You might also like
- Emerging Industrial Relation ScenariopptignouDocument27 pagesEmerging Industrial Relation ScenariopptignouvalarmathiyaNo ratings yet
- MIT6 006F11 Lec02 Orig PDFDocument9 pagesMIT6 006F11 Lec02 Orig PDFgprasadatvuNo ratings yet
- Consumer Behavior Models in TourismDocument105 pagesConsumer Behavior Models in Tourismgprasadatvu0% (1)
- 4 Motiv, Emot, Values Fall09Document35 pages4 Motiv, Emot, Values Fall09ziabuttNo ratings yet
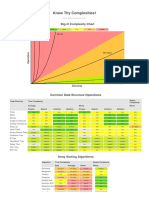
- Big-O Complexity Chart & Data Structure OperationsDocument2 pagesBig-O Complexity Chart & Data Structure OperationsDhruvaSNo ratings yet
- A Spell-Checker in R - AnrprogrammerDocument6 pagesA Spell-Checker in R - AnrprogrammergprasadatvuNo ratings yet
- Ir & Emerging Socio Economic Scenario...Document8 pagesIr & Emerging Socio Economic Scenario...2ruchi889% (9)
- Hall Ticket Cum Test Fee Receipt: Important InstructionsDocument1 pageHall Ticket Cum Test Fee Receipt: Important InstructionsgprasadatvuNo ratings yet
- Bamber CH 13 India SlidesDocument25 pagesBamber CH 13 India SlidesAndrewVazNo ratings yet
- Regex - Extract Pattern From String, Strip Text, Convert To Numeric and Sum in R DataDocument2 pagesRegex - Extract Pattern From String, Strip Text, Convert To Numeric and Sum in R DatagprasadatvuNo ratings yet
- IELTS Task 1 New Answer SheetDocument2 pagesIELTS Task 1 New Answer SheetChrisGovasNo ratings yet
- Https Raw - Githubusercontent.com Joelgrus Data-Science-From-Scratch Master Code Working With DataDocument7 pagesHttps Raw - Githubusercontent.com Joelgrus Data-Science-From-Scratch Master Code Working With DatagprasadatvuNo ratings yet
- Human Resource Planning IGNOU All in OneDocument202 pagesHuman Resource Planning IGNOU All in OnegprasadatvuNo ratings yet
- Cheat Sheets of Python Libraries TensorflowDocument3 pagesCheat Sheets of Python Libraries TensorflowgprasadatvuNo ratings yet
- RPubs - Text-Mining With Rvest and QdapDocument17 pagesRPubs - Text-Mining With Rvest and QdapgprasadatvuNo ratings yet
- All Cheat Sheets PDFDocument6 pagesAll Cheat Sheets PDFgprasadatvuNo ratings yet
- QDocument2 pagesQgprasadatvuNo ratings yet
- HyDocument3 pagesHygprasadatvuNo ratings yet
- ALGO-Merge-Sort-IntroDocument47 pagesALGO-Merge-Sort-IntrodNo ratings yet
- Keras Cheat Sheet PythonDocument1 pageKeras Cheat Sheet PythonJohnNo ratings yet
- Https Raw - Githubusercontent.com Joelgrus Data-Science-From-Scratch Master Code Natural Language ProcessingDocument5 pagesHttps Raw - Githubusercontent.com Joelgrus Data-Science-From-Scratch Master Code Natural Language ProcessinggprasadatvuNo ratings yet
- Https Raw - Githubusercontent.com Joelgrus Data-Science-From-Scratch Master Code Natural Language ProcessingDocument5 pagesHttps Raw - Githubusercontent.com Joelgrus Data-Science-From-Scratch Master Code Natural Language ProcessinggprasadatvuNo ratings yet
- Getting Data from APIs and Web ScrapingDocument4 pagesGetting Data from APIs and Web ScrapinggprasadatvuNo ratings yet
- MSc in Applied Data Science & Big DataDocument8 pagesMSc in Applied Data Science & Big DatagprasadatvuNo ratings yet
- Learning From Data - Online Course (MOOC)Document2 pagesLearning From Data - Online Course (MOOC)gprasadatvuNo ratings yet
- Top Cities and Other Demographics For Data Scientists - Data Science CentralDocument6 pagesTop Cities and Other Demographics For Data Scientists - Data Science CentralgprasadatvuNo ratings yet
- List of Machine Learning Certifications and Best Data Science BootcampsDocument23 pagesList of Machine Learning Certifications and Best Data Science BootcampsgprasadatvuNo ratings yet
- Numpy-User-1 11 0 PDFDocument135 pagesNumpy-User-1 11 0 PDFDavid Corredor RamirezNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Thera BankDocument25 pagesThera BankSanan Olachery100% (1)
- Seminar Report On Palm Vein TechnologyDocument23 pagesSeminar Report On Palm Vein TechnologyAbdul KhaderNo ratings yet
- Biostatistical Methods Explained in Plain EnglishDocument14 pagesBiostatistical Methods Explained in Plain EnglishrexvillavelezNo ratings yet
- An Insight Into Classification With Imbalanced DataDocument29 pagesAn Insight Into Classification With Imbalanced DataSaleem AsgharNo ratings yet
- AssessingMCQandSSAQ PDFDocument6 pagesAssessingMCQandSSAQ PDFBetah ChaabaNo ratings yet
- Zdenek Racil, Iva Kocmanova, Martina Lengerova, Barbora Weinbergerova, Lucie Buresova, Martina Toskova, Jana Winterova, Shira Timilsina, Isa Rodriguez and Jiri MayerDocument7 pagesZdenek Racil, Iva Kocmanova, Martina Lengerova, Barbora Weinbergerova, Lucie Buresova, Martina Toskova, Jana Winterova, Shira Timilsina, Isa Rodriguez and Jiri MayerKartikNo ratings yet
- Psychometric properties of Hungarian adult ADHD scaleDocument13 pagesPsychometric properties of Hungarian adult ADHD scaleMohamed AbozeidNo ratings yet
- Mayo ScoreDocument7 pagesMayo ScoreBruno LorenzettoNo ratings yet
- Chapter 5 - Evaluating Classification & Predictive PerformanceDocument25 pagesChapter 5 - Evaluating Classification & Predictive PerformancejayNo ratings yet
- DI Chap1Document9 pagesDI Chap1HuntingparxxNo ratings yet
- 2588 Software Development and Modelling For Churn Prediction Using Logistic Regression in Telecommunication IndustryDocument5 pages2588 Software Development and Modelling For Churn Prediction Using Logistic Regression in Telecommunication IndustryWARSE JournalsNo ratings yet
- Compare CART, RF and ANN models for tour insurance claim predictionDocument41 pagesCompare CART, RF and ANN models for tour insurance claim predictionNikita Chaturvedi100% (1)
- Bayer's in Silico ADMET Platform - Journey of Machine LearningDocument8 pagesBayer's in Silico ADMET Platform - Journey of Machine LearningYOUTEACHNo ratings yet
- Comparison of Different Machine Learning AlgorithmsDocument13 pagesComparison of Different Machine Learning AlgorithmsFrancis MtamboNo ratings yet
- Hijar 1998Document9 pagesHijar 1998Marilyn LozadaNo ratings yet
- SRM NotesDocument38 pagesSRM NotesYU XUAN LEENo ratings yet
- Research Paper 4Document26 pagesResearch Paper 4Amit RajputNo ratings yet
- Stephen Klosterman - Data Science Projects With Python - A Case Study Approach To Successful Data Science Projects Using Python, Pandas, and Scikit-Learn (2019)Document374 pagesStephen Klosterman - Data Science Projects With Python - A Case Study Approach To Successful Data Science Projects Using Python, Pandas, and Scikit-Learn (2019)NIKHIL WAKODE100% (1)
- Obfuscated Malware Detection Using Dilated Convolutional NetworkDocument6 pagesObfuscated Malware Detection Using Dilated Convolutional NetworkNicolas PinedaNo ratings yet
- Extended Leukocyte Differential Count and C-Reactive Protein inDocument8 pagesExtended Leukocyte Differential Count and C-Reactive Protein ini chen chenNo ratings yet
- Robert G. Downer, Grand Valley State University, Allendale, MI Patrick J. Richardson, Van Andel Research Institute, Grand Rapids, MIDocument11 pagesRobert G. Downer, Grand Valley State University, Allendale, MI Patrick J. Richardson, Van Andel Research Institute, Grand Rapids, MIMahmoud TriguiNo ratings yet
- Detecting Driver Sleepiness Using Consumer Wearable Devices in Manual and Partial Automated Real-Road DrivingDocument10 pagesDetecting Driver Sleepiness Using Consumer Wearable Devices in Manual and Partial Automated Real-Road DrivingPrashanth HCNo ratings yet
- Ekonometrika - Results For Logistic Regression in XLSTATDocument4 pagesEkonometrika - Results For Logistic Regression in XLSTATKunandar PrasetyoNo ratings yet
- Machine Learning Techniques for Heart Disease PredictionDocument8 pagesMachine Learning Techniques for Heart Disease PredictionGiranshu BhatejaNo ratings yet
- A Practical Guide To Artificial Intelligence-Based Image Analysis in RadiologyDocument7 pagesA Practical Guide To Artificial Intelligence-Based Image Analysis in RadiologyGeneNo ratings yet
- Polish Journal of Surgery The Usefulness of The Mannheim Peritonitis IndexDocument6 pagesPolish Journal of Surgery The Usefulness of The Mannheim Peritonitis IndexSyahrinaFakihunNo ratings yet
- Grayson BBM JMPPro Chapter7Document39 pagesGrayson BBM JMPPro Chapter7youcef AlgrNo ratings yet
- SR 11-7, Validation and Machine Learning ModelsDocument31 pagesSR 11-7, Validation and Machine Learning Modelsraypa1401No ratings yet
- MELD Related Files Liver MELD-PlusDocument45 pagesMELD Related Files Liver MELD-PlusUKNo ratings yet
- Data Science Course SyllabusDocument13 pagesData Science Course SyllabuspriyaNo ratings yet