Fabricação de Produtos de Panificação PDFDocument89 pagesManual CCP Fabricação de Produtos de Panificação PDFGislene LimaNo ratings yet
- Associação Algoritmo AprioriDocument36 pagesAssociação Algoritmo ApriorijuanfagnerNo ratings yet
- Ferramenta Hacker SandcatDocument2 pagesFerramenta Hacker SandcatjuanfagnerNo ratings yet
- Manual de Massa Fresca PDFDocument46 pagesManual de Massa Fresca PDFjuanfagnerNo ratings yet
- ED1 - 06 - Registros (Structs)Document40 pagesED1 - 06 - Registros (Structs)juanfagnerNo ratings yet
- 04 - Conceitos Importantes PDFDocument76 pages04 - Conceitos Importantes PDFNivair MoreiraNo ratings yet
- (E-Book) Apostila de JavaScript PDFDocument43 pages(E-Book) Apostila de JavaScript PDFobinakillerNo ratings yet
- Formação de agrupamentos: clustering hierárquicoDocument67 pagesFormação de agrupamentos: clustering hierárquicojuanfagnerNo ratings yet
- Associação Outros AlgoritmosDocument68 pagesAssociação Outros AlgoritmosjuanfagnerNo ratings yet
- Porcentagem Matemática para IniciantesDocument13 pagesPorcentagem Matemática para IniciantesAdamSoaresNo ratings yet
- Como Decorar o Quarto Com Pouco DinheiroDocument13 pagesComo Decorar o Quarto Com Pouco DinheiroJorge EstevesNo ratings yet
- NBR 08348 NB 763 - Execucao de Sinalizacao Horizontal de Pistas e Patios em AeroportosDocument2 pagesNBR 08348 NB 763 - Execucao de Sinalizacao Horizontal de Pistas e Patios em AeroportosFelipe Prestes BatistaNo ratings yet
- Matriz Técnica ABAPDocument169 pagesMatriz Técnica ABAPnaotosx100% (1)
- Check-list de veículo do 12o BPM de NaviraíDocument2 pagesCheck-list de veículo do 12o BPM de NaviraíkaiqueNo ratings yet
- Catalogo de Pecas PremoPlan 4.0Document26 pagesCatalogo de Pecas PremoPlan 4.0Walace GustavoNo ratings yet
- Relatório de Máquinas ElétricasDocument30 pagesRelatório de Máquinas ElétricasEder NelsonNo ratings yet
- ENG.-ELÉTRICA UninorteDocument4 pagesENG.-ELÉTRICA UninorteJean Martins FrancoNo ratings yet
- Globalização e Desenvolvimento - AlcoforadoDocument19 pagesGlobalização e Desenvolvimento - AlcoforadoBruno LopesNo ratings yet
- Inovação - Como Aplicar Design Thinking Na Administração Pública - PDFDocument5 pagesInovação - Como Aplicar Design Thinking Na Administração Pública - PDFAlberto BrandãoNo ratings yet
- Resumo - Família - 2º BiDocument30 pagesResumo - Família - 2º Bi9g7jzcdx5fNo ratings yet
- 01 - Lista de Comunicações ÓpticasDocument7 pages01 - Lista de Comunicações ÓpticasGabriel MachadoNo ratings yet
- Receita de BrigadeiroDocument14 pagesReceita de BrigadeiroNayson Morais100% (1)
- Gabarito prova matemática financeira juros simples compostosDocument2 pagesGabarito prova matemática financeira juros simples compostosMarco Rodrigues100% (2)
- TCC Farmácia ClinicaDocument11 pagesTCC Farmácia ClinicaHenrique JuniorNo ratings yet
- Apostila de Auditoria para ConcursosDocument16 pagesApostila de Auditoria para ConcursosAchei Concursos0% (1)
- Relatório Tec Lácteos - RequeijãoDocument12 pagesRelatório Tec Lácteos - RequeijãoAndressa Gonçalves100% (2)
- Marketing de Relacionamento Digital - Duração 1hDocument10 pagesMarketing de Relacionamento Digital - Duração 1hWagner BarretoNo ratings yet
- Licenciamento ambiental de portosDocument32 pagesLicenciamento ambiental de portosRoger landinNo ratings yet
- Respostas SIMULADODocument61 pagesRespostas SIMULADOVictor Hugo Soares Lima33% (3)
- Já Agora, o Jornal Gratuito Da Covilhã e Fundão, Nº 79Document12 pagesJá Agora, o Jornal Gratuito Da Covilhã e Fundão, Nº 79jaagoraNo ratings yet
- Diário Da Justiça Eletrônico - Data Da Veiculação - 23 - 08 - 2023Document240 pagesDiário Da Justiça Eletrônico - Data Da Veiculação - 23 - 08 - 2023desapegolivrosNo ratings yet
- Durametal produtos 40Document32 pagesDurametal produtos 40Leandro SantosNo ratings yet
- Caminhos para reduzir a burocracia dos pequenos negóciosDocument45 pagesCaminhos para reduzir a burocracia dos pequenos negóciosucon 2209No ratings yet
- Ficha 7 - Integracao Vertical PDFDocument7 pagesFicha 7 - Integracao Vertical PDFJoseph SmithNo ratings yet
- Vagas Sorocaba 09/04Document39 pagesVagas Sorocaba 09/04Adriana VendraminiNo ratings yet
- Documento de cobrança de imposto industrialDocument2 pagesDocumento de cobrança de imposto industrialAlfredo FerrãoNo ratings yet
- Cadeia Produtiva de Flores e MelDocument142 pagesCadeia Produtiva de Flores e MelErika Gleice Nascimento100% (1)
- Artigo Qsar Leave OutDocument9 pagesArtigo Qsar Leave OutClauber HenriqueNo ratings yet
- NR 07 - Vigilância Epidemiológica e Doenças Ocupacionais RespiratóriasDocument4 pagesNR 07 - Vigilância Epidemiológica e Doenças Ocupacionais RespiratóriasCPSSTNo ratings yet