You might also like
- Stat Doc Pract 6,7,8Document17 pagesStat Doc Pract 6,7,8Ajay KajaniyaNo ratings yet
- UNIT 4 - Part BDocument15 pagesUNIT 4 - Part BNetaji GandiNo ratings yet
- Statistics With R Programming - Unit - 5Document31 pagesStatistics With R Programming - Unit - 5brahminisaiNo ratings yet
- Freq Dist S 13 SlidesDocument112 pagesFreq Dist S 13 SlidestranthevutNo ratings yet
- 7probability Distributions (Binomial, Poisson and Normal)Document33 pages7probability Distributions (Binomial, Poisson and Normal)lakshita6789No ratings yet
- Lab-6-Binomail and Poisson DistributionDocument13 pagesLab-6-Binomail and Poisson DistributionRakib Khan100% (1)
- Lab3 Fitting and Plotting of Binomial Distribution & Poisson Distribution (Challenging Experiment 2 (A) and 2 (B) ) AimDocument18 pagesLab3 Fitting and Plotting of Binomial Distribution & Poisson Distribution (Challenging Experiment 2 (A) and 2 (B) ) AimAshutosh MauryaNo ratings yet
- 5 DistributionsDocument11 pages5 DistributionsNguyên CátNo ratings yet
- Assignment-2: Name: Ahamad Ashique Mozumder ID: 1821474030 Section: 25Document13 pagesAssignment-2: Name: Ahamad Ashique Mozumder ID: 1821474030 Section: 25Salman ShahriarNo ratings yet
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument57 pagesExamples of Continuous Probability Distributions:: The Normal and Standard NormalPawan JajuNo ratings yet
- Binomial DistributionDocument22 pagesBinomial DistributionRemelyn AsahidNo ratings yet
- Lab Project 5: The Normal Approximation To Binomial DistributionDocument4 pagesLab Project 5: The Normal Approximation To Binomial DistributionjuanNo ratings yet
- Lab-2: Probability Distributions Name: Objective:To Compute Probability Density Function (PDF) and Cumulative Distribution Function (CDF) OutcomesDocument15 pagesLab-2: Probability Distributions Name: Objective:To Compute Probability Density Function (PDF) and Cumulative Distribution Function (CDF) OutcomesVishal RaminaNo ratings yet
- STAT100 Fall19 Test 2 ANSWERS Practice Problems PDFDocument23 pagesSTAT100 Fall19 Test 2 ANSWERS Practice Problems PDFabutiNo ratings yet
- The Central Limit TheoremDocument8 pagesThe Central Limit TheoremChriselle RNo ratings yet
- Sociology 592 - Research Statistics I Exam 1 Answer Key - DRAFT September 24, 2004Document8 pagesSociology 592 - Research Statistics I Exam 1 Answer Key - DRAFT September 24, 2004stephen562001No ratings yet
- DOM105 2022 Session 4Document12 pagesDOM105 2022 Session 4DevYTNo ratings yet
- BBM203 - Kierrtana - 071190094Document11 pagesBBM203 - Kierrtana - 071190094kierrtanaNo ratings yet
- Tugas Kuliah StatistikaDocument4 pagesTugas Kuliah StatistikaCEOAmsyaNo ratings yet
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument57 pagesExamples of Continuous Probability Distributions:: The Normal and Standard NormalAkshay VetalNo ratings yet
- Probability and Stochastic Processes 3rd Edition Quiz SolutionsDocument90 pagesProbability and Stochastic Processes 3rd Edition Quiz SolutionsEdward Li100% (2)
- R Lab - Probability DistributionsDocument10 pagesR Lab - Probability DistributionsPranay PandeyNo ratings yet
- Tugas Kuliah Statistika SESI 4Document4 pagesTugas Kuliah Statistika SESI 4CEOAmsyaNo ratings yet
- Binomial DistributionDocument3 pagesBinomial DistributionTeena ThaparNo ratings yet
- Basic Inferential Statistics ExampleDocument14 pagesBasic Inferential Statistics ExampleteoremadetalesNo ratings yet
- Spring 12 QMB3250 Exam 1 Applicable Spring 10 Exam 1 SolutionsDocument7 pagesSpring 12 QMB3250 Exam 1 Applicable Spring 10 Exam 1 Solutionsjonaleman0923No ratings yet
- WIN SEM (2020-21) CSE4029 ETH AP2020215000156 Reference Material I 27-Jan-2021 DistibutionDocument7 pagesWIN SEM (2020-21) CSE4029 ETH AP2020215000156 Reference Material I 27-Jan-2021 DistibutionmaneeshmogallpuNo ratings yet
- 11 Final SolutionsDocument19 pages11 Final Solutionsterrygoh6972No ratings yet
- QTM Cycle 7 Session 4Document79 pagesQTM Cycle 7 Session 4OttilieNo ratings yet
- 03 - CT3S Introduction To Probability Simulation and Gibbs Sampling With R SolutionsDocument270 pages03 - CT3S Introduction To Probability Simulation and Gibbs Sampling With R SolutionsMatt O'Brien100% (1)
- HW 23 P 4 RieDocument5 pagesHW 23 P 4 Rie정하윤No ratings yet
- Estimating Population VariancesDocument17 pagesEstimating Population VariancesRossel Jane CampilloNo ratings yet
- Batch38 CSE7315c Probability Basics Lab04 SolutionsDocument3 pagesBatch38 CSE7315c Probability Basics Lab04 SolutionsvarshikaNo ratings yet
- Chem 206 Lab ManualDocument69 pagesChem 206 Lab ManualDouglas DlutzNo ratings yet
- MTH 302 Long Questions Solved by Pisces Girl "My Lord! Increase Me in Knowledge."Document20 pagesMTH 302 Long Questions Solved by Pisces Girl "My Lord! Increase Me in Knowledge."Fun NNo ratings yet
- Binomial and Normal DistributionDocument29 pagesBinomial and Normal DistributionarunpandiyanNo ratings yet
- Ncert Sol Class 11 Chapter 8 Dec07 Binomial TheoremDocument24 pagesNcert Sol Class 11 Chapter 8 Dec07 Binomial TheoremSnehasish SinhaNo ratings yet
- Distributions ExamplesDocument12 pagesDistributions ExamplesEdmundo LazoNo ratings yet
- Topic 2 Part III PDFDocument30 pagesTopic 2 Part III PDFChris MastersNo ratings yet
- Confidence Interval For Variance (Problems)Document13 pagesConfidence Interval For Variance (Problems)utkucam2No ratings yet
- Tatang A Gumanti 2010: Pengenalan Alat-Alat Uji Statistik Dalam Penelitian SosialDocument15 pagesTatang A Gumanti 2010: Pengenalan Alat-Alat Uji Statistik Dalam Penelitian SosialPrima JoeNo ratings yet
- Full Name of submitter: Cao Thị Minh Anh Student ID: IELSIU18002Document7 pagesFull Name of submitter: Cao Thị Minh Anh Student ID: IELSIU18002ManhNo ratings yet
- Statistics Assignment PDFDocument3 pagesStatistics Assignment PDFpawir97576No ratings yet
- 00 Lab NotesDocument13 pages00 Lab Notesreddykavya2111No ratings yet
- Test 5 QuestionsDocument5 pagesTest 5 QuestionsJr NtrNo ratings yet
- Unit 4. Probability DistributionsDocument18 pagesUnit 4. Probability DistributionszinfadelsNo ratings yet
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument57 pagesExamples of Continuous Probability Distributions:: The Normal and Standard NormalkethavarapuramjiNo ratings yet
- Math11 SP Q3 M4 PDFDocument16 pagesMath11 SP Q3 M4 PDFJessa Banawan EdulanNo ratings yet
- Post-Exam 2 Practice Questions - Solutions 18.05, Spring 2014 Confidence IntervalsDocument7 pagesPost-Exam 2 Practice Questions - Solutions 18.05, Spring 2014 Confidence IntervalsIslamSharafNo ratings yet
- 37 2Document20 pages37 2Mayar ZoNo ratings yet
- Student Resources PDFDocument943 pagesStudent Resources PDFMuffet Lkr100% (3)
- Chapter 2 - Lesson 4 Random VariablesDocument19 pagesChapter 2 - Lesson 4 Random VariablesChi VirayNo ratings yet
- Measures of Central Tendency and Other Positional MeasuresDocument13 pagesMeasures of Central Tendency and Other Positional Measuresbv123bvNo ratings yet
- Chapter2-New (Compatibility Mode)Document52 pagesChapter2-New (Compatibility Mode)Hafiz SuhaimiNo ratings yet
- Chapter 7 Inferences Using Normal and T-DistributionDocument16 pagesChapter 7 Inferences Using Normal and T-Distributionmenglee100% (1)
- Lecture Notes Finite DifferencesDocument22 pagesLecture Notes Finite DifferencesvignanarajNo ratings yet
- ECE Regulation 2017 Full SyllabusDocument121 pagesECE Regulation 2017 Full SyllabusNandha KumarNo ratings yet
- Lecture Notes Probability DistributionsDocument2 pagesLecture Notes Probability DistributionsvignanarajNo ratings yet
- Question Bank On Z TransformsDocument15 pagesQuestion Bank On Z TransformsvignanarajNo ratings yet
- Lecture Notes On Design of ExperimentsDocument17 pagesLecture Notes On Design of ExperimentsvignanarajNo ratings yet
- Finite Diff Equation NotesDocument15 pagesFinite Diff Equation NotesvignanarajNo ratings yet
- Annotations For Symmetric Probabilistic Encryption Algorithm Based On Chaotic Attractors of Neural NetworksDocument4 pagesAnnotations For Symmetric Probabilistic Encryption Algorithm Based On Chaotic Attractors of Neural NetworksvignanarajNo ratings yet
- Gaussian QuadDocument12 pagesGaussian QuadchikukotwalNo ratings yet
- Using R For Linear RegressionDocument9 pagesUsing R For Linear RegressionMohar SenNo ratings yet
- Tpde QB PDFDocument11 pagesTpde QB PDFvignanarajNo ratings yet
- Tutorial Prob AnsDocument4 pagesTutorial Prob AnsvignanarajNo ratings yet
- Tutorial Problems in Numerical MethodsDocument8 pagesTutorial Problems in Numerical MethodsvignanarajNo ratings yet
- Numerical Methods Question BankDocument10 pagesNumerical Methods Question BankvignanarajNo ratings yet
- Willettp 4Document24 pagesWillettp 4vignanarajNo ratings yet
- Numerical Methods For Electrical EngineersDocument12 pagesNumerical Methods For Electrical EngineersvignanarajNo ratings yet
- Computational Intelligence For Big Data Analytics - BDA 2013Document60 pagesComputational Intelligence For Big Data Analytics - BDA 2013vignanarajNo ratings yet
- Fuzzy Set TheoryDocument42 pagesFuzzy Set TheoryKarthikeyan L.MangaNo ratings yet
- Mechanical Engg 2014Document25 pagesMechanical Engg 2014vignanarajNo ratings yet
- LECTURE Notes On Design of ExperimentsDocument31 pagesLECTURE Notes On Design of Experimentsvignanaraj88% (8)
- Lecture Notes Finite DifferencesDocument22 pagesLecture Notes Finite DifferencesvignanarajNo ratings yet
- Numerical Method For Engineers-Chapter 8Document39 pagesNumerical Method For Engineers-Chapter 8Mrbudakbaek83% (12)
- Electromagnetic Theory Lecture NotesDocument125 pagesElectromagnetic Theory Lecture NotesvignanarajNo ratings yet
- LECTURE Notes On Design of ExperimentsDocument31 pagesLECTURE Notes On Design of Experimentsvignanaraj88% (8)
- Numerical Methods in CivilDocument26 pagesNumerical Methods in CivilvignanarajNo ratings yet
- SR Profile July 2014Document6 pagesSR Profile July 2014vignanarajNo ratings yet
- Fourier Series Two Marks QuestionsDocument3 pagesFourier Series Two Marks Questionsvignanaraj100% (1)
- UNIT4 Applications of Partial Differential Equations.286201632Document36 pagesUNIT4 Applications of Partial Differential Equations.286201632Jack AshrafNo ratings yet
- Applications of Systems of Linear EquationsDocument44 pagesApplications of Systems of Linear EquationsGovind Manglani80% (5)
- Graeffe'S Method: 1.find The Positive Root of The FollowingDocument3 pagesGraeffe'S Method: 1.find The Positive Root of The FollowingvignanarajNo ratings yet
- Mean Is Meaningless: Guide For Interpretinng Likert ScaleDocument3 pagesMean Is Meaningless: Guide For Interpretinng Likert ScaleRJ Bedaño100% (1)
- 1 ADocument83 pages1 Abos7213No ratings yet
- Q Q Q Q Q Q Q Q: The Quartiles For Ungrouped DataDocument2 pagesQ Q Q Q Q Q Q Q: The Quartiles For Ungrouped DataReygie FabrigaNo ratings yet
- Module Handbook - Business Statistics IIDocument4 pagesModule Handbook - Business Statistics IIHashini IvoneNo ratings yet
- Stat Chapter 5-9Document32 pagesStat Chapter 5-9asratNo ratings yet
- Outlier DetectionDocument19 pagesOutlier DetectionSavitha VasanthanNo ratings yet
- Analysis of Variance (Anova)Document18 pagesAnalysis of Variance (Anova)princess nicole lugtuNo ratings yet
- Ch02 SolutionDocument38 pagesCh02 SolutionSharif M Mizanur Rahman90% (10)
- Von BertalanffyDocument54 pagesVon BertalanffyCaducas Rocha DuarteNo ratings yet
- Some Definitions: Probability SamplingDocument9 pagesSome Definitions: Probability SamplingEng Mohammed100% (1)
- AP Statistics HW Answer Keys - Unit 1Document4 pagesAP Statistics HW Answer Keys - Unit 1Sunny LeNo ratings yet
- Missing Data & How To Handle ItDocument32 pagesMissing Data & How To Handle ItGuja NagiNo ratings yet
- Biostat Inferential StatisticsDocument62 pagesBiostat Inferential Statisticstsehay asratNo ratings yet
- S1Document5 pagesS1AnkitNo ratings yet
- Pgm6 With OutputDocument6 pagesPgm6 With OutputManojNo ratings yet
- STAT1008 AssignmentDocument10 pagesSTAT1008 AssignmentTerence ChiemNo ratings yet
- Factorial Experiment Two-Way ANOVA: Data Layout: Simultaneous ConclusionsDocument6 pagesFactorial Experiment Two-Way ANOVA: Data Layout: Simultaneous ConclusionsMamtha KumarNo ratings yet
- 7 Steps of Hypothesis TestingDocument3 pages7 Steps of Hypothesis TestingShaira Mae LapazNo ratings yet
- 05 Hypotheses TestingDocument2 pages05 Hypotheses TestingThapaa LilaNo ratings yet
- Estimation of Parameters 2Document125 pagesEstimation of Parameters 2Amierson TilendoNo ratings yet
- Chapter 4 PDFDocument6 pagesChapter 4 PDFPravin C-resthaNo ratings yet
- 05 Class RegressionCorrelationDocument57 pages05 Class RegressionCorrelationJipeeZedNo ratings yet
- Abnormal Stock Returns Associated With Media Disclosures of Subject To Qualified Audit OpinionsDocument25 pagesAbnormal Stock Returns Associated With Media Disclosures of Subject To Qualified Audit OpinionsZhang PeilinNo ratings yet
- Fast Food RestaurantsDocument53 pagesFast Food Restaurantschandanmiddha100% (1)
- Lab 1Document3 pagesLab 1gregNo ratings yet
- LESSON 5 Random SamplingDocument42 pagesLESSON 5 Random SamplingCarbon CopyNo ratings yet
- Comprehensive Statistics MBADocument2 pagesComprehensive Statistics MBAJizel CortezNo ratings yet
- DBB2102 Unit-05Document22 pagesDBB2102 Unit-05Silent KillerNo ratings yet
- Effects of A Neurodevelopmental Treatment Based.3Document13 pagesEffects of A Neurodevelopmental Treatment Based.3ivairmatiasNo ratings yet
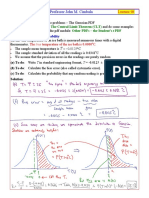
- ME345 Professor John M. Cimbala: The True Temperature of The Ice Bath Is 0.0000 CDocument4 pagesME345 Professor John M. Cimbala: The True Temperature of The Ice Bath Is 0.0000 Crahmid fareziNo ratings yet